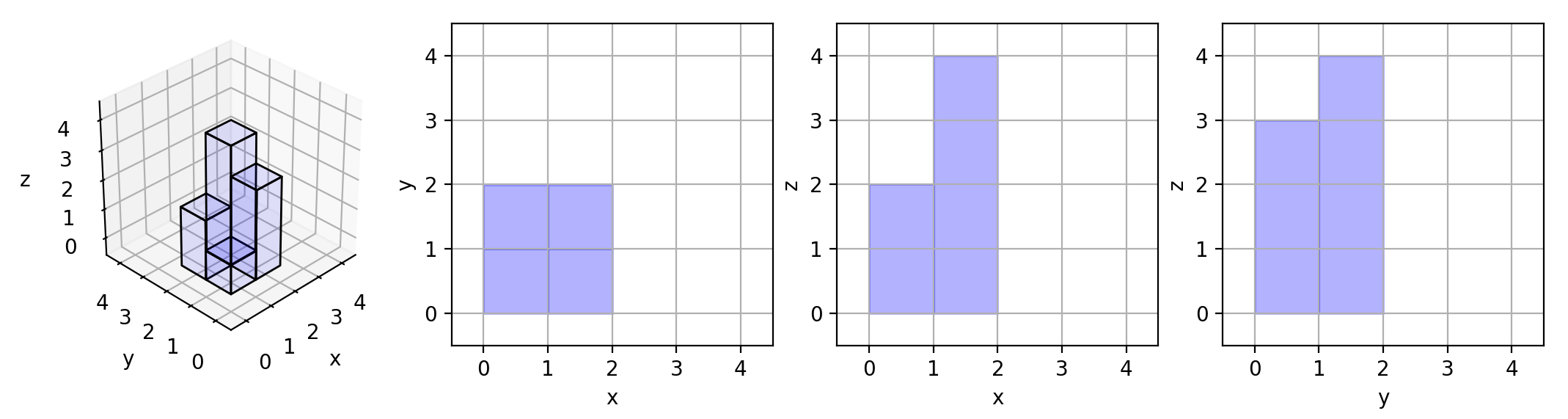
根据B站上自考数据结构课程讲解PPt (勉强吧) 手抄
方便后续复习和重点难点理解
转载需注明
线性表的链式存储结构(二)
单链表上的基本运算
单链表的建立
动态建立单链表的常用方法有两种:一个头插法一个尾插法。
头插法建表,从一个空表开始,重复读入数据,生成新的结点,将读入的数据放到新的结点的数据域中,然后将新的结点插入到当前链表的表头上,直到读入结束标志为止。
LinkList CreateListF()
{
LinkList head;
listNode p;
char ch;
head = NUll;
ch = getchar();
while(ch!="\n")
{
P=(ListNode)malloc(sizeof(ListNode));
p->data = ch;
p->next =head;
head = p;
ch =getchar();
}
return head;
}
顺序表删除
void DeleteList(SeqList *L,int i)
{
//删除表元素表的第i个元素
int j;DataType x
if(i<1||i>L->length)//判断i值是否合法&#xff1f;当i<1或i>length时&#xff0c;i值不合法。
{
printf(“position error”)
exit(0);//不合法退出
}
DataType x&#61; L->data[i];//保存被删除的元素
for(j &#61;i ;j<&#61;length-1;j&#43;&#43;)
L->data[j - 1]&#61;L->data[j];//元素前移
L->length - -;//实际表长减一
return x;//返回被删除的元素
}
单链表的概念
节点的结构&#xff1a;data:next
单链表&#xff1a;head -> 开始节点 -> a2 —>终端节点
链表不同于顺序表&#xff0c;顺序表占用的存储空间是连续的&#xff0c;而链表的各节点占用的存储空间之间可以是连续的&#xff0c;也可以是不连续的&#xff1b;但每个节点的内部占用的存储单元地址必须是连续的&#xff0c;因此链表中节点的逻辑次序和物理次序不一定相同&#xff0c;通过指针来反映节点之间的逻辑关系。
2.单链表数据类型的定义
typedef struct node //节点类型定义
{
DataType data; //节点的数据域
struct node *next; //节点指针域
}ListNode;
typeof ListNode *LinkList;
ListNode *p; //定义一个指向单链表的头指针
ListList head; //定义一个单链表的头指针
p -> data若出现在表达式中&#xff0c;它表示由P所指的链节点的数据域的内容&#xff1b;否则&#xff0c;标识由p所指的那个系欸但的数据域&#xff08;位置&#xff09;&#xff1b;
p->data &#61;x; p->data &#61; p->data&#43;25;
位置 位置 内容
p->next若出现在表达式中&#xff0c;它表示由p所指的链接点的指针域内容&#xff0c;也就是p所致的链接点的下一个结点的下一个链接点的存储地址&#xff1b;否则&#xff0c;表示由P所指的那个链节点的指针域&#xff08;位置&#xff09;。
对于表达是中的p->next->data。表示p所指的链节点的数据域中的信息。
尾插法:将新的结点插入在当前链表的表尾上&#xff0c;因此需要增设一个尾指针rear,使其始终指向链表的尾结点。
LineList CreateListR()
{
LinkList head,rear;
ListNode p;
char ch;
head &#61; NULL, rear &#61;NUll;
ch &#61; getchar();
while(ch!&#61;"\n")
{
p &#61; (ListNode) malloc(Sizeof(ListNode))
p ->data &#61; ch;
if(head &#61; &#61; NULL)
head &#61; p;
else rear->next &#61; p;
rear &#61; p;
ch &#61; getchar();
}
}
带头节点的单链表:作用是可以简化单链表的算法
head - >头节点->a2 开始结点-> a3->anNULL 终端结点
在引入头结点之后&#xff0c;尾插法建立单链表的算法可简化为&#xff1a;
LinkList CreateListRl()//尾插法建立带头结点的单链表算法
{
LinkList head &#61; (ListNode *)malloc(Sizeof(ListNode));
ListNode *p,*r;
DataType ch;
r &#61; head;
while((ch&#61;getchar()) !&#61; “\n”)
{
p&#61;(ListNode *)malloc(Sizeof(ListNode));
p->data &#61; ch;
r->next &#61; p;
r &#61; p;
}
r ->next &#61;NULL;
return head;
}
在单链表中查找值为k的结点
算法描述
ListNode * LockateNodek(Linklist head,DataType k)
{
//head 为带头结点的单链表的头指针&#xff0c;k为要查找的结点值
ListNode *p &#61; head ->next;
while(p&&p->next &#61; &#61;k )
p&#61;p->next;
return p;
}
插入运算
将值为X的新结点插入到表的第i个结点的位置上&#xff0c;即插入到ai-1与ai之间。
算法思想:先使p执行ai-1的位置&#xff0c;然后生产一个数据域值为x的新结点*s,再进行插入操作。
head->头结点 ->a1开始结点—>a2->ai-1§->s X—>ai
算法描述
void InsertList&#xff08;LinkList head,int i,dataType X&#xff09;
{
ListNode *p,*s;int j;
p &#61; head; j&#61; 0;
while(p!&#61;NUll && j
p&#61;p->next; &#43;&#43;j;
}
if (p&#61;NUll)
{
printf(“error \n”);return;
}
}
else
删除运算
将链表的第i个结点从表中删去
算法思想&#xff1a;先使P指向ai-1的位置&#xff0c;然后执行p->next指向第i&#43;1个结点&#xff0c;再将i个结点释放掉。
算法描述
DataTypeDeleteList(LinkList head,int i)
{
ListNode *p,*s;
dataType x;int j;
p &#61;head;j &#61;0;
while(p!&#61;NUll&&j<&#61;i-1)
{
p&#61;p->next;
}
if(p&#61;NULL){printf(“位置错误”);exit&#xff08;0&#xff09;;
}
else{
s &#61; p->next;
p->next &#61;s->next;
x&#61;s->data;
free(s);return x;
}
}
LinkList mynote(LinkList L)
{
if(L&&L->next)
{
q&#61;l;L&#61;l->next;p&#61;l;
S1:while(p->next);p&#61;p->next;
s2:p->next &#61; q;
q->next &#61; NULL;
}
return L;
}
试写一个算法&#xff0c;将一个头结点指针为阿德带头结点的单链表A分解成两个单链表A和B,其中头结点指针分配为a和b&#xff0c;使得A链表中含有 原A链表中的序号奇数的元素&#xff0c;而B链表中含有原链表中序号为偶数的元素&#xff0c;并保持原来的相对顺序。
分析;遍历整个链表A,当遇到序号为奇数的结点时将其连接到A表上&#xff0c;序号为偶数结点时&#xff0c;将其链接到B表中&#xff0c;一直到遍历结束。
void split&#xff08;LinkList a,LinkList b&#xff09;
{
ListNode *p,*r,*s;
p &#61; a->next;
r &#61; a ;
s &#61; b;
while(p!&#61; NULL)
{
r->next &#61; p;
r &#61; p;
p &#61; p->next;
if§
{
s->next &#61;p;
s &#61;p;
p &#61;p ->next;
}
}
}
假设头指针为La和Lb的单链表分别为线性表A和B的存储结构&#xff0c;两个链表都是按结点数据值递增有序的。试写一个算法&#xff0c;将这两个单链表合并成为一个有序的链表L.
