作者:琳尐琳安_641 | 来源:互联网 | 2023-10-11 12:53
本文先从整洁架构的角度讲讲慢查询sql完成的功能以及设计,再介绍对sql进行的实施测试现象以及思考。设计讲解一见杨过误终身,有多少萌妹子败给了一个痴字。金庸笔下的痴儿怨女数量之多就
本文先从整洁架构的角度讲讲慢查询sql完成的功能以及设计,再介绍对sql进行的实施测试现象以及思考。
设计讲解
一见杨过误终身,有多少萌妹子败给了一个痴字。金庸笔下的痴儿怨女数量之多就需要单独申请服务器,用独立存储单元进行存储。
先说神雕侠侣的杨过,陆无双和程英两姐妹苦等他16年最终等来了他和小龙女撒了一波狗粮而去;郭芙含怨20多年;完颜萍一生为杨过梦绕魂牵;郭襄做了尼姑;最惨公孙绿萼,为救他而死,用生命换来的解药杨过转身扔进绝情谷底,公孙绿萼在天上看到此情此景也会气的骂娘吧。
再说雪山飞狐的胡斐,出家的袁紫衣;为救他惨死的程灵素……
从领域驱动设计的角度讲,上面都是值对象。今天不讲值对象,讲实体。所以先拉回来。

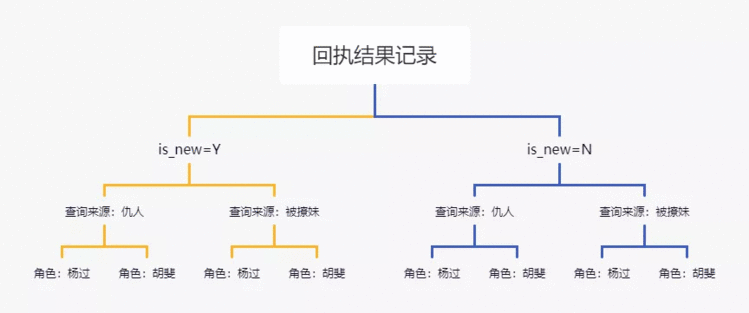
功能简单来说如上图,就是从页面发起查询,查询入口有多个。有个页面是查询角色的仇人,比如杨过的仇人有金轮法王、公孙止、赵志敬……;有个页面是查询角色撩过的妹子,比如杨过撩过的妹子有凌洪波、陆无双、程英……;有些人在几个查询页面都能查到,比如李莫愁既是杨过撩过的妹子,又是杨过的仇人。这里我们把一种页面叫一个请求方。
请求方发起更新查询请求,比如请求方要查询杨过的所有仇人。请求经过转接系统将请求落库后转发到MQ。MQ异步返回包含杨过、胡斐在内的所有仇人的结果。转接系统根据结果反查请求信息,将结果存储。请求方3s后再发起结果查询,这时就会根据请求条件直接返回杨过的所有仇人。这里值得注意的是一次请求返回的结果有的100多条,有的200多条。就是说杨过、胡斐等这些金庸笔下的人物目前仇人列表总数是100多条;杨过、胡斐等这些金庸笔下的人物目前撩过的妹子列表总数是200多条。编辑还在不断录入数据,过一段时间,数据会变化。
功能的设计整体采用整洁架构中的事件溯源的变通方法。对于发起请求,只有增加和查询操作;对于回执结果,因为查询只会查询最新回执。所以一个请求方结果返回后会将所有之前的老数据更新为is_new=N,新插入记录is_new=Y。
回执结果记录数据表设计如下:


