Spark On Yarn
在YARN上启动Spark应用有两种模式。在cluster模式下,Spark驱动器(driver)在YARN Application Master中运行(运行于集群中),因此客户端可以在Spark应用启动之后关闭退出。而client模式下,Spark驱动器在客户端进程中,这时的YARN Application Master只用于向YARN申请资源。
1 cluster运行
运行命令
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]# 示例
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
--jars my-other-jar.jar,my-other-other-jar.jar \
lib/spark-examples*.jar \app_arg1 app_arg212345678910111213
执行步骤
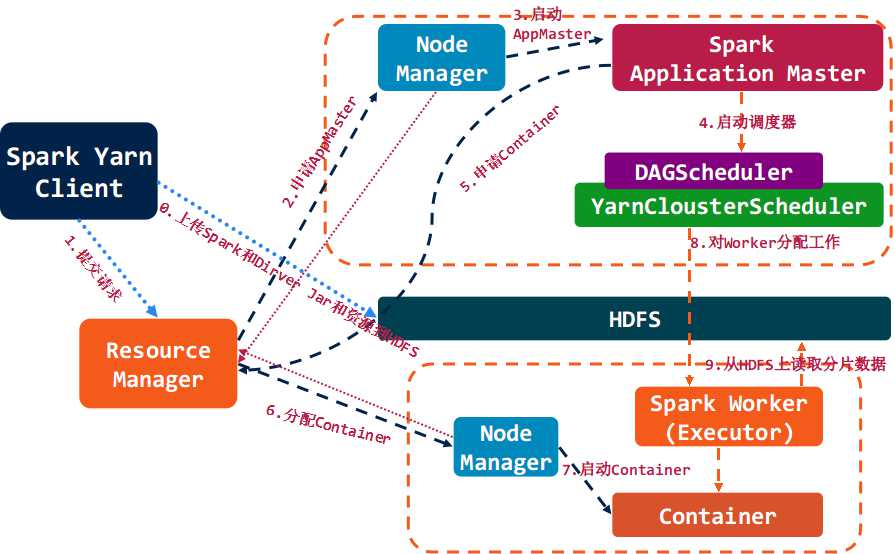
3.2.2 client运行
执行命令
.- -- ---
优化
基于两方面优化:调度器和内存配置。
调度器
根据业务需要选择fair或capacity调度器。同时根据节点物理资源(性能)的高低,可以打标签,例如高配置节点、低配置节点和一般节点。
内存优化
依照以下属性计算推荐的配置
- RAM(Amount of memory)总内存数
- CORES(Number of CPU cores)CPU内核数
- DISKS(Number of disks)硬盘数
| 每个节点的总内存 | 系统内存 | HBase内存 |
|---|
| 4G | 1G | 1G |
| 8G | 2G | 1G |
| 16G | 2G | 2G |
| 24G | 4G | 4G |
| 48G | 6G | 8G |
| 64G | 8G | 8G |
| 72G | 8G | 8G |
| 96G | 12G | 16G |
| 128G | 24G | 24G |
| 256G | 32G | 32G |
| 512G | 64G | 64G |
Container的最大数计算方式:
min (2*CORES, 1.8*DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)1
其中MIN_CONTAINER_SIZE是容器的最小内存,可以根据下表获得
| 每个节点的总内存 | 容器最小内存的推荐值 |
|---|
| 小于4G | 256M |
| 4~8G | 512M |
| 8~24G | 1024M |
| 大于24G | 2048M |
最终容器的内存由下式计算获得:
RAM-per-Container = max (MIN_CONTAINER_SIZE, (Total Available RAM) / Containers))1
最后YARN和MR的配置为:
| 配置文件 | 属性 | 值 |
|---|
| yarn-site.xml | yarn.nodemanager.resource.memory-mb | Containers * RAM-per-Container |
| yarn-site.xml | yarn.scheduler.minimum-allocation-mb | RAM-per-Container |
| yarn-site.xml | yarn.scheduler.maximum-allocation-mb | containers * RAM-per-Container |
| mapred-site.xml | mapreduce.map.memory.mb | RAM-per-Container |
| mapred-site.xml | mapreduce.reduce.memory.mb | 2 * RAM-per-Container |
| mapred-site.xml | mapreduce.map.java.opts | 0.8 * RAM-per-Container |
| mapred-site.xml | mapreduce.reduce.java.opts | 0.8 * 2 * RAM-per-Container |
| yarn-site.xml (check) | yarn.app.mapreduce.am.resource.mb | 2 * RAM-per-Container |
| yarn-site.xml (check) | yarn.app.mapreduce.am.command-opts | 0.8 * 2 * RAM-per-Container |
例如:
集群节点是12核CPU、48G和12块硬盘
保留内存 = 6 GB 系统使用 + (如果有HBase) 8 GB HBase使用
容器最小内存 = 2 GB
无HBase
容器数 = min (2 * 12, 1.8 * 12, (48-6)/2) = min (24, 21.6, 21) = 21
每个容器的内存 = max (2, (48-6)/21) = max (2, 2) = 2
| 属性 | 值 |
|---|
| yarn.nodemanager.resource.memory-mb | = 21 * 2 = 42 * 1024 MB |
| yarn.scheduler.minimum-allocation-mb | = 2 * 1024 MB |
| yarn.scheduler.maximum-allocation-mb | = 21 * 2 = 42 * 1024 MB |
| mapreduce.map.memory.mb | = 2 * 1024 MB |
| mapreduce.reduce.memory.mb | = 2 * 2 = 4 * 1024 MB |
| mapreduce.map.java.opts | = 0.8 * 2 = 1.6 * 1024 MB |
| mapreduce.reduce.java.opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
| yarn.app.mapreduce.am.resource.mb | = 2 * 2 = 4 * 1024 MB |
| yarn.app.mapreduce.am.command-opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
有HBase
容器数 = min (2 * 12, 1.8 * 12, (48-6-8)/2) = min (24, 21.6, 17) = 17
每个容器的内存 = max (2, (48-6-8)/17) = max (2, 2) = 2
| 属性 | 值 |
|---|
| yarn.nodemanager.resource.memory-mb | = 17 * 2 = 34 * 1024 MB |
| yarn.scheduler.minimum-allocation-mb | = 2 * 1024 MB |
| yarn.scheduler.maximum-allocation-mb | = 17 * 2 = 34 * 1024 MB |
| mapreduce.map.memory.mb | = 2 * 1024 MB |
| mapreduce.reduce.memory.mb | = 2 * 2 = 4 * 1024 MB |
| mapreduce.map.java.opts | = 0.8 * 2 = 1.6 * 1024 MB |
| mapreduce.reduce.java.opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
| yarn.app.mapreduce.am.resource.mb | = 2 * 2 = 4 * 1024 MB |
| yarn.app.mapreduce.am.command-opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |











 京公网安备 11010802041100号
京公网安备 11010802041100号