目标检测(Object Detection)经典框架论文翻译汇总bigcindy的博客-CSDN博客目标检测的英文
搞懂YOLO v1看这篇就够了_Antrn的博客-CSDN博客
YOLO - Google 幻灯片
说起目标检测系统,就要先明白,图像识别、目标定位和目标检测的区别。图像识别也可以说成是目标分类,顾名思义,目的是为了分类出图像中的物体是什么类别。目标定位是不仅仅要识别出是一种什么物体,还要预测出物体的位置,并使用bounding box框出。目标检测就更为复杂,它可以看作是图像识别+多目标定位,即要在一张图片中定位并分类出多个物体。
目标检测对于人类来说极为简单,经过上万年的进化,人类天生具有复杂的感知与视觉系统,这是机器无可比拟的,我们可以只对图片看一眼,即分辨出物体的种类和它相应的位置,根据先前的知识进行归纳,适应不同图像环境都是人类专属技能。但是对于计算机来说,一张图片只是具有无数RGB像素点的矩阵,它本身并不知道猫狗动物,大小形状的概念,如果再给它一张具有复杂自然场景背景的图片,想要检测出物体更是难上加难。但是是问题,总会有解决的办法。问题是由人类提出来的,当然还要靠人类的智慧来处理。面对这样的计算机难题,很多研究学者蜂拥而至,从此目标检测领域变成了非常热门的研究方向,当然也诞生出了许多的解决方法。
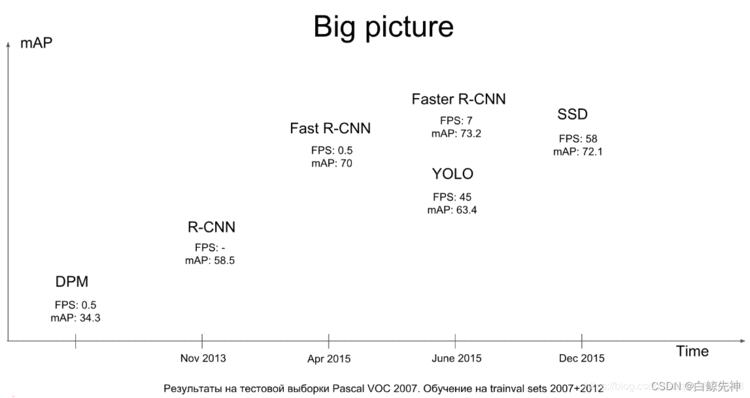
图1.1 2015年之前目标检测方法在Pascal VOC 2007数据集上测试的FPS和mAP结果对比传统的目标检测方法大致分为三个步骤,先使用不同的方法(滑动窗口,区域候选)提取区域的特征图,然后再使用分类器进行识别,最后回归预测。大多数方法都较为复杂,速度较慢,训练耗时。传统的方法可以按照检测系统分为两种:1、DPM,Deformatable Parts Models,采用sliding window检测2、R-CNN、Fast R-CNN。采用region proposal的方法,生成一些可能包含待检测物体的potential bounding box,再通过一个classifier(SVM)判断每个bbox里是否真的包含物体,以及物体的class probability。
