前陣子在研究跟 HTTP Cache 有關的一些東西,看得眼花撩亂,不同的 Header 愈看愈混亂,像是 Pragma , Cache-Control , Etag , Last-Modified , Expires 等等。找了許多參考資料閱讀之後才有了比較深刻的理解,想說若是從一個比較不同的角度來理解 Cache,說不定會比較容易了解這些 Header 到底在做什麼。
在之前查的資料裡面,很多篇都是逐一解釋各個 Header 的作用以及參數,而我認為其實參數講多了容易造成初學者混淆,想說怎麼有這麼多奇怪的參數,而且每一個看起來都很像。所以這篇文章嘗試一步一步藉由不同的問題來引導出各個 Header 使用的場景以及出現的目的。還有,因為這篇是給初學者看的,所以不會講到所有的參數。
其實關於 Cache 這一部分,很多網路資源的說法都不太一樣,如果碰到有疑義的地方我會盡量以 RFC 上面寫的標準為主。如果有錯誤的話還麻煩不吝指正,感謝。
多問為什麼是個好習慣,在你用一個東西之前,必須知道你為什麼要用它。於是,我們需要問自己一個問題:為什麼需要 Cache?
很簡單,因為節省流量嘛,也節省時間,或是更宏觀地來說,減少資源的損耗。
舉例來說,今天電商網站的首頁可能會有很多商品,如果你今天每一個訪客到首頁你都去資料庫重新抓一次所有的資料,那對資料庫的負擔會非常非常大。
可是呢,其實首頁的這些資訊基本上短期之內是不會變的,一個商品的價格不可能上一秒是一千元,下一秒就變成兩千元。所以這些不常變動的資料就很適合儲存起來,也就是我們說的 Cache,台灣翻譯叫做快取,中國翻譯叫做緩存。其實仔細想想,這兩個翻譯根本就是 Cache 的兩面:快速存取跟緩慢儲存(這邊的緩慢指的是可以存很久的意思)。
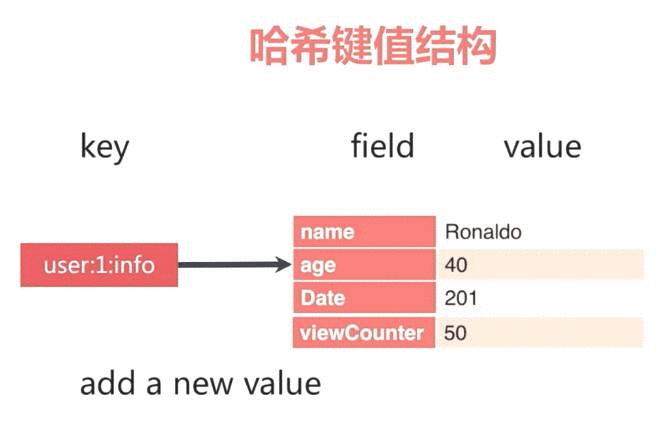
上面這個例子可以把首頁的那些資訊在撈出來一次之後就存在某個地方,例如說 Redis,其實就是以一個簡單的 Key Value Pair 的形式存進去即可,接著只要是用到這些資訊的時候,都可以用極快的速度撈出來,而不是再到資料庫裡面重新算一次。
上面講的是 Server side 的 Cache,藉由把 Database 的資料撈出來之後存到別的地方達成。但 Server side 的 Cache 並不是我們今天的重點,有興趣的讀者們可以參考我之前寫過的: 資料庫的好夥伴:Redis 。
今天的重點是 Server 跟瀏覽器之間的 Cache 機制。
例如說電商網站的商品圖好了。如果沒有 Cache 的話,那首頁出現的上百張商品圖,只要網頁被瀏覽幾次,就會被下載幾次,這個流量是非常驚人的。所以我們必須讓瀏覽器可以把這些圖片給 Cache 起來。這樣只有第一次瀏覽這個網頁的時候需要重新下載,第二次瀏覽的時候,圖片就可以直接從瀏覽器的快取裡面去抓,不用再跟 Server 拿資料了。
要達成上述的功能,可以在 HTTP Response Header 裡面加上一個 Expires 的字段,裡面就是這個 Cache 到期的時間,例如說:
Expires: Wed, 21 Oct 2017 07:28:00 GMT
瀏覽器收到這個 Response 之後就會把這個資源給快取起來,當下一次使用者再度造訪這個頁面或是要求這個圖片的資源的時候,瀏覽器會檢視「現在的時間」是否有超過這個 Expires。如果沒有超過的話,那瀏覽器「不會發送任何 Request」,而是直接從電腦裡面已經存好的 Cache 拿資料。
若是打開 Chrome dev tool,就會看到它寫著:「Status code 200 (from disk cache)」,代表這個 Request 其實沒有發出去,Response 是直接從 disk cache 裡面拿的。

可是這樣其實會碰到一個問題,因為瀏覽器檢視這個 Expires 的時間是用「電腦本身的時間」,那如果我喜歡活在未來,把電腦的時間改成 2100 年,會怎樣呢?
