由于其对于原始数据潜在概率分布的强大感知能力,GAN成为了当下最热门的生成模型之一。然而,训练不稳定、调参难度大一直是困扰着GAN爱好者的老问题。本文是一份干货满满的GAN训练心得

由于其对于原始数据潜在概率分布的强大感知能力,GAN 成为了当下最热门的生成模型之一。然而,训练不稳定、调参难度大一直是困扰着 GAN 爱好者的老问题。本文是一份干货满满的 GAN 训练心得,希望对有志从事该领域研究和工作的读者有所帮助!
在当下的深度学习研究领域中,对抗生成网络(GAN)是最热门的话题之一。在过去的几个月里,关于 GAN 的论文数量呈井喷式增长。GAN 已经被应广泛应用到了各种各样的问题上,如果你之前对此并不太了解,可以通过下面的 Github 链接看到一些酷炫的 GAN 应用:
时至今日,我已经阅读了大量有关 GAN 的文献,但我还从来没有自己动手实践过。因此,在浏览了一些对人有所启发的论文和 Github 代码仓库后,我决定亲自尝试训练一个简单的 GAN。不出所料,我立刻就遇到了一些问题。
本文的目标读者是从 GAN 入门的热爱深度学习的朋友。除非你走了大运,否则你自己第一次训练一个 GAN 的过程可能是非常令人沮丧的,而且需要花费好几个小时才能做好。当然,随着时间的推移和经验的增长,你可能会渐渐善于训练 GAN。但是对于初学者来说,可能会犯一些错,而且不知道该从哪里开始调试。在本文中,我想向大家分享我第一次从头开始训练 GAN 时的观察和经验教训,希望本文可以帮助大家节省几个小时的调试时间。
GAN 简介
在过去的一年左右的时间里,深度学习圈子里的每个人(甚至一些没有参与过深度学习相关工作的人),都应该对 GAN 有所耳闻(除非你住在深山老林里、与世隔绝)。生成对抗网络(GAN)是一种数据的生成式模型,主要以深度神经网络的形式存在。也就是说,给定一组训练数据,GAN 可以学会估计数据的底层概率分布。这一点非常有用,因为我们现在可以根据学到的概率分布生成原始训练数据集中没有出现过的样本。如上面的链接所示,这催生了一些非常实用的应用程序。
该领域的专家已经提供了一些很棒的资源来解释 GAN 以及它们的工作远离,所以本文在这里不会重复他们的工作。但是为了保持文章的完整性,在这里对相关概念进行简要的回顾。
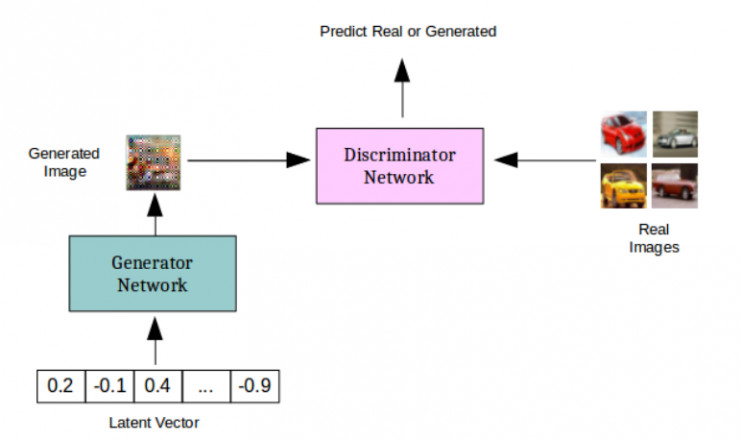
GAN 模型概览
生成对抗网络实际上是两个相互竞争的深度网络。给定一个训练集 X(比如说几千张猫的图像),生成网络 G(x) 会将随机向量作为输入,并试图生成与训练集中的图像相类似的新图像样本。判别器网络 D(x) 则是一种二分类器,试图将训练集 X 中「真实的」猫的图像和由生成器生成的「假的」猫图像区分开来。如此一来,生成网络的职责就是学习 X 中的数据的分布,这样它就可以生成看起来真实的猫图像,并确保判别器无法区分来自训练集的猫图像和来自生成器的猫图像。判别器则需要通过学习跟上生成器不断进化、尝试通过新的方式生成可以「骗过」判别器的「假的」猫图像的步伐。
最终,如果一切顺利,生成器(或多或少)会学到训练数据的真实分布,并变得非常善于生成看起来真实的猫图像。而判别器则不能再将训练集中的猫图像和生成的猫图像区分开来。
从这个意义上说,这两个网络一直在努力确保对方不能很好地完成自己的任务。那么,这究竟是如何起作用的呢?
另一种看待 GAN 的方式是:判别器试图通过高速生成器真实的猫图像看起来是怎样的,从而引导生成器。最终,生成器研究清楚了问题,开始生成看起来真实的猫图像。训练 GAN 的方法类似于博弈论中的极大极小算法,两个网络试图达到同时考虑二者的纳什均衡。更多细节,请参阅本文底部给出的参考资料。
GAN 训练面临的挑战
下面,我们将继续分析 GAN 的训练过程。为了简单起见,我使用了「Keras+Tensorflow 后端」的组合,在 MNIST 数据集上训练了一个 GAN(确切地说是 DC-GAN)。这并不太困难,在对生成器和判别器网络进行了一些小的调整之后,GAN 就可以生成清晰的 MNIST 图像了。