目前深度学习相关的目标检测方法大致可以分为两派:1、基于区域提名的(regin proposal)的,比如R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN。2、基于端到端(end to end)的,无需候选区域,如YOLO、SSD。
二者发展都很迅速,区域提名准确率较好、端到端的方法速度较快。
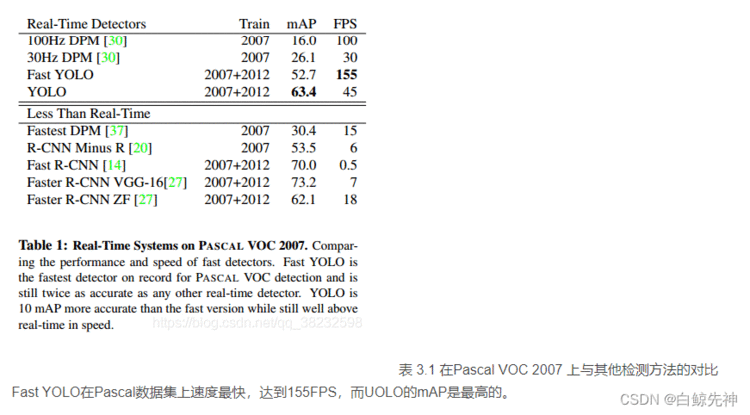
YOLO为一种新的目标检测方法,该方法的特点是实现快速检测的同时还达到较高的准确率。作者将目标检测任务看作目标区域预测和类别预测的回归问题。该方法采用单个神经网络直接预测物品边界和类别概率,实现端到端的物品检测。同时,该方法检测速非常快,基础版可以达到45帧/s的实时检测;FastYOLO可以达到155帧/s。与当前最好系统相比,YOLO目标区域定位误差更大,但是背景预测的假阳性优于当前最好的方法。
改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回归,但建议框之间有重叠,这会带来很多重复工作。YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。

如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-cNN算法。

上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
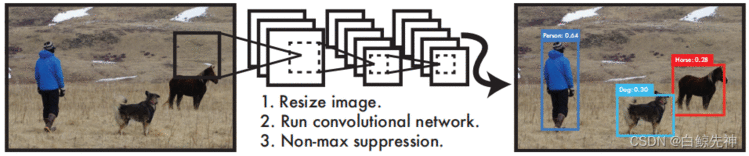