分析&#xff1a;简历三个指针 Pa、pb、pc&#xff0c;其中pa和pb 分别指向La和Lb表中当前待比较插入的结点&#xff0c;而pc则指向Lc表示当前的最后一个结点&#xff0c;若pa->data<&#61;pb->data,则将 pa所指向的结点链接到pc所指的结点之后&#xff0c;否则将Pb所指向的结点链接到PC所指的结点之后。
linkList MergeL. ist(LinkList La,LinkList Lb)
{
ListNode *pa,*pb,*Pc;
LinkList Lc;
pa&#61;La->next;
pb&#61;Lb->next;
Lc&#61;pc&#61;la;
while(pa!&#61;NULl&&pb!&#61;NULl)
if(pa->data<&#61;pa->data)
pc->next&#61;pa;
pc&#61; pa;
pa &#61; pa->next;
else
pc ->next&#61;pb;
pc &#61; pb;
pb &#61; pb-next;
pc->netx &#61;pa!&#61;NULL?pa:pb;
free(Lb);
return Lc;
}
线性表的链式存储结构&#xff08;四&#xff09;
三、循环链表
循环链表与单链表的区别仅在于其尾结点的链域值不是NULl &#xff0c;而是一个指向头结点的指针。
循环链表的主要优点是&#xff1a;从表中任意一结点出发都能通过后移操作而遍历整个循环链表。
在循环链表中&#xff0c;将头指针改设为尾指针&#xff08;rear&#xff09;后&#xff0c;物流是找头结点、开始结点还是终端点都很方便&#xff0c;
它们存储位置分别是rear->next/rear->next->next/rear.这样可以简化基本的操作。
已知有一个结点的数据域为整型&#xff0c;且按从大到小顺序排列的头结点指针L的非空单循环链表&#xff0c;试写一算法
插入一个结点&#xff08;其数据域为X&#xff09;直至循环链表的适当位置&#xff0c;使之保持链表的有序性。
分析&#xff1a;要解决这个算法问题&#xff0c;首先就是要解决查找插入位置&#xff0c;方法&#xff1a;使用指针q扫描循环链表&#xff0c;循环条件应该是
&#xff08;q->data>x&&q!&#61;L&#xff09;,同时使用指针p基类q的直接前驱&#xff0c;已方便进行插入操作。
voidInsertList(LinkList L,int x)
{
ListNode *s,*p,*q;
s&#61;(ListNode)malloc(sizeof(ListNode));
s->data &#61;x&#xff1b;p&#61;l;
q&#61;p->next;
while(p->data>x&&q!&#61;L)
{
p&#61;p->next;
q&#61;p->next;
}
p->data&#61;s;
s-next&#61;q;
}
顺序表和链表的比较
一、顺序表的优缺点
优点&#xff1a;1.空间利用率高 2.可以实现随机存取。
缺点&#xff1a;1.插入删除操作需要大量的移动结点&#xff0c;时间性能差
2.需要事先确定少顺序表的大小&#xff0c;估计小了会发生溢出现象&#xff0c;估计打了又将造成空间浪费。
二、链表的优缺点
有点&#xff1a;1.插入、删除操作中无需移动结点 &#xff0c;时间性能好。
2.因为动态分配存储空间&#xff0c;空闲空间就不会发生溢出现象
缺点&#xff1a;每个结点都额外设置指针域&#xff0c;空间利用率低
顺序表和链表比较
通过上述比较&#xff0c;可以看出算法的时间性能与空间性能往往是一对矛盾&#xff0c;时间性能的改善往往要以牺牲空间性能为代价&#xff0c;反之亦然。因此在实际中&#xff0c;要根据具体情况来确定采用哪种存储结构。
1.对线性表的操作时经常性的查找运算&#xff0c;以顺序表形式存储为宜。
2.如果经常的运算是插入和删除&#xff0c;以链式存储为宜。
3.对于线性表的结点存储密度问题&#xff0c;也是选择存储结构的一个重要依据。所谓存储密度就是结点空间的利用率。
它的计算公式是&#xff1a;
存储密度&#61;结点数据域所占空间/整个结点所占空间
结点存储密度越大&#xff0c;存储空间的利用率越高。
栈
一、栈的定义及运算
1、栈的定义
栈&#xff08;stock&#xff09;&#xff1a;是限定在表的一端进行插入和删除运算的线性表&#xff0c;通常将插入、删除的一端称为栈顶&#xff08;top&#xff09;,另一端称为栈底&#xff08;bottom&#xff09;。不含元素的空表称为空栈。
栈的修改是按后进先出的原则进行的&#xff0c;因此栈又称为后进先出&#xff08;Last in first out&#xff09;的线性表&#xff0c;简称Lifo表。
2.栈的基本运算
1.置空栈initStack(&S):构造一个空栈S.
2.判栈空StackEmpty&#xff08;S&#xff09;:若栈S为空栈。则返回tRUE&#xff0c;否则返回FAlSE.