生成的 MNIST 数字
如果你觉得 MNIST 中黑白数字没那么有趣,那么生成各种物体和人的彩色图片还很酷炫的。而这样一来,问题就变得棘手了。在攻克了 MNIST 数据集之后,显然下一步就是生成 CIFAR-10 图像。经过日复一日的超参数调参、改变网络架构、增添或删除网络层,我终于能够生成出高质量的和 CIFAR-10 类似的图像。

使用 DC-GAN 生成的青蛙

使用 DC-GAN 生成的汽车
我最初使用了一个非常深的网络(但是大多数情况下性能并不佳),最后使用的真正有效的网络却十分简单。在我开始调整网络和训练过程时,经过 15 个 epoch 的训练后生成的图像从这样:

变成了这样:

最终的结果是:

下面,我基于自己犯过的错误以及一直以来学到的东西,总结出了 7 大规避 GAN 训练陷阱的法则。所以,如果你是一个 GAN 新兵,在训练中没有很多成功的经验,也许看看下面的几个方面可能会有所帮助:
郑重声明:下面我只是列举出了我尝试过的事情以及得到的结果。并且,我并不是说已经解决了所有训练 GAN 的问题。
1. 更大更多的卷积核
更大的卷积和可以覆盖前一层特征图中的更多像素,因此可以关注到更多的信息。在 CIFAR-10 数据集上,5*5 的卷积核可以取得很好的效果,而在判别器中使用 3*3 的卷积核会使判别器损失迅速趋近于 0。对于生成器来说,我们希望在顶层的卷积层中使用较大的卷积核来保持某种平滑性。而在较底层,我并没有发现改变卷积核的大小会带来任何关键的影响。
卷积核的数量的提升会大幅增加参数的数量,但通常我们确实需要更多的卷积核。我几乎在所有的卷积层中都使用了 128 个卷积核。特别是在生成器中,使用较少的卷积核会使得最终生成的图像太模糊。因此,似乎使用更多的卷积核有助于捕获额外的信息,最终会提升生成图像的清晰度。
2. 反转标签(Generated=True, Real=False)
尽管这一开始似乎有些奇怪,但是对我来说,改变标签的分配是一个重要的技巧。
如果你正在使用「真实图像=1」、「生成图像=0」的标签分配方法,将标签反转过来会对训练有所帮助。正如我们会在后文中看到的,这有助于在迭代早期梯度流的传播,也有助于训练的顺利进行。
3. 软标签和带噪声标签
这一点在训练判别器时极为重要。使用硬标签(非 1 即 0)几乎会在早期就摧毁所有的学习进程,导致判别器的损失迅速趋近于 0。我最终用一个 0-0.1 之间的随机数来代表「标签 0」(真实图像),并使用一个 0.9-1 之间的随机数来代表 「标签 1」(生成图像)。在训练生成器时则不用这样做。
此外,添加一些带噪声的标签是有所帮助的。在我的实验过程中,我将输入给判别器的图像中的 5% 的标签随机进行了反转,即真实图像被标记为生成图像、生成图像被标记为真实图像。
4. 批量归一化有所助益,但还有其它先决条件
批量归一化当然对提升最终的结果有所帮助。加入批量归一化可以最终生成明显更清晰的图像。但是,如果你错误地设置了卷积核的大小和数量,或者判别器损失迅速趋近于 0,那加入批量归一化可能也无济于事。