将整张图片作为网络的输入,直接在输出层对bounding box的位置和所属类别进行回归。与Faster R-CNN网络相比,虽然后者也是使用整张图片作为输入,但是它采用了RCNN那种区域预测+分类的思想,把提取proposal的步骤放在了CNN中实现,而YOLO则采用直接回归的思路,将目标定位和目标类别预测整合于在单个神经网络模型中,直接在输出层回归bbox的位置和所属类别。
按照 YOLO:Unified,Real-Time Object Detection 中所说,YOLO检测系统简单直接,可以看做只有三步:
YOLO检测系统先将输入图像调整到448×448;
在图像上运行卷积网络;
通过模型的置信度对结果进行阈值。

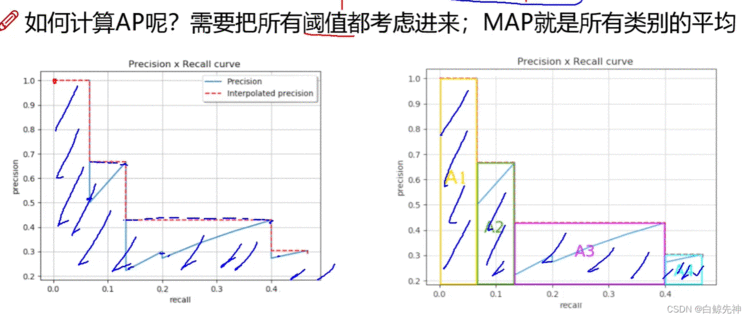
map指标:综合衡量检测效果;但看精度和recall不行吗?
IOU:IOU=Area of overlap / Area of union






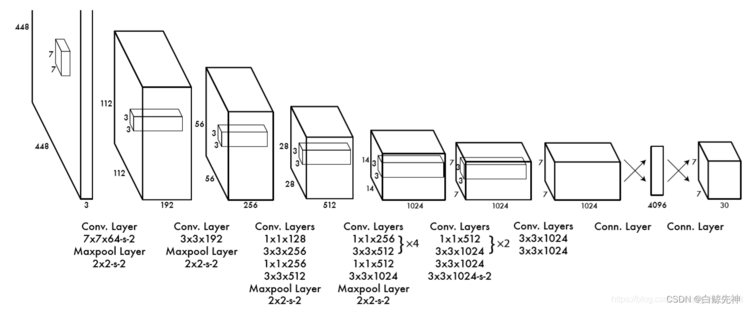

YOLO使用了24个级联卷积层和最后2个全连接层,交替的1×1卷积层降低了前面层的特征空间。在ImageNet分类任务上使用分辨率的一半(224×224输入图像)对卷积层进行预训练,然后将分辨率加倍进行目标检测。Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图8所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x,0.1x)max(x,0.1x)。但是最后一层却采用线性激活函数。除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。
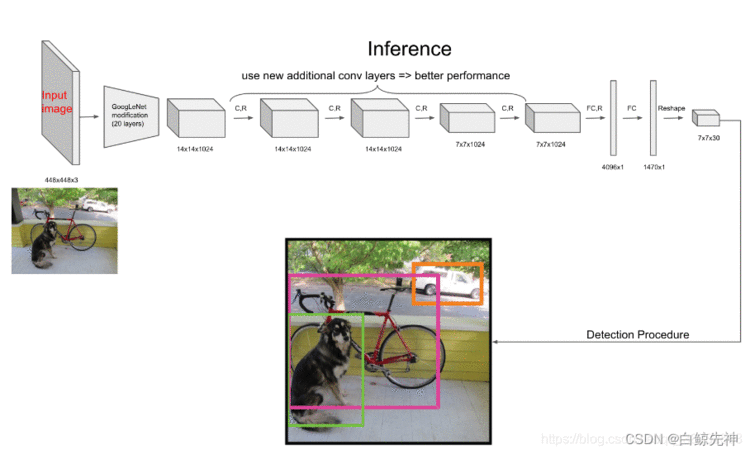
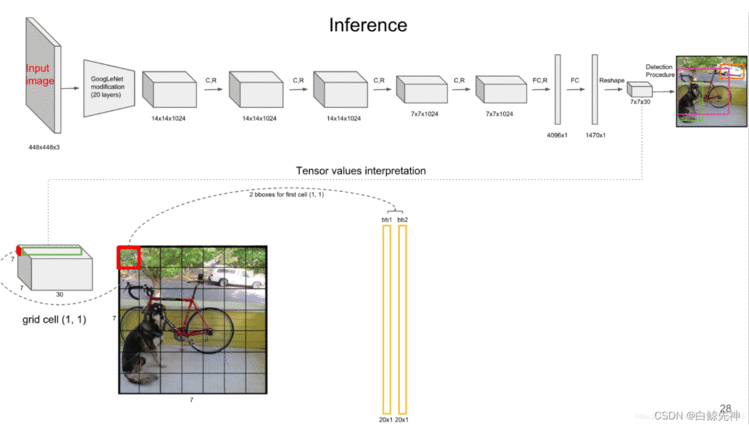
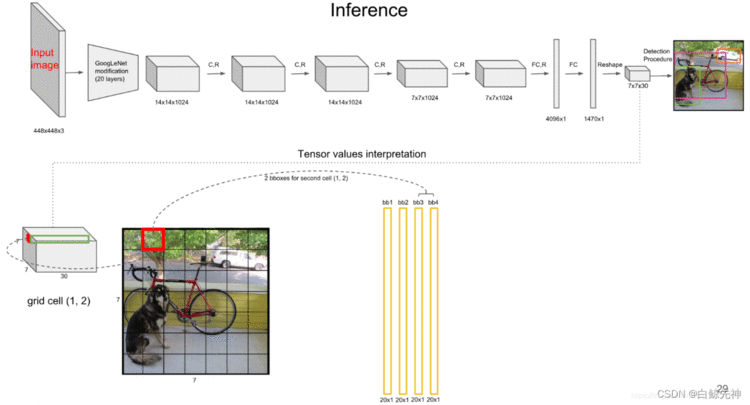