3.判栈满StackFull&#xff08;S&#xff09;:若栈S为满栈&#xff0c;则返回True&#xff0c;否则返回false。
4.进栈&#xff08;又称入栈或插入&#xff09;&#xff1a;push(&S,x)将元素X插入s栈栈顶。
5.退栈又称为出栈或删除&#xff0c;Pop(&S):若栈S为非空&#xff0c;则将S的栈顶元素删除。并返回栈顶元素。
6.取栈顶元素GetTop(S):若S栈为非空&#xff0c;则返回栈顶元素&#xff0c;但不改变栈的状态。
二、栈的存储表示和实现
1、栈的顺序存储结构
&#xff08;1&#xff09; 顺序栈的概念
栈的顺序存储结构称为顺序栈。顺序栈也是用数组实现的&#xff0c;栈底位置是固定不变的&#xff0c;将栈底位置设置在数组的最低端&#xff08;即下标为0&#xff09;&#xff1b;栈顶位置是随着进栈和退栈操作而变化的&#xff0c;一个整型量top来只是当前栈顶位置&#xff0c;通常称为top为栈顶指针。
(2)顺序栈的类型描述
#define stackSize 100 //栈空间的大小应该根据实际需要来定义&#xff0c;这里假设为100
typedef char DataType; //datatype的类型可根据实际情况来定义&#xff0c;这里假设为char
typedef Stuct
{
DataType data[stackSize]; //数组data 用来存放表结点
int top; //表示栈顶指针
}SeqStack; //栈的数据类型
Seqstack s; //s为栈类型的变量
2.栈的顺序实现
&#xff08;1&#xff09;、置空栈
void InitStack(SeqStack *S)
{
//置空顺序栈。由于C语言数组下标是从O开始&#xff0c;所以栈中元素亦从0开始
//存储&#xff0c;因此空栈时栈顶指针不能是0&#xff0c;而只能是-1
S->top &#61;-1;
}
(2)、判栈空
void StackEmpty(stack *S)
{
return S->top &#61; &#61; -1;//如果栈空则S->top &#61; &#61; -1,返回1&#xff0c;反之&#xff0c;返回0
}
&#xff08;3&#xff09;、判栈满
int StackFull(*S)
{
return S->top&#61; &#61; StackSize-1;
//如果栈满则S->top &#61; &#61; StackSize-1的值为1&#xff0c;返回1&#xff0c;反之返回0&#xff1b;
}
&#xff08;4&#xff09;、进栈&#xff08;入栈&#xff09;
void Push(SeqStack *S,DataType x)
{
if(StackFull&#xff08;S&#xff09;)
printf(“stack overflow”); //判断函数满
else
{
S->top &#61; S->top &#43;1; //将栈顶指针加1
S->data[S->top]&#61;x; //将x入栈
}
}
&#xff08;5&#xff09;退栈&#xff08;出栈&#xff09;
DataType Pop(SeqStack *S)
{
if(StackEmpty(S))
{
printf(“Stack underflow”);
exit(0);
}
else
{
return S->data[S->top- -];//返回栈顶元&#xff0c;栈顶指针减1
}
}
&#xff08;6&#xff09;取栈顶元素&#xff08;不改变栈顶指针&#xff09;
DataType GetTop(SeqStack *S)
{
if(StackEmpty(S))
{
printf(“Stack empty”);
exit(0);
}
else
{
return S->data[S->top];
}
}
另外&#xff0c;同时使用多个栈时&#xff0c;多个栈分配在同一个顺序存储空间内&#xff0c;即让多个栈共享存储空间&#xff0c;则可以相互进行调节&#xff0c;既节约了空间&#xff0c;又可降低发生溢出的频率。当程序中使用两个栈时&#xff0c;可以将两个栈的栈底分别设置顺序存储空间的两端&#xff0c;让两个栈顶各种向中间延伸。
3.栈的链式存储结构
&#xff08;1&#xff09;链栈的概念
栈的链式存储结构称为链栈&#xff0c;它是运算受限的单链表&#xff0c;其插入和删除操作仅限制在表头位置上(栈顶)进行&#xff0c;因此不必设置头结点&#xff0c;将单链表的头指针head改为栈顶指针top即可。
&#xff08;2&#xff09;链栈的类型定义
typedef stuck stackNode
{
DataType data;
stuck stackNode *next;
}StackNode;定义结点
typedef StackNode *LinkStackl
linkStack top; //定义栈顶指针top
4.链栈的基本运算
判栈空
&#xff08;1&#xff09;int StackEmpty()
{
return top &#61; &#61; NULL; //栈空 top &#61; &#61;NUlL的值为1&#xff0c;返回1&#xff0c;否则返回0&#xff1b;
}
&#xff08;2&#xff09;进栈&#xff08;入栈&#xff09;
LinkStack Push(LinkStack top,DataType x) //将X插入栈顶
{ //无需判满
StackNode *P;
p &#61; (StackNode )malloc(Sizeof(StackNode)); //申请新的结点存储空间
p->data&#61;x; //申请新的结点
p->next &#61;top; //新结点P插入栈顶
top &#61;p; //更新栈顶指针top
}
第二节 栈的应用举例
一、圆括号匹配的检验
对于输入的一个算是表达式字符串&#xff0c;试写一算法判断其中圆括号是否匹配&#xff0c;若匹配则返回TURE&#xff0c;否则则返回FAlSE.
[分析]利用栈的操作来实现&#xff1a;循环读入表达式中的字符&#xff0c;如遇左括号“&#xff08;”就进栈&#xff1b;遇右括号“&#xff09;”则判断栈是否为空&#xff0c;若为空&#xff0c;则返回FALSE,否则退栈&#xff1b;循环结束后再判断栈是否为空&#xff0c;若栈空则说明括号匹配&#xff0c;否则说明不匹配。
算法描述
int Expr()
{
SeqStack S;
DataType ch,x;
InitStack(&S);
ch&#61;getChar();
while(ch!&#61;"\n")
{
if(ch&#61;&#61;"(")
Push(&S,ch);//遇左括号进栈
else
if(ch&#61;&#61;")")
{
if(StackEmpty(&S))
return 0;
else
x&#61;Pop(&S);
ch&#61; getchar();//读入下一个字符
} //end of while
}
if(StackEmpty(&S)) return 1;
else return 0;
}
二、字符串回文的判断
利用顺序栈的基本运算&#xff0c;试设计一个算法&#xff0c;判断一个输入字符串是否具有中心对称&#xff0c;例如ababbaba,abcba都是中心对称的字符串。
分析&#xff1a;从中间向两头进行比较&#xff0c;若完全相同&#xff0c;则该字符串是中心对称的&#xff0c;否则不是。这就要首先球场字符串串的长度&#xff0c;然后将前一半字符入栈。再利用退栈操作将其后一半字符进行比较。
算法描述
int symmetry&#xff08;char str[]&#xff09;
{
SeqStack S;
int j,k,i&#61; 0;
InitStack(&S);
while(Str[i]!&#61;"\0") i&#43;&#43;; //求串长度
for(j&#61;0,j {
Push(&s,str[j]); //前一半字符入栈
}
k&#61;(i&#43;!)/2; //后一半字符在串中的起始位置
//特别注意这条命令怎么处理奇偶数个字符的
for(j&#61;k;j
return 0; //有不相同的字符&#xff0c;即不对称
return 1; //完全相同&#xff0c;即对称
}
三、数制转换
将一个非负的十进制整数N转换成d进制
【分析】讲一个非负的十进制整数N转换成d进制的方法&#xff1a;N除以d,求出每一步所得的余数&#xff0c;然后将所有余数逆序书写就是一个十进制整数N对应的d进制数。
void conversion(int N,int d)
{
SeqStack S;
InitStack(&S);
while(N)
{
Push&#xff08;&S,N%d&#xff09;; //余数入栈
N&#61;N/d;
}
while(!StackEmpty(&S))
{
i &#61;Pop(&S);
printf("%d",i); //余数倒叙出栈
}
}
四、栈与递归
栈还有一个非常重要的应用就是在程序设计语言中实现递归。一个直接调用自己或间接调用自己的函数&#xff0c;称为递归函数。
递归是一个程序设计中强有力的工具&#xff0c;递归算法有两个关键条件&#xff1a;一是又一个递归公式&#xff1b;二是有终止条件。
例如&#xff1a;求n的阶乘可递归地定义为
1 n&#61;0
n! &#61;
n(n-1)! n>0
2阶的Fibinocci树列&#xff1a;
0 n&#61;0
Fib(n)&#61; 1 n&#61;1
fib(n-1)&#43;fib(n-2) n>1
试分析求阶乘的递归函数
long int fact&#xff08;int n&#xff09;
{
int temp;
if(n&#61; &#61;0)
return 1;
else
temp &#61; n*fact(n-1);
r12:return temp;
}
void main()
{
long int n;
n &#61;fact(5);
r11:printf(“5!&#61;%1d”,n);
}
n&#43;1 n<1
已知函数 fu(n)&#61; fu(n/2)*f(n/4) n>&#61;2
float fu(int n)
{
if(n<2)
return(n&#43;1); //递归终止条件
else
return fu(n/2)*fu(n/4); //递归公式
}
第三节 队列&#xff08;一&#xff09;
一、队列的定义及其运算
1、队列的定义
队列&#xff08;Queue&#xff09;是一种操作受限的线性表&#xff0c;它只允许在表的一端进行元素插入&#xff0c;而在另一端进行元素删除。允许插入的一端称为队尾&#xff08;rear&#xff09;,允许删除的一端称为队头&#xff08;front&#xff09;。
新插入的结点只能添加到队尾&#xff0c;被删除的只能是排在队头的结点&#xff0c;因此&#xff0c;队列又称为先进先出&#xff08;First In First Out&#xff09;的线性表&#xff0c;简称FIFO表。
某队列初始为空&#xff0c;若它的输入序列为&#xff08;a,b,c,d&#xff09;,它的输出序列应为&#xff08;A&#xff09;。
A. a,b,c,d B.d,c,b,a
C. a,c,b,d D.d,a,c,b
2、队列的基本运算
&#xff08;1&#xff09;置空队列InitQueue(Q),构造一个空队列。
&#xff08;2&#xff09;判队空QueueEmpty(Q),若Q为空队列&#xff0c;则返回TRUE,否则返回FALSE.