在网络中加入批量归一化(BN)层后生成的汽车
5. 一次训练一类
为了便于训练 GAN,确保输入数据有类似的特性是很有用的。例如,与其在 CIFAR-10 数据集中所有 10 个类别上训练 GAN,不如选出一个类别(比如汽车或青蛙),训练 GAN 根据此类数据生成图像。DCGAN 的另外一些变体可以很好地学会根据若干个类生成图像。例如,条件 GAN(CGAN)将类别标签一同作为输入,以类别标签为先验条件生成图像。但是,如果你从一个基础的 DCGAN 开始学习训练 GAN,最好保持模型简单。
6. 观察梯度的变化
如果可能的话,请监控网络中的梯度和损失变化。这可以帮助我们了解训练的进展情况。如果训练进展不是很顺利的话,这甚至可以帮助我们进行调试。
理想情况下,生成器应该在训练的早期接受大梯度,因为它需要学会如何生成看起来真实的数据。另一方面,判别器则在训练早期则不应该总是接受大梯度,因为它可以很容易地区分真实图像和生成图像。当生成器训练地足够好时,判别器就没有那么容易区分真实图像和生成图像了。它会不断发生错误,并得到较大的梯度。
我在 CIFAR-10 中的汽车上训练的几个早期版本的 GAN 有许多卷积层和批量归一化层,并且没有进行标签反转。除了监控梯度的变化趋势,监控梯度的大小也很重要。如果生成器中网络层的梯度太小,学习可能会很慢或者根本不会进行学习。
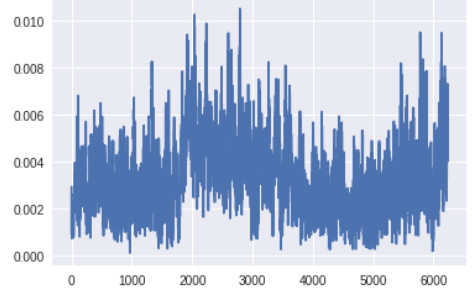
生成器顶层的梯度(x 轴:minibatch 迭代次数)
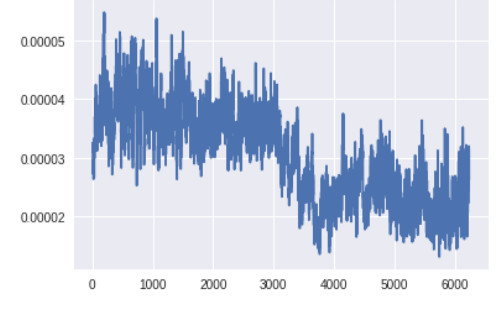
生成器底层的梯度(x 轴:minibatch 迭代次数)
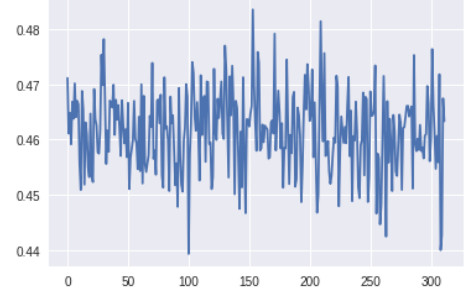
判别器顶层的梯度(x 轴:minibatch 迭代次数)
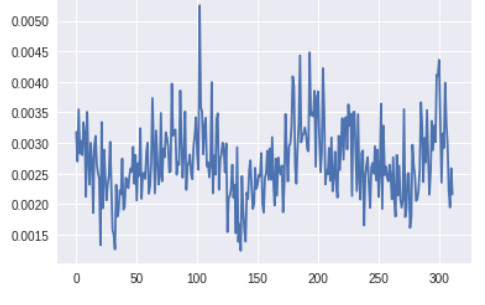
判别器底层的梯度(x 轴:minibatch 迭代次数)
生成器最底层的梯度太小,无法进行任何的学习。判别器的梯度自始至终都没有变化,说明判别器并没有真正学到任何东西。现在,让我们将其与带有上述所有改进方案的 GAN 的梯度进行对比,改进后的 GAN 得到了很好的、与真实图像看起来类似的图像:
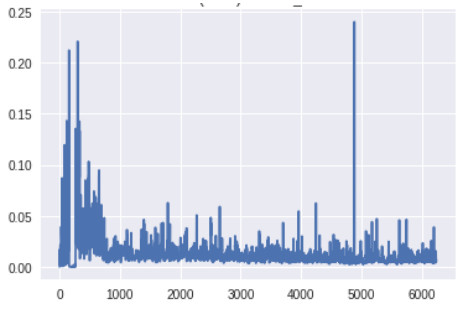
生成器顶层的梯度(x 轴:minibatch 迭代次数)
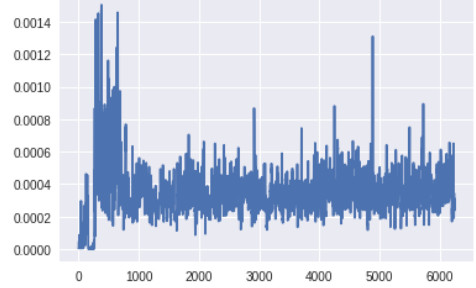
生成器底层的梯度(x 轴:minibatch 迭代次数)
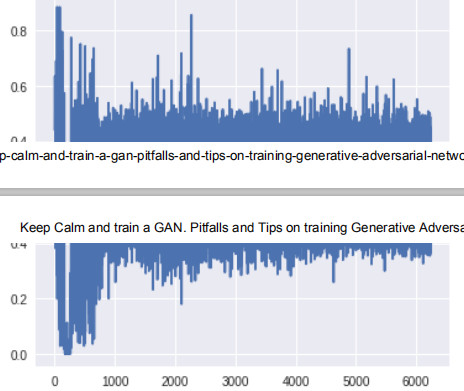
判别器顶层的梯度(x 轴:minibatch 迭代次数)
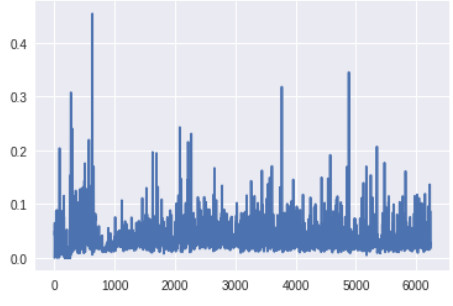