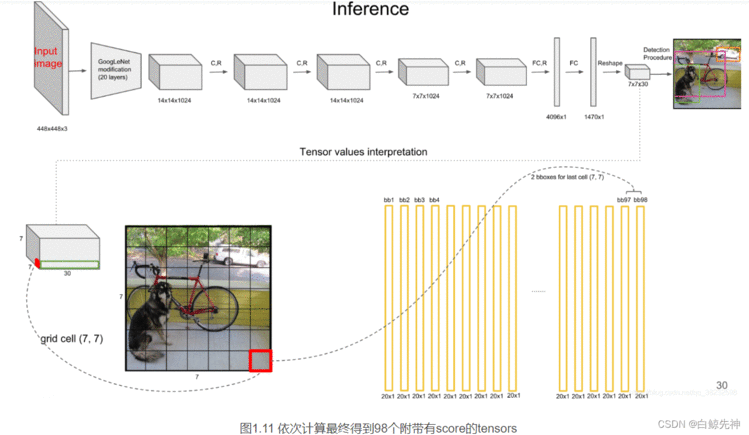
YOLO网络借鉴了GoogleNet的思想,但与之不同的是,为了更好的性能,它增加额外的4层卷积层(conv)。YOLO一共使用了24个级联的卷积层和2个全连接层(fc),其中conv层中包含了1×1和3×3两种kernel,最后一个fc全连接层后经过reshape之后就是YOLO网络的输出,是长度为S×S×(B×5+C)=7×7×30的tensor,最后经过识别过程得到最终的检测结果。
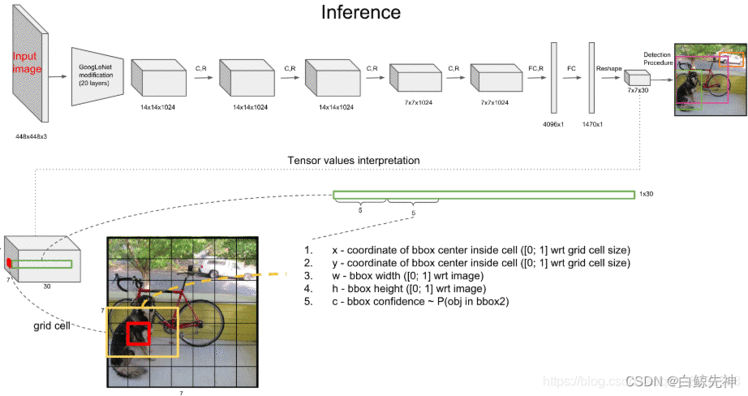
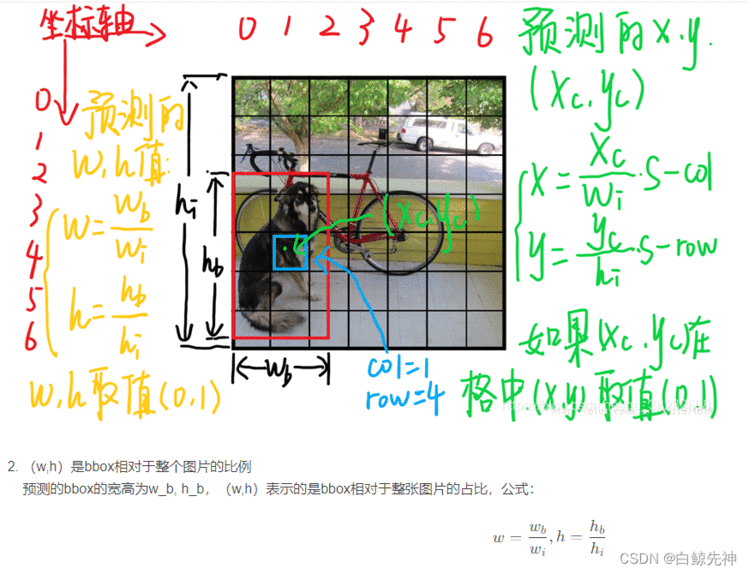
上文说到每个bounding box要预测(x,y,w,h,confidence)五个值,一张图片共分为S×S个网格,每个网格要预测出B个bounding box和一个网格负责的object的类别信息,记为C。则输出为S ∗ S ∗ ( 5 ∗ B + C ) S*S*(5*B+C)S∗S∗(5∗B+C)的tensor张量,(x,y)表示bounding box相对于网格单元的边界的offset,归一化到(0,1)范围之内,而w,h表示相对于整个图片的预测宽和高,也被归一化到(0,1)范围内。c代表的是object在某个bounding box的confidence。这里面的30位分别有不同的含义,前五个是第一个bounding box的坐标和宽高以及置信度,中间五个是第二个bounding box的五个数据,最后的20个是所有的类别的条件概率。把bounding box的条件概率和置信度进行相乘,得到的结果就是全概率,就是说:包含该物品的概率*在包涵物品的概率下各个类别的概率,就得到了他真正是哪个类别的概率,不再是条件概率,一共是两个置信框,所以就有两个全概率。