瀏覽器就會覺得所有的 Cache 都是過期的,就會重新發送 Request。
Expires 其實是 HTTP 1.0 就存在的 Header,而為了解決上面 Expires 會碰到的問題,HTTP 1.1 有一個新的 header 出現了,叫做: Cache-Control 。(註:Cache-Control 是 HTTP 1.1 出現的 Header,但其實不單單只是解決這個問題,還解決許多 HTTP 1.0 沒辦法處理的快取相關問題)
其中一種用法是: Cache-Control: max-age=30 ,就代表這個 Response 的過期時間是 30 秒。假設使用者在收到這個 Response 之後的第 10 秒重新整理,那就會出現上面那樣被瀏覽器 Cache 住的現象。
但假如使用者是過 60 秒之後才重新整理,瀏覽器就會發送新的 Request。

仔細觀察 Google Logo 檔案的 Response header,你會發現它的 max-age 設定成 31536000 秒,也就是 365 天的意思。只要你在一年之內造訪這個網站,都不會對 Google logo 這張圖片送出 Request,而是會直接使用瀏覽器已經快取住的 Response,也就是這邊寫的 Status code 200 (from memory cache) 。
現在就碰到一個問題了,既然 Expires 跟 max-age 都可以決定一個 Response 是否過期,那如果兩個同時出現,瀏覽器要看哪一個呢?
根據 RFC2616 的定義:
If a response includes both an Expires header and a max-age directive, the max-age directive overrides the Expires header, even if the Expires header is more restrictive
max-age 會蓋過 Expires 。因此現在的快取儘管兩個都會放,但其實真正會用到的是 max-age 。
上面這兩個 Header 都是在關注一個 Response 的「新鮮度(freshness)」,如果 Response 夠新鮮的話(也就是還沒超過 Expire 或者是在 max-age 規定的期限裡面),就直接從快取裡面拿資料。如果過期了、不新鮮了,就發送 Request 去跟 Server 拿新的資料。
但是這邊要特別注意一點:「過期了不代表不能用」
這是什麼意思呢?剛剛有提到說 Google 的 Logo 快取時間是一年,一年之後瀏覽器就會重新發出 Request 對吧?可是很有可能 Google 的 Logo 在一年之後也不會換,代表其實瀏覽器快取起來的圖片還是可以用的。
如果是這種情況,那 Server 就不必返回新的圖片,只要跟瀏覽器說:「你快取的圖片可以繼續用一年喔」就可以了。
想要做到上面的功能,必須要 Server 跟 Client 兩邊互相配合才行。其中一種做法就是使用 HTTP 1.0 就有的: Last-Modified 與 If-Modified-Since 的搭配使用。
在 Server 傳送 Response 的時候,可以多加一個 Last-Modified 的 Header,表示這個檔案上一次更改是什麼時候。而當快取過期,瀏覽器下次再發送 Request 的時候,就可以利用這個資訊,改用 If-Modified-Since 來跟 Server 指定拿取:某個時間點以後有更改的資料。
直接舉一個例子吧,假設我要求 Google 首頁的圖片檔案,收到了這樣的 Response(為了方便閱讀,日期的格式有更改過,實際上的內容不會是這樣):
Last-Modified: 2017-01-01 13:00:00 Cache-Control: max-age=31536000
瀏覽器收到之後就會把這張圖片存進快取,並且標明這個檔案的最後更新時間是: 2017-01-01 13:00:00 ,過期時間是一年後。
如果在半年後我重新請求這張圖片,瀏覽器就會跟我說:「你不用重新請求喔,這一份檔案的過期時間是一年,現在才過了半年。你要資料是吧?我這邊就有囉!」,於是就不會發送任何 Request,而是直接從瀏覽器那邊獲得資料。