问题描述
这个查询系统受到不少人的喜爱,不知不觉间,查询次数过多,事件溯源的设计导致回执结果记录数据表积累了358万条数据。之前没有索引,结果出现一次请求查询20多秒,更新处理直接把数据库拖挂了。
我之前讲解过给is_new加上索引,虽然is_new只有N和Y两个值,总体数据区分度不高,但是对于这种N和Y的值占比是万比一比例,只会查其中少的那部分,却是比普通索引有更高的效率。
问题来了,请求方的查询条件是where is_new=Y and 角色名=杨过 and 查询来源=仇人。我是该建立三个字段联合索引还是两个字段联合索引还是单个索引?
反直觉!经过试验:
1>is_new、角色名、查询来源 三个字段加索引
2>is_new、查询来源两个字段加索引
3>is_new、角色名两个字段加索引
4>is_new单个字段加索引
四种情况sql执行速度在ms级别没有任何差别!几次测试都是6ms返回!而更新时间虽然增加了建索引的时间,反而耗时大大减少!
原理分析
查询时间分析
上面所列的索引添加方式都是索引全中,假设is_new的数据共400多条,某查询来源的数据是一二百条,某角色名大概十几条。B+树底层:
1> is_new、角色名、查询来源 三个字段加索引时索引命中十几条,然后通过主键查到数据返回
2> is_new、查询来源 两个字段加索引时索引命中一二百条,然后扫描这一二百条数据,查到需要的十几条数据返回
3>is_new、角色名 两个字段加索引时索引命中二十几条,然后扫描这二十几条数据,查到需要的十几条数据返回
4>is_new单个字段加索引时索引命中400多条,然后扫描这400多条数据,查到需要的十几条数据返回
之所以单个索引和联合索引查询结果区别不大呢,是因为扫描的数据共400多条,按照数据库的处理能力来说不算什么,这6ms时间主要花在了组装数据和传输数据上。如果查询条件不命中(返回数据条数为0),查询时间几乎为0!
更新时间分析
上面提到每次查询都会把上次结果的is_new更新为N,新数据插入时is_new=Y。所以读写比例为1:1。更新性能就是不能不考虑的问题。当然最重要的是更新操作是数据库被拖挂的罪魁祸首。
update 回执结果记录数据表 set is_new=N where is_new=Y and 查询来源=仇人。
我测试了一下:
1> is_new、角色名、查询来源 三个字段加索引时更新时间90ms。
2> is_new、查询来源 两个字段加索引时更新时间60ms。
3>is_new、角色名 两个字段加索引时更新时间60ms。
4>is_new单个字段加索引时更新时间30ms。
这个更新操作,涉及索引重建。层数越多越慢不难理解。但是为什么时间是几十毫秒级别呢?没建索引之前查询都要20s。原因是B+树是树形结构。示意图如下所示,声明:下面的解释只是针对这个问题一个脑补过程,实际上有很多不严谨的地方。比如B+树还有最底层的叶子节点来存放数据。叶子节点之间有双向链表,与主题无关,没画那么细。
更新操作会首先进行一个查询,is_new=Y,然后会在is_new=Y这个范围内将is_new=Y涉及的一二百条数据,再到is_new=N下面自己的位置进行插入。如果是三层,每层的数据都需要先找自己的位置,最慢。这里面没有画的叶子节点是从左到右按id顺序排序的。如果只有一层is_new=Y的整个直接放到is_new=N下面的最后就可以了,最快。这就解释了四种更新方式的更新时间差异。
但是为什么加了索引和完全不加索引之间有有多于千倍的性能差异呢?更新操作的时间也主要是花在查询上。如果完全不加索引,一二百条数据每条插入前先进行查找,查找要全表扫描,358万条数据,16K为一个内存换页。我就不具体算了,但是要进行很多次内存换页才能查出来。还要乘以数据条数。而加了索引,因为有is_new=Y条件,进行一次内存换页就可以了。因为is_new=Y数据总共就400多条,1个内存页是可以存下的。所以一二百条数据中下一条就不需要内存换页了,查询总共就需要1次内存换页,基本不花什么时间。剩下的就是一条条插入具体位置了。
最终结论
通过上面比较,自然是只加单索引is_new最高效。













 京公网安备 11010802041100号
京公网安备 11010802041100号