最后一层预测类别概率和边界框坐标。我们通过图像宽度和高度来归一化边界框的宽度和高度,使它们落在0和1之间。我们将边界框x和y坐标参数化为特定网格单元位置的偏移量,所以它们边界也在0和1之间。我们对最后一层使用线性激活函数,所有其它层使用下面的leaky ReLU激活函数:
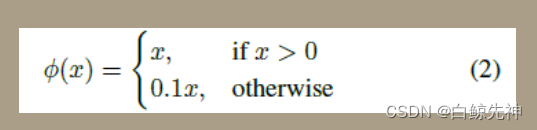


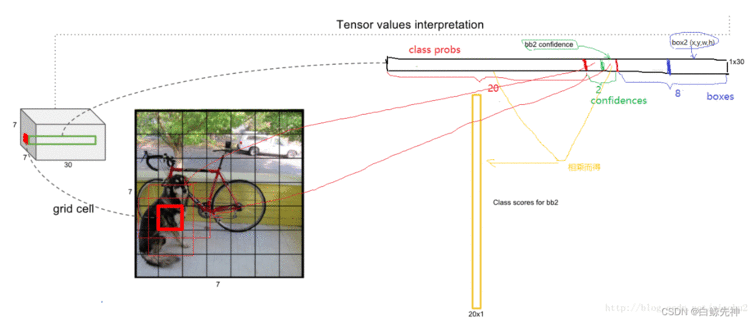

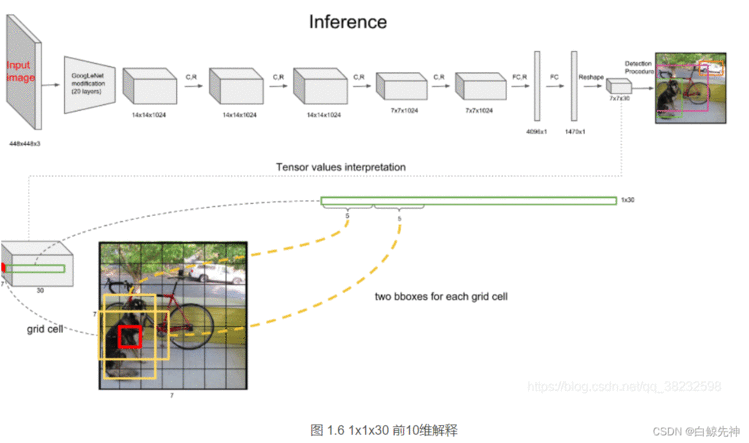
每个grid cell对应的两个bounding box的5个值在tensor中体现出来,组成前十维。每个单元格负责预测一个object,但是每个单元格预测出2个bounding box,如图。
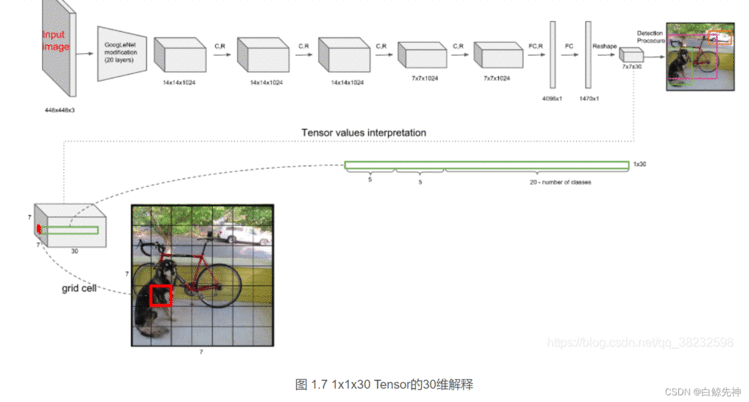
每个grid cell有30维,其中8维是两个预测回归bboxes的坐标信息,2维是bboxes的confidences,还有20维是与类别相关的信息。
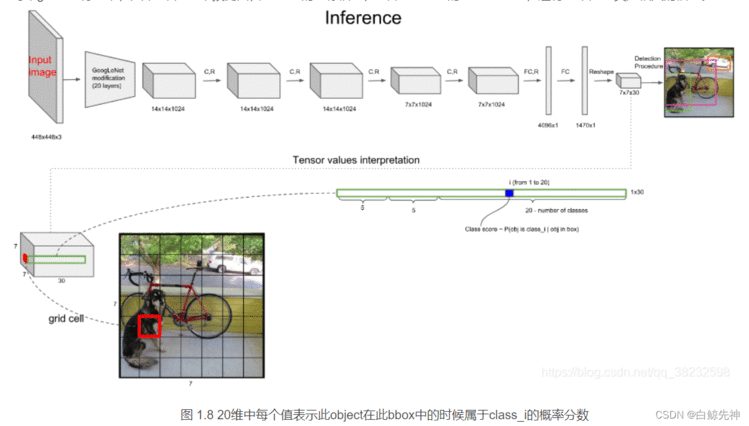


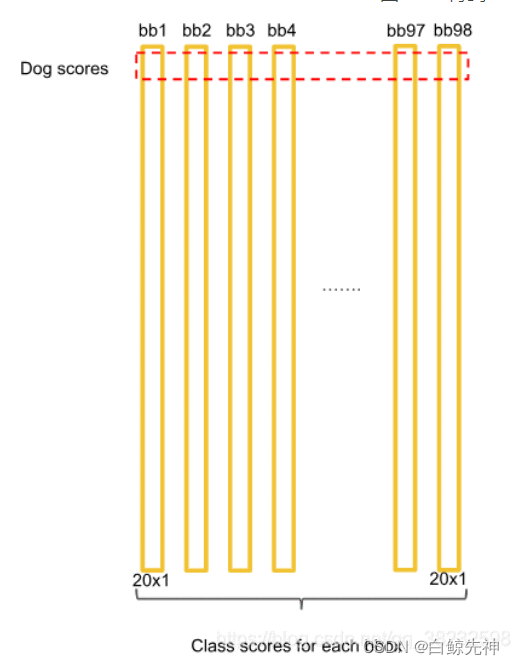
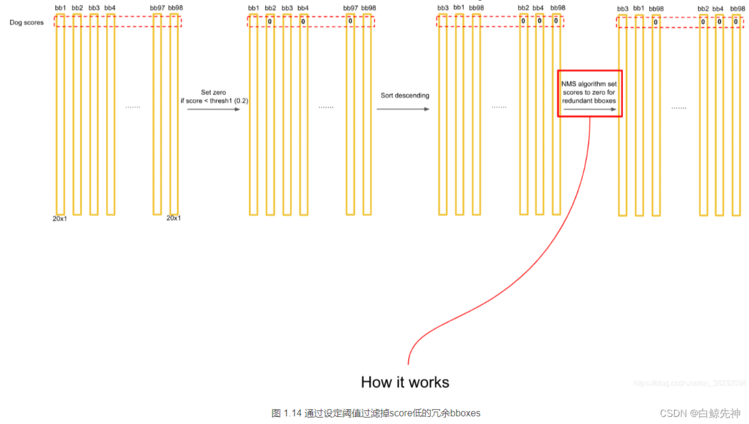


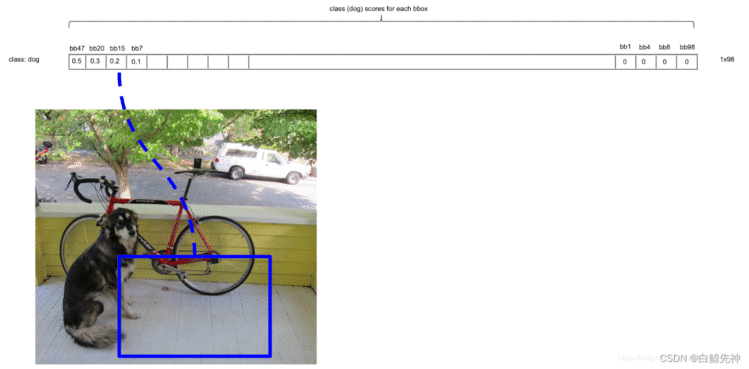

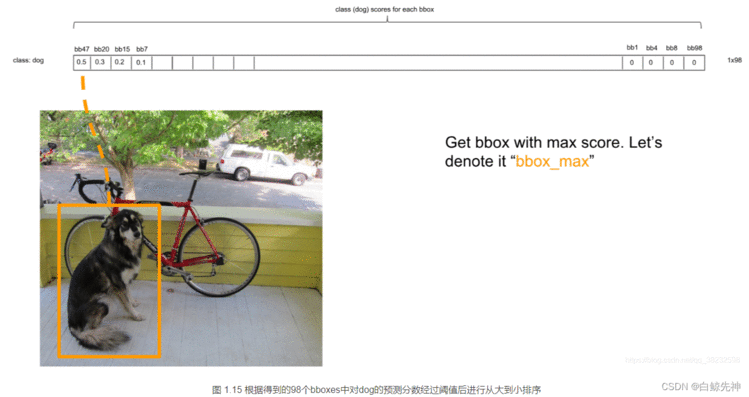
这里需要说明的是:最后得到第一个为最大的score值,找出针对dog这个种类预测出的对应框,记为bbox_max。然后将它与其他分数较低的但不是0的框作对比,这种框记为bbox_cur。将bbox_max和bbox_cur分别做IoU计算,如果 IoU(bbox_max, bbox_cur) > 0.5,那么将bbox_cur对应的score设为0。