接著我在過了一年之後再請求一次這張圖片,瀏覽器就會說:「嗯嗯,我這邊的快取的確過期了,我幫你去 Server 問一下檔案從 2017-01-01 13:00:00 以後有沒有更新」,會發送出下面這樣的 Request:
GET /logo.png If-Modified-Since: 2017-01-01 13:00:00
假設檔案確實更新了,那瀏覽器就會收到一份新的檔案。如果新的檔案一樣有那些 Cache 的 Header,就一樣會快取起來,跟上面的流程都一樣。那假設檔案沒有更新呢?
假設沒有更新的話,Server 就會回一個 Status code: 304 (Not Modified) ,代表你可以繼續沿用快取的這份檔案。

雖然上面的這個方法看起來已經很好了,但還是有一個小問題。
上面講的是檔案有沒有被「編輯」過,但其實這個編輯時間就是你電腦上檔案的編輯時間。若是你打開檔案什麼都不做,然後存檔,這個編輯時間也會被更新。可是儘管編輯時間不一樣,檔案的內容還是一模一樣的。
比起編輯時間,若是能用「檔案內容更動與否」來當作是否要更新快取的條件,那是再好不過了。
而 Etag 這個 Header 就是這樣的一個東西。你可以把 Etag 想成是這份檔案內容的 hash 值(但其實不是,但原理類似就是了,總之就是一樣的內容會產生一樣的 hash,不一樣的會產生不一樣的 hash)。
在 Response 裡面 Server 會帶上這個檔案的 Etag,等快取過期之後,瀏覽器就可以拿這個 Etag 去問說檔案是不是有被更動過。
Etag 跟 If-None-Match 也是搭配使用的一對,就像 Last-Modified 跟 If-Modified-Since 一樣。
Server 在回傳 Response 的時候帶上 Etag 表示這個檔案獨有的 hash,快取過期後瀏覽器發送 If-None-Match 詢問 Server 是否有新的資料(不符合這個 Etag 的資料),有的話就回傳新的,沒有的話就只要回傳 304 就好了。
流程可以參考 Google 網站上的下圖:
 (圖片來源: https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/images/http-cache-control.png?hl=zh-tw)
(圖片來源: https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/images/http-cache-control.png?hl=zh-tw)
讓我們來總結一下到目前為止學到的東西:
Expires 跟 Cache-Control: max-age 決定這份快取的「新鮮度」,也就是什麼時候「過期」。在過期之前,瀏覽器「不會」發送出任何 Request If-Modified-Since 或是 If-None-Match 詢問 Server 有沒有新的資源,如果有的話就回傳新的,沒有的話就回傳 Status code 304,代表快取裡面的資源還能繼續沿用。 有了這幾個 Header 之後,世界看似美好,好像所有的問題都解決了一樣。
是的,我說「好像」,代表其實還有一些問題存在。
有一些頁面可能會不想要任何的快取,例如說含有一些機密資料的頁面,就不希望任何的東西被保留在 Client 端。
還記得我們一開始有提過 Cache-Control 這個 Header 其實解決了更多問題嗎?除了可以指定 max-age 以外,可以直接使用: Cache-Control: no-store ,代表說:「我就是不要任何快取」。
因此每一次請求都必定會到達 Server 去要求新的資料,不會有任何資訊被快取住。
(註:HTTP 1.0 裡面有一個 Pragma 的 Header,使用方法只有一種,就是: Pragma: no-cache ,有網路上的資料說它就是不要任何快取的意思,但根據 RFC7232 的說法,這個用法應該跟 Cache-Control: no-cache 一樣,而不是 Cache-Control: no-store ,這兩個的差異等等會提到)
