问题:
延时任务是指把需要延迟执行的任务叫做延迟任务。 如:
生成订单60秒后,给用户发短信
下单之后15分钟,如果用户不付款就关闭订单
红包 24 小时未被查收,需要延迟执退还业务
解决方式
那么针对于类似这样的任务,一般我们都是怎么处理的呢?
对于这种延时任务,我们一般有以下的4中解决方式:
利用quartz等定时任务
delayQueue
wheelTimer
rabbitMq的延迟队列
redis缓存
1)利用quartz等定时任务
相信目前还有很多的公司依然沿用着这种做法,那么利用quartz怎么解决这个延时任务的问题呢?
具体的方式就是这样的,比如我们有个下单15分钟后用户不付款就关闭订单的任务.我的订单是存储在mysql的一个表里,表里会有各种状态和创建时间.
利用quartz来设定一个定时任务,我们暂时设置为每5分钟扫描一次.扫描的条件为未付款并且当前时间大于创建时间超过15分钟.然后我们再去逐一的操作每一条数据.
优点:简单易用,可以利用quartz的分布式特性轻易的进行横向扩展。
缺点:需要扫表会增加程序负荷、任务执行不够准时。
2)利用jdk自带的delayQueue
上面我们已经说过了用quartz解决这个办法,现在我们这里使用jdk自带的delayQueue.
怎么使用delayQueue呢?
DelayQueue主要用于放置实现了Delay接口的对象,其中的对象只能在其时刻到期时才能从队列中取走。这种队列是有序的,即队头的延迟到期时间最短。如果没有任何延迟到期,那么久不会有任何头元素,并且poll()将返回null(正因为这样,你不能将null放置到这种队列中),也就是说我们只需要把我们需要延迟触发的任务构建完毕放到delayQueue中,然后构建一个消费者不断的去取到期的任务,进行处理就好.
优点:效率高,任务触发时间延迟低。
缺点:复杂度比quartz要高,自己要处理分布式横向扩展的问题,因为数据是放在内存里,需要自己写持久化的备案以达到高可用。
3)利用wheelTimer
netty中的Timer管理,使用了的Hashed time Wheel的模式,Time Wheel翻译为时间轮,是用于实现定时器timer的经典算法。
HashWheelTimer的原理(时间轮算法的原理)如图所示:

时间轮算法的原理:
可以将 HashedWheelTimer 理解为一个 Set[] 数组, 图中每个槽位(slot)表示一个 Set
HashedWheelTimer 有两个重要参数
tickDuration: 每 tick 一次的时间间隔, 每 tick 一次就会到达下一个槽位
ticksPerWheel: 轮中的 slot 数
上图就是一个 ticksPerWheel = 8 的时间轮, 假如说 tickDuration = 100 ms, 则 800ms 可以走完一圈
在 timer.start() 以后, 便开始 tick, 每 tick 一次, timer 会将记录总的 tick 次数 ticks
我们加入一个新的超时任务时, 会根据超时的任务的超时时间与时间轮开始时间算出来它应该在的槽位.
怎么使用WheelTimer呢?
在netty中已经有了时间轮算法的实现HashWheelTimer,HashWheelTimer的使用非常的简单:先new一个HashedWheelTimer,然后调用它的newTimeout方法传递相应的延时任务。
优点:
效率高,根据楼主自己写的测试,在大量高负荷的任务堆积的情况下,HashWheelTimer基本要比delayQueue低上一倍的延迟率.netty中也有了时间轮算法的实现,实现难度低
缺点:
内存占用相对较高,对时间精度要求相对不高.和delayQueue有着相同的问题,自己要处理分布式横向扩展的问题,因为数据是放在内存里,需要自己写持久化的备案以达到高可用。
4)rabbitMq的延迟队列
大家都知道rabbitmq是一个消息队列,同时因为其天然的分布式特性的支持已经极高的消息处理效率深受大家的喜爱.那么大家应该不知道他也是可以用来处理我们的延时任务的.
如何使用rabbitMq的延迟队列
AMQP和RabbitMQ本身没有直接支持延迟队列功能,但是可以通过以下特性模拟出延迟队列的功能。
RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter
lRabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了deadletter,则按照这两个参数重新路由。
结合以上两个特性,就可以模拟出延迟消息的功能
5)redis缓存
利用redis的zset,zset是一个有序集合,每一个元素(member)都关联了一个score,通过score排序来取集合中的值:
添加元素:ZADD key score member [[score member] [score member] …]
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
查询元素score:ZSCORE key member
移除元素:ZREM key member [member …]
# 添加单个元素
redis> ZADD page_rank 10 google.com
(integer) 1
# 添加多个元素
redis> ZADD page_rank 9 baidu.com 8 bing.com
(integer) 2
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
# 查询元素的score值
redis> ZSCORE page_rank bing.com
"8"
# 移除单个元素
redis> ZREM page_rank google.com
(integer) 1
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
那么如何实现呢?我们将订单超时时间戳与订单号分别设置为score和member,系统扫描第一个元素判断是否超时,具体如下图所示:
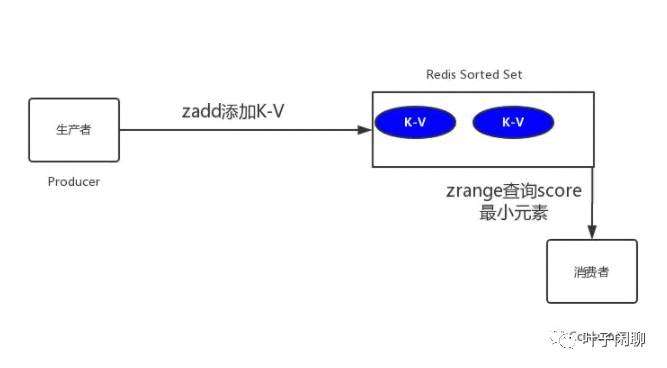
存在问题及解决方法:
在高并发条件下,多消费者会取到同一个订单号。
解决方法:
(1)用分布式锁,但是用分布式锁,性能下降了。
(2)对ZREM的返回值进行判断,只有大于0的时候,才消费数据,于是将consumerDelayMessage()方法里的
优点:
(1)由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2)做集群扩展相当方便
(3)时间准确度高
缺点:
(1)需要额外进行redis维护











 京公网安备 11010802041100号
京公网安备 11010802041100号