例如:然后接着遍历下一个score,如果它不是最大的且不为0,就和最大的score对应的框座IoU运算,若结果大于0.5则,同上。否则它的score不变,继续处理下一个bbox_cur……直到最后一个score,如图:这里也就是说:循环的两两进行比较,如果两者的IOU大于某个阈值,就认为这两个识别了同一个目标,就把低概率的过滤掉,也就是置为0。NMS非极大值抑制计算完一轮之后,假如得到score序列:0.5、0、0.2、0.1 … 0、0、0、0那么进行下一轮循环,从0.2开始,将0.2对应的框作为bbox_max,继续循环计算后面的bbox_cur与新的bbox_max的IoU值,大于0.5的设为0,小于0.5的score不变。再这样一直计算比较到最后一个score。得到新的的score序列为:0.5、0、0.2、0 … 0、0、0、0即最后只得到两个score不为0的框,如图:
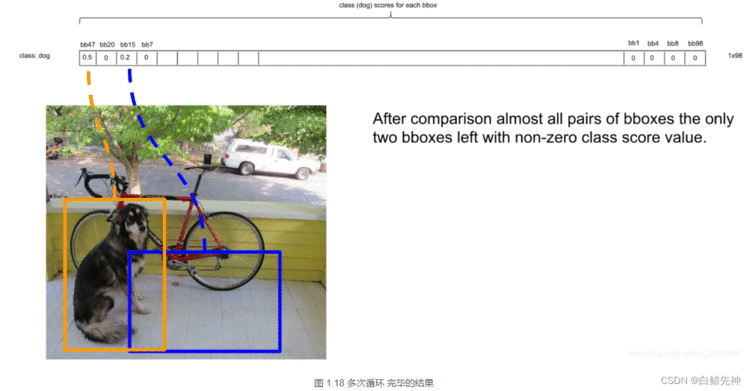
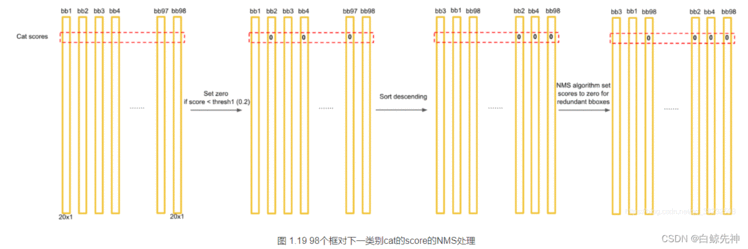

经过这些NMS算法的处理,会出现很多框针对某个class的预测的score为0的情况。
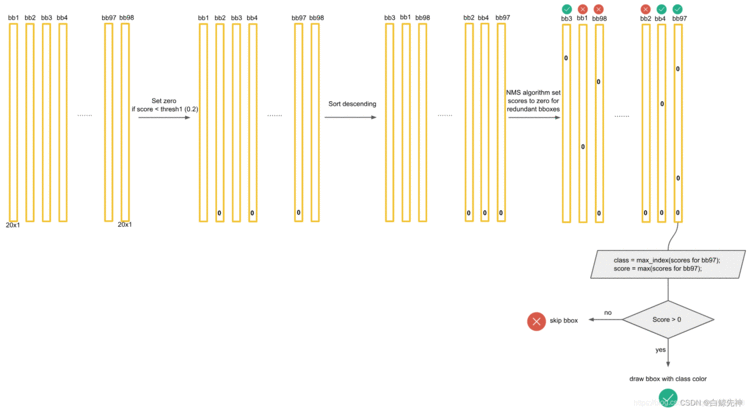
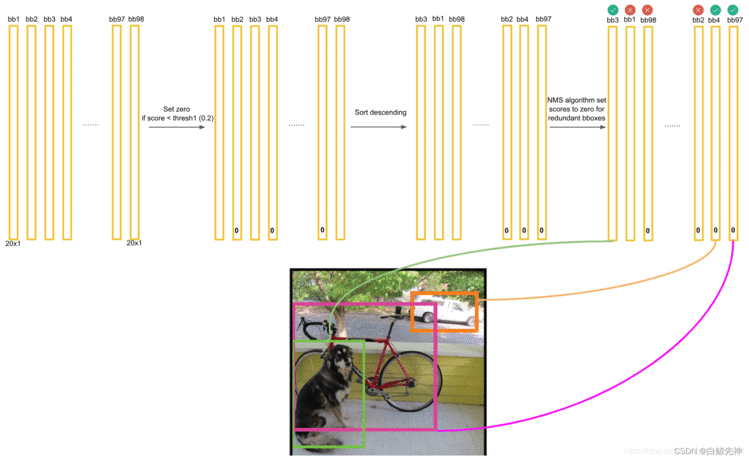
最后,针对每个bbox的20×1的张量,对20种class的预测score进行判断。例如,1)先取出针对bbox3的所有20个scores,按照类别的默认顺序找出score最大的那个score的index索引号(根据此index可以找出所属的类别)记为class;2)然后找出bbox3的最大score分数,记为score。3)判断score是否大于0,如果是,就在图像中画出标有class的框。否则,丢弃此bbox。如图:接下来进行下一个bbox的筛选,如图,则是bbox1,流程同上。一直到最后一个bbox97,