剛剛上面提到的都是一些靜態資源例如說圖片,特性就是會有好一陣子不會變動,因此可以放心地使用 max-age 。
但現在我們考慮到另外一種狀況,那就是網站首頁。
網站首頁雖然也不常會變動,但我們希望只要一變動,使用者就能夠馬上看到變化。那要怎麼辦呢?設 max-age 嗎?也是可以,例如說 Cache-Control: max-age=30 ,只要過 30 秒就能讓快取過期,去跟 Server 拿新的資料。
但如果我們想要更即時呢?只要一變動,使用者就能夠馬上看到變化。你可能會說:「那我們可以不要快取就好啦,每次都抓取新的頁面」。可是如果這個首頁有一個禮拜都沒有變,其實使用快取會是比較好的辦法,節省很多流量。
因此我們的目的是:「把頁面快取起來,但只要首頁一變動,就能夠立刻看到新的頁面」
這個怎麼做到呢?第一招,你可以用 Cache-Control: max-age=0 ,這就代表說這個 Response 0 秒之後就會過期,意思是瀏覽器一接收到,就會標示為過期。這樣當使用者再次造訪頁面,就會去 Server 詢問有沒有新的資料,再搭配上 Etag 來使用,就可以保證只會下載到最新的 Response。
例如說第一個 Response 可能是這樣:
Cache-Control: max-age=0 Etag: 1234
我重新整理一次,瀏覽器發出這樣的 Request:
If-None-Match: 1234
如果檔案沒有變動,Server 就會回傳: 304 Modified ,有變動的話就會回傳新的檔案並且更新 Etag 。如果是使用這種方式,其實就是「每一次造訪頁面都會發送一個 Request 去確認有沒有新的檔案,有的話就下載更新,沒有的話沿用快取裡的」。
除了上面這招 max-age=0 ,其實有一個已經規範好的策略叫做: Cache-Control: no-cache 。 no-cache 並不是「完全不使用快取的意思」,而是跟我們上面的行為一樣。每次都會發送 Request 去確認是否有新的檔案。
(註:其實這兩種還是有很細微的差別,可參考 What’s the difference between Cache-Control: max-age=0 and no-cache? )
如果要「完全不使用快取」,是 Cache-Control: no-store 。這邊不要搞混了。
為了怕大家搞混,我再講一次這兩個的差異:
假設 A 網站是使用 Cache-Control: no-store ,B 網站是使用 Cache-Control: no-cache 。
當每一次重新造訪同樣一個頁面的時候,無論 A 網站有沒有更新,A 網站都會傳來「整份新的檔案」,假設 index.html 有 100 kb 好了,造訪了十次,累積的流量就是 1000kb。
B 網站的話,我們假設前九次網站都沒有更新,一直到第十次才更新。所以前九次 Server 只會回傳 Status code 304 ,這個封包大小我們姑且算作 1kb 好了。第十次因為有新的檔案,會是 100kb。那十次加起來的流量就是 9 + 100 = 109 kb
可以發現 A 跟 B 達成的效果一樣,那就是「只要網站更新,使用者就能立即看到結果」,但是 B 的流量遠低於 A,因為有善用快取策略。只要每一次 Request 都先確認網站有沒有更新即可,不用每一次都抓完整的檔案下來。
這就是 no-store 跟 no-cache 的差異,永遠不用快取跟永遠檢查快取。
現在 Web App 當道,許多網站都是採用 SPA 的架構搭配 Webpack 打包。前端只需要引入一個 Javascript 的檔案,Render 就交給 Javascript 來做就好。
這類型的網站,HTML 可能長得像這樣:
當 Javascript 載入之後,利用 Javascript 把頁面渲染出來。
面對這種情境,我們就會希望這個檔案能夠跟上面的首頁檔案一樣,「只要檔案更新,使用者能夠立即看到新的結果」,因此我們可以用 Cache-Control: no-cache 來達成這個目標。
可是呢,還記得剛說過 no-cache 其實就是每一次訪問頁面,都去 Server 問說有沒有新的結果。意思就是無論如何,都會發出 Request。
有沒有可能,連 Request 都不發呢?