&#xff08;3&#xff09;入队列EnQueue(Q&#xff0c;x)),若队列不满&#xff0c;则将返回数据x插入到Q的队尾
&#xff08;4&#xff09;出队列DeQueue(Q),若队列不空&#xff0c;则删除队头元素&#xff0c;并返回该元素
&#xff08;5&#xff09;取队头GetFront(Q)&#xff0c;若队列不空&#xff0c;则返回队头元素
二、顺序循环队列
1、顺序队列的概念
队列的顺序存储结构称为顺序队列。队列的顺序存储结构是利用一块连续的存储单元存放队列中的元素的&#xff0c;设置两个指针front和rear分别指示队头和队尾元素在表中的位置。
设有一顺序队里Q,容量为5&#xff0c;初始状态Q.front&#61;Q.rear&#61;0,画出做完下列操作后队列及其头尾指针的状态变化情况&#xff0c;若不能入队&#xff0c;请简述其理由。
&#xff08;1&#xff09;d,e,b入队
&#xff08;2&#xff09;d,e出队
&#xff08;3&#xff09;i&#xff0c;j 入队
(4) b 出队
&#xff08;5&#xff09;n,o,p入队
j j
i i
b b b
e
d
第五步无法进行&#xff0c;因队列已满&#xff0c;再有元素入队&#xff0c;就会溢出&#xff0c;发生假溢。
2.顺序循环队
为了解决顺序队的“假溢”问题采用循环队。约定循环队的队头指针指向队头元素在数组中实际位置的前一个位置&#xff0c;队尾指针指示队尾元素在数组中的实际位置。其次再约定队头指针指示的结点不用于存储队列元素&#xff0c;只起标志作用。当这样队尾指针“绕一圈”后干啥队头指针时视为队满。
例 设Q是一个有11个元素存储空间的顺序循环队列&#xff0c;初始状态Q.front &#61; Q.rear &#61; 0,写出协力操作后头、尾指针的变化情况&#xff0c;若不能入队&#xff0c;请说明理由。
d,e,b,g,h 入队&#xff1b;d,e 出队
i,j,k,l,m入队&#xff1b;b出队&#xff1b;
n,o,p,q,r入队
解答
0 1 2 3 4 5 6 7 8 9 10
初始状态
d,e,b,g,h 入队&#xff1b;d,e 出队 b g h
i,j,k,l,m入队&#xff1b;b出队 g h i j k l m
n,o,p,q,r入队 o p g h i j k l m n
3、循环队的顺序存储的类型定义
#define QueueSize 100
typedef char DataType;
type struct
{
DataType data[QueueSize];
int front rear;
}CirQueue;
4、循环队列基本运算的各算法
&#xff08;1&#xff09;置空队列
void IntQueue(CirQueue *Q)
{
Q->front &#61; Q->rear &#61; 0;
}
(2)判队空
int QueueEmpty&#xff08;CirQueue *Q&#xff09;
{
return Q->front &#61; &#61; Q->rear;
}
(3)判队满
int QueueFull(CirQueue Q)
{
return (Q->rear&#43;1)%QueueSize&#61; &#61; Q->ftont;
}
(4)入队列
int EnQueue(CirQueue Q,DataType x)
{
if(QueueFull(Q))
printf(“overflow”);
else
{
Q->data[Q->rear]&#61;x;
Q->rear&#61;(Q->rear&#43;1)%QueueSieze; //循环意义下的加1
}
}
&#xff08;5&#xff09;取队头元素
DataType GetFront(Ci rQueueQ)
{
//获取Q的队头元素值
if(QueueEmpty(Q))
{
printf(“Queue empty”);
exit(0);
}
else
{
return Q->data[Q->front];
}
}
(6)出队列
DataType DeQueue(CirQueueQ)
{
DataType x;
if(QueueEmpty(Q))
{
printf(“Queue empty”);
}
}
例&#xff1a;
设栈S&#61;{1,2,3,4,5,6,7},其中7为栈顶元素&#xff0c;请写出调用函数Algo(S)后栈S的状态。其函数为&#xff1a;
void Algo(SeqStack S)
{
int i &#61; 1;
CirQueue Q;SeqStack T; //定义一个循环队列和一个栈
InitQueue(&Q);Initstack(&T); //初始化队列和栈
while(!StackEmpty(&S))
{
if(i% 2 !&#61; 0)
Push(&T,Pop(&S)); //栈中序列号为奇数的元素入T栈中
else //7、5、3/1顺序入栈T
EnQueue(&Q,Pop(&S));
i&#43;&#43;; //序号为偶数的元素入队列Q中
} //6、4、2顺序入队Q
while(!QueueEmpty(&Q))
push(&S,DeQueue(&Q));
while(!StackEmpty(&T)) //队Q中6、4、2顺序出队并入栈S
Push(&S,Pop(&T)); //队栈T中按1、3/5/7顺序出栈并入栈S
}
S中元素&#xff08;6,4,2,1&#xff0c;3,5,7&#xff09;
三、链队
1、链队的定义
队列的链式存储结构称为链队列。它是一种限制在表头删除和表尾插入操作的单链表。
2、链队的数据类型定义
type struct qnode
{
DataType data;
struct qnode *next;
}QueueNode;
typedef struct
{
QueueNode *front; //队头指针
QueueNode *rear; //队尾指针
}LinkQueue;
LinkQueue Q;
Q.front Q->头结点 -> a1队头结点-> a2 ->… -> 队尾结点an^
Q.rear -------------------------------------->
3.链队的基本运算实现
&#xff08;1&#xff09;构造空队列
Q->front Q–>头结点^
Q->rear —>
void InitQueue(LinkQueue Q)
{
Q->front &#61; (QueueNode)malloc(sizeof(QueueNode)) //申请头结点
Q->rear&#61;Q->front; //尾指针指向头结点
Q->rear->next &#61;NUll;
}
&#xff08;2&#xff09;判队空
int QueueEmpty(LinkQueue *Q)
{
return Q->rear &#61; &#61; Q->front; //头尾指针相等队列为空
}
&#xff08;3&#xff09;入队列
Q->front Q->头结点 ->队头结点a1-> a2—>…an__> p
Q->rear - - - - - - - - - - - - - - - - - - - -X^