Loss = λcoord * 坐标预测误差(1) + 含object的box confidence预测误差 (2)+ λnoobj* 不含object的box confidence预测误差(3) + 每个格子中类别预测误差(4)YOLO是把目标检测问题当作回归问题。
第一项是负责检测物体的bbox中心点定位的误差(带上标的是标注值,不带的是预测值),第二项是:负责检测物体的bbox宽高定位误差(求根号是为了使得小框对于误差更加的敏感),第三项是:负责检测物体的bbox的confidence(置信度)的误差,标签值就是bbox和ground truth IOU作为他的标签值,第四项是:不负责检测物体的置信度误差,第五项是:负责检测物体的grid cell分类的误差。在此损失函数中,只有某个网格中有object的中心落入的时候才对classification loss进行惩罚。只有当某个网格i中的bbox对某的ground-truth box负责的时候,才会对box的coordinate error进行惩罚。哪个bbox对ground-truth box负责就看ground-truth box和bbox的IoU最大。

3.1.1、在Pascal VOC 2007上的
3.1.2、VOC 2007错误分析
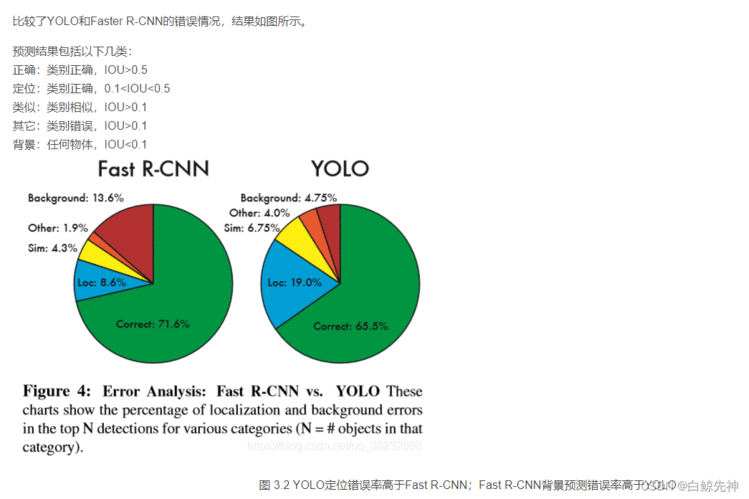

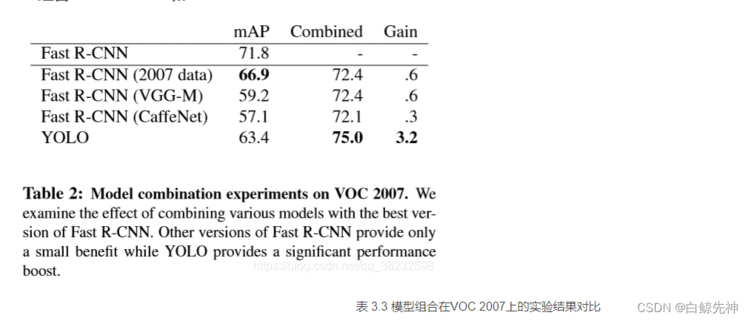
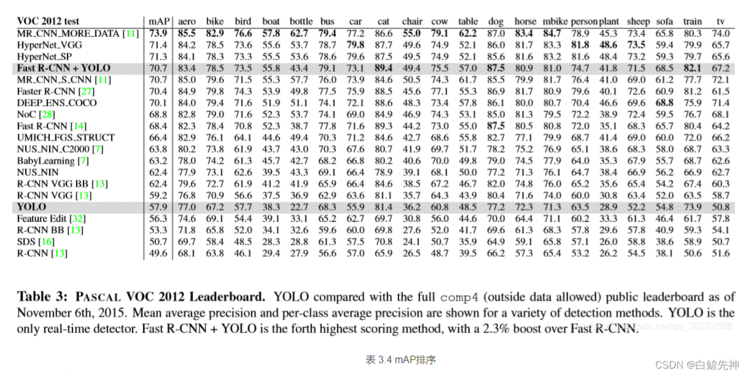
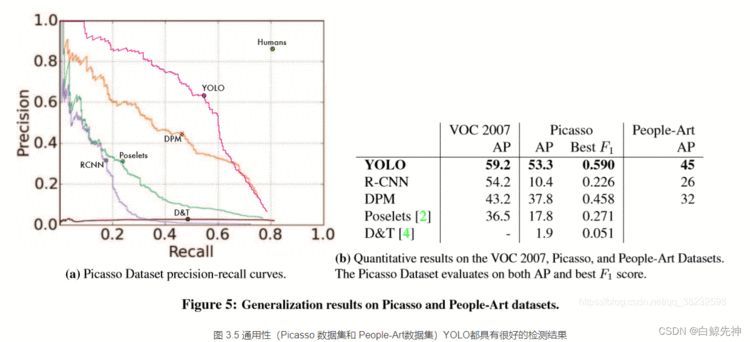
假阳性(FP)错误率低。YOLO网络将整个图像的全部信息作为上下文,在训练的过程中使用到了全图信息,能够更好的区分目标个背景区域。端到端(end-to-end)的方法,速度快,如官网所说,具有实时性,45fps,在YOLO-tiny上可以达到155fps。通用性强,可以学到物体的generalizable-representation。对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