意思就是:「只要檔案不更新,瀏覽器就不會發 Request,直接沿用快取裡的即可。只要檔案一更新,瀏覽器就要立即抓取新的檔案」
前者其實就是我們一開始講的 max-age 在做的事,但 max-age 沒辦法做到判斷「檔案不更新」這件事情。
所以其實這個目標,沒辦法單靠上面我們介紹的這些瀏覽器的快取機制來達成,需要 Server 那邊一起配合才行。其實說穿了,就是把 Etag 的機制自己實作在檔案裡面。
什麼意思呢?我們直接來看一個範例,我們把 index.html 改成這樣:
注意到 Javascript 的檔名變成: script-qd3j2orjoa.js ,後面其實就跟 Etag 一樣,都是代表這個檔案的 hash 值。然後我們把這個檔案的快取策略設成: Cache-Control: max-age=31536000 。
這樣子這個檔案就會被快取住一年。一年之內都不會對這個 URL 發送新的 Request。
那如果我們要更新的話怎麼辦呢?我們不要更新這個檔案,直接更新 index.html ,換一個 Javascript 檔案:
因為 index.html 的快取策略是 no-cache ,所以每一次訪問這個頁面,都會去看 index.html 是否更新。
以現在這個例子來說,它的確更新了,因此新的這份就會傳回給瀏覽器。而瀏覽器發現有新的 Javascript 檔案就會去下載並且快取起來。
藉由把 Etag 的機制實作在 index.html 裡面,我們就達成了我們的目標:「只要檔案不更新,瀏覽器就不會發 Request,直接沿用快取裡的即可。只要檔案一更新,瀏覽器就要立即抓取新的檔案」
原理就是針對不同的檔案採用不同的快取策略,並且直接用「更換 Javascript 檔案」的方式強制瀏覽器重新下載。
這邊也可以參考 Google 提供的圖片:

(來源: https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching?hl=zh-tw)
之所以快取的機制會有點小複雜,是因為分成不同的部分,每一個相關的 Header 其實都是在負責不同的部分。例如說 Expires 跟 max-age 是在負責看這個快取是不是「新鮮」, Last-Modified , If-Modified-Since , Etag , If-None-Match 是負責詢問這個快取能不能「繼續使用」,而 no-cache 與 no-store 則是代表到底要不要使用快取,以及應該如何使用。
這篇文章其實只講到快取機制的一半,沒有提到的部分大致上都跟 shared cache 以及 proxy server 有關,有其他的值是在決定快取能不能被存在 proxy server 上?或者是驗證能否繼續使用的時候應該要跟原 server 驗證,還是跟 proxy server 驗證也可以。有興趣想要知道更多的讀者們可以參考底下的參考資料。
最後,希望這篇文章能讓初學者更理解 HTTP 的快取機制。
關於作者:
@huli 野生工程師,相信分享與交流能讓世界變得更美好
喜歡我們的文章嗎?歡迎分享按讚給予我們支持和鼓勵!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持 我们







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有