void EnQueue()
(5)出队列
链队列出队列操作有两种不同情况要分别考虑。
1、当队列的长度大于1时&#xff0c;则出队操作只需要修改头结点指针域即可&#xff0c;尾指针不变&#xff0c;类似于单链表删除首结点&#xff0c;操作步骤&#xff1a;
S&#61;Q->front ->next;
Q->front ->next &#61;s->next;
x&#61;s->data;
free(s);return x; //释放队头结点&#xff0c;并返回其值
2若队列长度等于1&#xff0c;则出队时不仅要修改头及诶点指针域&#xff0c;而且还需要修改尾指针。
Q->front Q->头结点->ai^ Q->front Q->头结点^
Q->rear ----- - --> Q->rear————>
出队前 出队后
s &#61; Q->front->next;
Q->front->next&#61;NULL; //修改队头指针
Q->rear&#61;Q->front; //修改队尾指针
x&#61;s->data;
free(s);return x; //释放队头结点&#xff0c;并返回其值
为了方便&#xff0c;直接删除头结点&#xff0c;将原队头结点当头结点使&#xff0c;这样算法就简单了。
Q.front Q—>a2头结点–>队头结点---->…—>队尾结点 a2^
Q.rear - - - - - - - - - - - - - - - - - - - -->
链队列的出队算法描述
DataType DeQueue(LinkQueue *Q)
{ //删除链队的头结点&#xff0c;并返回头结点的元素值
QueueNode *P;
if(QueueEmpty(Q))
{
printf&#xff08;“Queue underflow”&#xff09;&#xff1b;
exit(0); //出错退出处理
}
else
{
p&#61;Q->front;
Q->front &#61; Q->front ->next;//P指向头结点
free§; //删除是否的原头结点
return&#xff08;Q->front->data&#xff09;; //返回原队头结点的数据值
}
}
真题选择&#xff0c;算法f31的功能是清空带头结点的链队列Q,请在空缺处填入合适内容&#xff0c;使其成为一个完整的算法。
typedef struct node
{
DataType data;
struct node *next;
}QueueNode;
typedef struct
{
QueueNode *front;
QueueNode *rear;
}LinkQueue;
void f31(LInkQueue *Q)
{
QueueNode *P&#xff0c;*S&#xff1b;
p &#61;(1);
while(P!&#61;NULL)
{
s&#61;p;
p&#61;p->next;
free(s);
}
----2---- &#61;null;
Q->rear&#61; --3—;
}
(1) Q->front ->next (2)Q->front->next (3)Q->front
4、循环队列
<--------- – - – - - — - - - - - - - - – -
头结点—>a1队头结点—>a2->…—>an队尾结点
rear---->
循环链队的类型定义
typedef struct queuenode
{
Datatype data;
struct queuenode *next;
}QueueNode;
QueueNode *rear;
(1)初始化空队列
<-- - - -
rear-----> 头结点————>
QueueNode *InitQueue(QueueNode *rear)
{
tear&#61;(QueueNode *)malloc(sizeof&#xff08;QueueNode&#xff09;);
rear ->next &#61;rear;
return rear;
}
11.24
(2)入队列
<—— – -- ---------- - - - - - - - - s
头结点 -->a1队头结点—>a2—>…an队尾结点—>x
rear- - >
void EnQueue(QueueNode *rear DataType x)
{
QueueNode *s &#61; (QueueNode *)malloc(sizeof(QueueNode));
s->data&#61;x;
s->next &#61; rear->next;
rear->next&#61;s;
rear &#61; s;
}
(3)出队列
<----- - - - - - - - - – - - - - -
s->头结点 ->t->a1 新头结点 —>a2---->…—> an 队尾结点
rear—>
DataType DeQueue(QueueNode *rear)
{
QueueNode *s,*t;
DataType x;
if(rear->next &#61; &#61; rear) //判队空
{
printf(“Queue Empty”);
exit(0);
}
else
{
s&#61;rear->next; //s指向头结点
rear ->next &#61;s->next; //删除头结点
t &#61;s ->next; //t指向原队头结点
x &#61;t->data; //保存原对头结点
free(s); //释放被删除的原头结点
return x; //返回出队结点的数据
}
}
第三节 队列&#xff08;二&#xff09;
四、栈和队列的应用实例
1、中缀表达式和后缀表达式
中缀表达式&#xff1a;9-&#xff08;2&#43;47&#xff09;/5&#43;3- - - - 符合人的习惯
后缀表达式&#xff1a;9247&#43;5/-3&#43; - – - 适合计算机操作的特点
后缀表达式特点&#xff1a;
&#xff08;1&#xff09;从左向有数字得顺序与中缀表达式完全相同
&#xff08;2&#xff09;从左向右运算符的顺序与中缀表达式的计算顺序完全相同&#xff1b;
&#xff08;3&#xff09;后缀表达式没有括号&#xff0c;运算规则简单
2.中缀表达式到后缀表达式的转换
中缀表达式转换为后缀表达式的算法思想&#xff1a;
顺序扫描中缀算术表达式&#xff1a;
&#xff08;1&#xff09;当读到数字时&#xff0c;直接将其送至输出队列中&#xff1b;
&#xff08;2&#xff09;当读到运算符时&#xff0c;将栈中所有优先级高于或等于该运算符的运算符弹出了&#xff0c;送至输出队列中&#xff0c;再将当前运算符入栈&#xff1b;
&#xff08;3&#xff09;当读入左括号时&#xff0c;即入栈&#xff1b;
&#xff08;4&#xff09;当读到右括号时&#xff0c;将靠近栈顶的第一个左括号上面的运算符全部依次弹出&#xff0c;送至输出队列中&#xff0c;再删除栈中的左括号。
中缀表达式&#xff1a;
9-&#xff08;2&#43;4*7&#xff09;/5&#43;3转换后缀表达式的过程&#xff1a;