判别器底层的梯度(x 轴:minibatch 迭代次数)
此时生成器底层的梯度明显要高于之前版本的 GAN。此外,随着训练的进展,梯度流的变化趋势与预期一样:生成器在训练早期梯度较大,而一旦生成器被训练得足够好,判别器的顶层就会维持高的梯度。
7.不要采用早停法(early stopping)
可能是由于我缺乏耐心,我犯了一个愚蠢的错误——在进行了几百个 minibatch 的训练后,当我看到损失函数仍然没有任何明显的下降,生成的样本仍然充满噪声时,我终止了训练。比起等到训练结束才意识到网络什么都没有学到,重新开始工作、节省时间确实让人心动。GAN 的训练时间很长,初始的少量的损失值和生成的样本几乎不能显示出任何趋势和进展。在结束训练过程并调整设置之前,还是很有必要等待一段时间的。
这条规则的一个例外情况是:如果你看到判别器损失迅速趋近于 0。如果发生了这种情况,几乎就没有任何机会补救了。最好在对网络或训练过程进行调整后重新开始训练。
最终的 GAN 的架构如下所示:
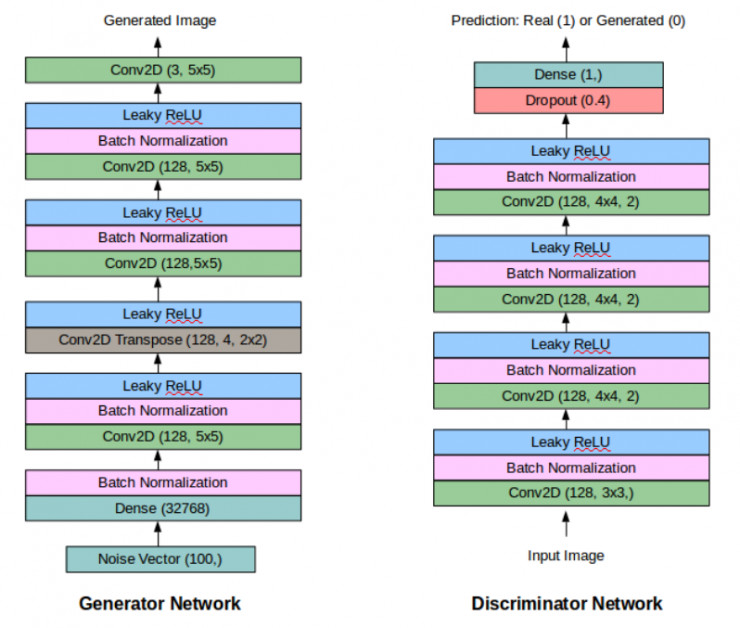
希望本文中的这些建议可以帮助所有人从头开始训练他们的第一个 DC-GAN。下面,本文将给出一些包含大量关于 GAN 的信息的学习资源:
GAN 论文参考:
「Generative Adversarial Networks」
「Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks」
「Improved Techniques for Training GANs」
其他参考链接:
「Training GANs: Better understanding and other improved techniques」
「NIPS 2016 GAN 教程」
「Conditional GAN」
本文最终版 GAN 的 Keras 代码链接如下:
https://github.com/utkd/gans/blob/master/cifar10dcgan.ipynb?source=post_page
via https://medium.com/@utk.is.here/keep-calm-and-train-a-gan-pitfalls-and-tips-on-training-generative-adversarial-networks-edd529764aa9 雷锋网雷锋网(公众号:雷锋网)雷锋网
。









![详解 Python 的二元算术运算,为什么说减法只是语法糖?[Python常见问题]](https://img1.php1.cn/3cd4a/24cea/ae9/99a758096bea3e3d.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号