性能表现比当前最先进的目标检测技术低。定位准确性差,对于小目标或者密集型群体object的定位效果不好。虽然每个格子可以预测出B个bounding box,但是最终只选择一个score最高的作为输出,即每个格子最多只得出一个box,如果多个物体的中心落在同一个格子,那么最终可能只预测出一个object。YOLO的loss函数中,大物体的IoU误差和小物体的IoU的误差对训练中的loss贡献值接近,造成定位不准确。作者采用了一个去平方根的方式,但还不是最好的解决方法。输入尺寸固定。由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其他分辨率需要缩放成此固定分辨率大小。采用了多个下采样层,网络学到的物体特征并不精细,因此对检测效果会有影响。
性能表现比当前最先进的目标检测技术低。
定位准确性差,对于小目标或者密集型群体object的定位效果不好。虽然每个格子可以预测出B个bounding box,但是最终只选择一个score最高的作为输出,即每个格子最多只得出一个box,如果多个物体的中心落在同一个格子,那么最终可能只预测出一个object。YOLO的loss函数中,大物体的IoU误差和小物体的IoU的误差对训练中的loss贡献值接近,造成定位不准确。作者采用了一个去平方根的方式,但还不是最好的解决方法。输入尺寸固定。由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其他分辨率需要缩放成此固定分辨率大小。采用了多个下采样层,网络学到的物体特征并不精细,因此对检测效果会有影响。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有