【算法描述】
int Priorty(DataType op)
{
switch(op)
{
case ‘(’:
case ‘#’:return 0;
case ‘-’:
case ‘&#43;’:return 1;
case ‘*’:
case ‘/’:return 2;
}
return -1;
}
void CTPostExp(CirQueue Q)
{
SeqStack S;
char c,t;
InitStack(&S);
Push(&S,"#");
do
{
c&#61;getchar();
switch©
{
case’ ‘:break; //去除空格
case ‘0’:
case ‘1’:
case ‘2’:
case ‘3’:
case ‘4’:
case ‘5’:
case ‘6’:
case ‘7’:
case ‘8’:
case ‘9’:
case ‘(’:
case ‘)’:
case ‘#’: //右括号和#
do
{
t&#61;Pop(&S);//出栈
if(t!&#61;’(’&&!&#61;’#’)EnQueue(Q,t); //如果是运算符则入队
}while&#xff08;t!&#61;’(’&&S.top!&#61;-1&#xff09;; break;
//直到左括号出栈或栈空循环结束
case’&#43;’:
case’-’:
case’’:
case’/’&#xff1a;
while&#xff08;Prinority©<&#61;Priority(GetTop(s))&#xff09; //当前运算符优先级小于等于栈顶运算符优先级 {
t&#61;top(&S);EnQueue(Q,t); //运算符出栈&#xff0c;入队
}
Push(&S,c);break; //当前运算符入栈
} //ENDswitch
}
while(c!&#61;’#’); //以’#&#39;号结束表达式扫描
}
【算法描述】
int CPostExp(SeqQueue Q) //后缀表达式再队列Q中
{
SeqStack1 S; // S是顺序栈
char ch;int x,yl
Initstack1(&S); //初始化栈S
while(!QueueEmpty(Q))
{
ch&#61;DeQueue(&Q); //出队
if(ch>&#61;‘0’&&ch<&#61;‘9’) //是1~9
Push1(&S,ch-‘0’); //入栈
else
{
y&#61;Pop1(&S);
x&#61;Pop1(&S);
switch(ch)
{
case’&#43;’;Push1(&S,x&#43;y);break;
case’-’:Push1(&S,x-y);break;
case’’:Push1(&S,xy);break;
case’/’:Push1(&S,x/y);break;
}
}
}
return GetTopl(S);
}
真题选择 阅读下列算法&#xff0c;并回答问题&#xff1a;
&#xff08;1&#xff09;假设栈S&#61;(3,8,6,2,5),其中5为栈顶元素&#xff0c;写出执行函数f31(&S)后的S;
(2)简述函数f31的功能。
void f31(Stack *S)
{
Queue Q;InitQueue(&Q);
while(!StackEmpty(S))
EnQueue(&Q,Pop(&S));
while(!QueueEmpty(Q))
Push(&S,DeQueue(&Q));
}
(1)S(5,2,6,8,3)其中3为栈顶元素。
(2)函数f31的功能是将栈S中的元素倒置。
本章小结
本章重点介绍了顺序栈、链栈、循环队列及链队列的存储结构及基本运算&#xff0c;要求考生能熟练掌握。本章的难点是理解递归算法执行过程中栈的状态变化过程以及循环队列对边界条件的处理问题。
在本章中介绍了多个利用队列或栈设计算法解决简单应用问题的实例&#xff0c;特别是表达式求值问题的例子&#xff0c;它是一个综合的应用实例&#xff0c;几乎用到栈和队列的各种算法。通过这些例子&#xff0c;考试可以更好地理解栈和队列的特点和应用&#xff0c;增强分析问题解决问题的能力。
从历年考试情况来看&#xff0c;本章主要考顺序栈&#xff0c;链栈&#xff0c;循环队列及链队列的存储结构及其基本运算符&#xff0c;以选择题、填空题为主&#xff0c;有时有简单题或算法阅读理解题。
第一节 多维数组和运算符
一、多维数组的定义
1、一维数组
是一种元素个数固定的线性表。
2、多维数组
是一种复杂的数据结构&#xff0c;可以看成是线性表的推广&#xff0c;一个n维数组可以视为其数据元素为n-1维数组的线性表。
二、数组的顺序存储
通常采用顺序存储结构来存放数组。对二维数组可能有两种存储算法&#xff1a;一种是以行序为主序的存储方式&#xff0c;另一种是以列序为主序的存储方式。在C语言中&#xff0c;采用以行序为主序的存储。
&#xff08;1&#xff09;对于C语言的二维数组A[m][n],下标从0开始&#xff0c;假设一个数组元素占d个存储单元&#xff0c;则二维数组中任一元素a[i][j]的存储位置可由下式确定&#xff1a;
loc(A[i][j])&#61;loc(A[0][0])&#43;(i*n&#43;j)*d
真题选解
例题.单选题 二维数组A[4][5]按行优选顺序存储&#xff0c;若每个元素占2个存储单元&#xff0c;且第一个元素A[0][0]的存储地址为1000&#xff0c;则数组元素A[3][2]的存储地址为&#xff08;c&#xff09;
A.1012 b.1017 c.1034 d.1036
(2)对于C语言的三维数组A[m][n][p],下标从0开始&#xff0c;假设一个数组元素占d个存储单元&#xff0c;则三维数组中任一元素a[i][j][k]的存储位置可由下式确定&#xff1a;
loc(A[i][j][k])&#61;loc(A[0][0][0])&#43;(inp&#43;j*p&#43;k)*d
例题.单选
三维数组A[4][5][6]按行优先存储方法存储在内存中&#xff0c;若每个元素占2个存储单元&#xff0c;且数组中第一个元素的存储地址为120&#xff0c;则元素
A[3][4][5]的存储地址为&#xff08;b&#xff09;
A.256 b.358 c.360 d.362
解析&#xff1a;A[4][5][6]表示它公有4片&#xff0c;每片有5行&#xff0c;每行有6个元素。元素A[3][4][5]处在3片4行5列上&#xff0c;是三维数组的最后一个元素。按行优先存储方法存储时&#xff0c;它前面有三个完成的片&#xff0c;每片有56个元素。3片有356个元素…
loc(A[3][4][5])&#61;loc(A[0][0][0])&#43;(356&#43;46&#43;5)*2&#61;120&#43;238&#61;358
三、数组运算举例
设计一个算法&#xff0c;实现矩阵Amn的转置矩阵Bnm.
分析 对于一个mn的矩阵A,其转置矩阵是一个nm的矩阵B&#xff0c;而且B[i][j]&#61;A[j][i],0<&#61;i<&#61;n-1,0<&#61;j<&#61;m-1.假设m&#61;5,n&#61;8.
算法描述
void trsmat(int a[][8],int b[][5],int m,int n)
{
int i,j;
for(j&#61;0;j
}
例&#xff1a;如果矩阵A中存在这样的一个元素A[i][j],满足&#xff1a;A[i][j]是第i行元素中最小值&#xff0c;且又是第j列元素中最大值&#xff0c;则称此元素为该矩阵的一个马鞍点。假设以二维数组存储矩阵Am*n,试编写求出矩阵中所有马鞍点的算法。
分析 算法思想&#xff1a;先求出每行中的最小值元素&#xff0c;存入数组Min[m]之中&#xff0c;再求出每列的最大值元素&#xff0c;存入数组Max[n]之中。若某元素即在Min[i]中又在Max[j]中&#xff0c;则该元素A[i][j]就是马鞍点&#xff0c;找出所有这样的元素。
算法秒杀
void MaxMin(int A[4][5],int m,int n)
{
int i,j;
int Max[5],Min[4];
for(i&#61;0;i
Min[]&#61;A[i][0]; //先假设第i行第一个元素最小&#xff0c;然后再与后面的元素比较
for(j&#61;1;j
}
for(j&#61;0;j
Max[j]&#61;A[0][j]; //假设第j列第一个元素最大&#xff0c;然后再与后面的元素比较
for&#xff08;i&#61;1;i
Max[j]&#61;A[i][j];
}
for(i&#61;0;i
printf("%d,%d",i,j); //显示马鞍点
}
真题选解
例题.算法阅读题&#xff1a;
void f30(int A[],int n)
{
int i,j,m;
for(i&#61;1;i
m&#61;A[in &#43; j]; //A[in&#43;j]与A[jn&#43;i]值的交换
A[in&#43;j]&#61;A[jn&#43;i];
A[jn &#43; i]&#61; m;
}
}
回答下列问题&#xff1a;
1 2 3
&#xff08;1&#xff09;已知矩阵B&#61; 4 5 6 ,将其按行优先存于一维数组A中&#xff0c;给出执行函数调用f30(A,3)后矩阵B的值&#xff1b;
7 8 9
&#xff08;2&#xff09;简述函数f30的功能。
&#xff08;1&#xff09; 解析 数组A 1 2 3 4 5 6 7 8 9
循环过程
外层循环 内层循环 操作
i &#61; 1 j&#61;0 A[3]&#61;A[1]
i &#61; 2 j&#61;0 A[6]&#61;A[2]
j&#61;1 A[7]&#61;A[5]
执行后的数组A
数组A 1 2 3 4 5 6 7 8 9
A[0] A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8]
答案
1 4 7
B&#61; 2 5 8
3 6 9
(2)函数f30的功能是求解矩阵的转置
第二节 矩阵的压缩存储
一、特殊矩阵
特殊矩阵&#xff1a;是相同值的元素或者零元素在矩阵中的分布有一定规律的矩阵。
1、对称矩阵 真题选解 压缩矩阵的实现 2.三角矩阵 下三角矩阵 上三角矩阵 下三角矩阵的主对角线上的方均为常数c或零&#xff1b;上三角矩阵是指矩阵的下三角&#xff08;不包括对角线&#xff09;中的元素均为常数c或是零的n阶方阵。 下三角矩阵中&#xff0c;以行序为主存放&#xff0c;与对称矩阵类是&#xff0c;M[k]和aij的对应关系是: 真题选择 11.25 画出下列稀疏矩阵对应的三元组表 解析 根据签名的三元组的含义很容易画出该矩阵的三元组表 (2)三元组表的类型定义 例 试写一个算法&#xff0c;建立顺序存储稀疏矩阵的三元组表。 算法描述 例 试写一个算法&#xff0c;实现以三元组表结构存储的稀疏矩阵的转置运算。 M 1 0 0 0 -6 T 0 -2 0 8 0 0 2 1 (1)一般的转置算法 &#xff08;2&#xff09;快速转置算法 3、带行表的三元组表 注意 真题选解 &#xff08;1&#xff09;画出三元组表 (2)三元组行表 第三节 广义表基础 例 2、广义表的几个重要性质&#xff1a; (2)广义表具有递归和共享的性质&#xff0c;例如&#xff0c;表F就是一个递归的广义表&#xff0c;D表示共享的表&#xff0c;在表D中可以不必李处子表的值&#xff0c;而是通过字表的名字来引用。 二、广义表的基本运算 例 三、广义表的存储结构 本章小结 11.25 二、树的定义 (1)结点的度&#xff1a;结点所拥有的子树的个数。A的度3&#xff0c;E的度2
若n阶方阵A中的元素满足下述性质&#xff1a;
aij&#61;aji(0<&#61;i,j<&#61;n-1)
则称A为n阶的对称矩阵。
对于一个n阶的对称矩阵&#xff0c;可只存储其下三角矩阵&#xff1a;
a00
a10 a11
a20 a21 a22
… … …
ano an-11 … an-1n-1
将元素压缩存储到1&#43;2&#43;3&#43;…&#43;n&#61;n(n&#43;1)/2个元素的存储空间中&#xff0c;假设以一维数组sa[n(n&#43;1)/2] 作为n阶对称矩阵A的存储结构&#xff0c;以行序为主序存储其下三角&#xff08;包括对角线&#xff09;中的元素&#xff0c;数组M[k]和aij的对应关系&#xff1a;
1&#43;2&#43;3&#43;…&#43;i&#43;j&#61;i(i&#43;1)/2&#43;j 当i>&#61;j;
k
j(j&#43;1)/2&#43;i 当i
设有一个10阶的对称矩阵A,采用行优先压缩存储方式&#xff0c;a11为第一个元素&#xff0c;其存储地址为1&#xff0c;每个元素占一个字节空间&#xff0c;则a85的地址为&#xff08;33&#xff09;
算法描述
void matrlxmult(int a[],intb[],int[c][20],int n)
{ //n为A,B矩阵的下三角元素个数&#xff0c;a,b分别是一维数组
//存放矩阵a和b的下三角元素值&#xff0c;c存放a和b的乘积
for(i&#61;0;i<20;i&#43;&#43;)
for(j&#61;0;j<20;j&#43;&#43;)
{
s&#61;0;
for(k&#61;0;k
if(i>&#61;k) //表示元素为下三角的元素&#xff0c;计算在a数组中的下标
L1&#61;i*(i&#43;1)/2&#43;k;
else //表示元素为上三角的元素&#xff0c;计算下标
L1&#61;k*&#xff08;k&#43;1&#xff09;/2&#43;i;
if(k>&#61;j) //表示元素为下三角的元素&#xff0c;计算在b数组中的下表
L2&#61;K*(k&#43;1)/2&#43;j;
else
L2&#61;j*&#xff08;j&#43;1&#xff09;/2&#43;k;
s&#61;s&#43;a[L1]*b[L2]; //计算矩阵乘积
}
c[i][j]&#61;s;
}
}
a00 c c c c a00 a01 a02 … a0n-1
a10 a12 c c c c a11 a12 … a1n-1
a20 a21 … …c c c c a22 … a2n-1
2… … … … c c … … … …
an-10 an-11 an-12 … an-1n-1 c … … c an-1n-1
一般情况下&#xff0c;三角矩阵的常数c均为零。
三角矩阵可压缩存储到数组M[n(n&#43;2)/2&#43;1]中。
上三角矩阵中&#xff0c;主对角线上的第i行有n-i&#43;1个元素&#xff0c;以行序为主序存放&#xff0c;M[K]和aij的对应关系是&#xff1a;
n&#43;n-1&#43;n-2… &#61; i(2n-i&#43;2)/2&#43;j-i 当i<&#61;j
k &#61;
n&#xff08;n&#43;1&#xff09;/2 当 i>j
i(i&#43;1)/2 当i>&#61;j
k &#61;
n(n&#43;1)/2 当i
1、假设一个10阶的上三角矩阵A按行优先顺序压缩存储在一维数组B中&#xff0c;若矩阵中的第一个元素a11在B中的存储位置k&#61;0,则元素a55在B中的存储位置K _______34 .
二、稀疏矩阵
1、稀疏矩阵的定义
含有大量的零元素且零元素分布没有规律矩阵称为稀疏矩阵。
2、三元组表
&#xff08;1&#xff09;三元组表的含义&#xff1a;一个稀疏矩阵可用一个三元组线性表表示&#xff0c;每个三元组元素对应稀疏矩阵中的一个非零元素&#xff0c;包含有该元素的行号、列号和元素值。每个三元组表中是按照行号值的升序为主序、列号值的升序为辅序&#xff08;即行号值相同再按列号值顺序&#xff09;排列的。
0 0 1 0
0 5 0 0
0 0 0 0
-4 0 0 -7
i j v
0 2 1
1 1 5
3 0 -4
3 3 -7
#define Maxsize 1000 //假设非零元素个数最大为1000个
typedef struct
{
int i,j; //非零元素的行号、列号&#xff08;下标&#xff09;
DataType v; //非零元素值
}TriTupleNode;
typedef struct
{
TriTupleNode data[Maxsize]; //存储三元组的数组
int m,n,t; //矩阵的行数、列数和非零元素个数
}TSmatrix; //稀疏矩阵类型
假设A为一个稀疏矩阵&#xff0c;其数据存储在二维数组a中&#xff0c;b为一个存放对应于A矩阵生成的三元组表。在这个算法中&#xff0c;要进行二重循环来判断每个矩阵元素是否为零&#xff0c;若不为零&#xff0c;则将其行&#xff0c;列下标及其值存入b中。
void CreateTriTable(TSMatrix *b,inta[][5],int m,int n)
{//建立稀疏矩阵的三元组表
int i&#xff0c;j,k&#61;0;
for&#xff08;i&#61;0;i
{
b->data[k].i&#61;i;
b->data[k].j&#61;j;
b->data[k].v&#61;a[i][j];
k&#43;&#43;;
}
b->m&#61;m;b->n&#61;n; //记录矩阵的行数
b->t&#61;k; //保存非零个数
}
对于一个mn的矩阵M&#xff0c;它的转置矩阵T是一个nm的矩阵&#xff0c;而且Mij&#61;Tji(0<&#61;i0 3 0 5 0 0 0 1 0
0 0 -2 0 0 3 0 0 0
0 0 8 0 0 5 0 0 0
0 0 6 0
稀疏矩阵M和它的转置矩阵T
i j v
0 0 1 3
1 0 3 5
2 1 2 -2
3 2 0 1
4 2 4 6
5 3 2 8i j v
1 1 0 3
2 2 1 -2
3 2 3 8
4 3 0 5
5 4 2 6
算法思想 对M中的每一列col(0<&#61;col<&#61;a.n-1)从头至尾依次扫描三元组表&#xff0c;行号和列号互换后再依次存入b->data中就可以得到T的按行优先的三元组表。
算法描述
void TransMatrix(TSMatrix a,TSMatrix b)
{
//a和b是矩阵M/T的三元组表表示&#xff0c;求稀疏矩阵M的转置T
int p,q,col;
b->m&#61;a.n;b->n&#61;a.m; //M和T行列数互换
b->t&#61;a.t; //赋值非零元素个数
if&#xff08;b->t<&#61;0&#xff09;
printf(“M中无非零元素&#xff01;”)
else
{
q&#61;0;
for(col&#61;0;col
{
b->data[q].i&#61;a.data[p].j;
b->data[q].j&#61;a.data[p].i;
b->data[q].v&#61;a.data[p].v;
&#43;&#43;q;
}
}
}
算法分析 该算法的时间复杂度为O&#xff08;nt&#xff09;,即与稀疏矩阵M的历史和非零元素个数的乘积成正比。一般的矩阵转置算法的时间复杂度为O(mn).该算法仅适用于非零元素个数t远小于矩阵元素个数m*n的情况。
算法思想 创建两个数组num和rownext。num[j]存放矩阵第j列商非零元素个数&#xff0c;rownext[i]代表转置矩阵第i行的下一个非零元素在b中的位置。
算法描述
void FaStTran(TSMatfix a,TSMatrix *b)
{
int col,p,t,q;
int *num,*rownextl
num&#61;(int *)calloc(a.n&#43;1,4); //分配n&#43;1个长度为4的连续空间
rownext&#61;&#xff08;int *&#xff09;calloc&#xff08;a.m&#43;1,4&#xff09;; //分配m&#43;1个长度为4的连续空间
b->m&#61;a.n;b->n&#61;a.m;b->t&#61;a.t;
if(b->t)
{
for(col&#61;0;col
for(t&#61;0;t
rownext[0]&#61;0;
for(col&#61;1;col
for(p&#61;0;p
col&#61;a.data[p].j;
q&#61;rownext[col];
b->data[q].i&#61;a.data[p].j;
b->data[q].j&#61;a.data[p].i;
b->data[q].v&#61;a.data[p].v;
&#43;&#43;rownext[col]; //下次再有该行元素&#xff0c;起始点就比商一个加了1
}
}
}
算法分析 算法的时间复杂度为0&#xff08;t&#xff09;
带行表的三元组表&#xff1a;又称为行逻辑连接的顺序表。在按行优先存储的三元组表中&#xff0c;增加一个存储每一行的第一个非零元素在三元组表中位置的数组。
类型描述
typdef struct
{
TriTupleNode data[MaxSize];
int RowTab[MaxRow]; //每行第一个非零元素的位置表
int m,n,t;
}RLSMatrix;
带行表的三元组表的特点&#xff1a;
1.对于任给行号i&#xff08;0<&#61;i<&#61;m-1),能迅速地确定该行的第一个非零元在三元组表中的存储位置为RowTab[i]
2.RowTabi表示第i行之前的所有行的非零元素
3.第i行商的非零元数目为RowTab[i&#43;1]-RowTabi
4.最后一行即第m-1行的非零元数目为t-RowTabm-1
若在行表中令RowTab[m]&#61;t(要求MaxRow>m)会更方便些&#xff0c;且t可省略
带行表的三元组表可改进矩阵的转置算法&#xff0c;具体参阅其他参考书。
1、对于下列稀疏矩阵&#xff08;注矩阵元素的行列下标均从1开始&#xff09;
0 0 0 0 0
0 7 -1 0 0
-8 0 5 0 0
0 0 0 0 0
0 0 6 -2 9
&#xff08;2&#xff09;画出三元组表的行表
答案
&#xff08;1&#xff09;三元组表
i j v
0 2 2 7
1 2 3 -1
2 3 1 -8
3 3 3 5
4 5 3 6
5 4 4 -2
6 5 5 9
0 0 2 2 4
一、广义表的定义
广义表是线性表的推广。即广义表中放松对表元素的原子限制&#xff0c;容许它们具有其自身结构。
1、广义表定义
广义表是n(n>&#61;0)个元素a1,a2…ai,…an的有限序列。
其中;
(1)ai- - 或是原子或是一个广义表
&#xff08;2&#xff09;广义表通常记作&#xff1a;
Ls&#61;(a1,a2,a3…ai,…an).
(3)Ls是广义表的名字&#xff0c;n为它的长度
&#xff08;4&#xff09;若ai是广义表&#xff0c;则称它为Ls字表
&#xff08;5&#xff09;一个表展开后所含括号的层数称为广义表的深度
注意&#xff1a;
(1)广义表通常用圆括号括起来&#xff0c;用逗号分隔其中的元素
(2)为了区分原子和广义表&#xff0c;书写时用大写字母表示广义表&#xff0c;用小写字母表示原子
(3)若广义表Ls非空&#xff08;n>-1&#xff09;,则a1是Ls的表头&#xff08;head&#xff09;,其余元素组成的表&#xff08;a1,a2…an&#xff09;称为Ls的表尾&#xff08;tail&#xff09;.
(4)广义表是递归定义的
&#xff08;1&#xff09;A&#61;()–A是一个空表&#xff0c;其长度为零&#xff0c;深度为1.
&#xff08;2&#xff09;B&#61;(a)- - B是一个只有一个原子的广义表&#xff0c;其长度为1深度为1
&#xff08;3&#xff09;C&#61;(a,(b,c))- - C是一个长度为2的广义表&#xff0c;第一个元素是原子&#xff0c;第二个元素是字表&#xff0c;深度是2
&#xff08;4&#xff09;D&#61;(A,B,C)&#61;(&#xff08;&#xff09;&#xff0c;&#xff08;a&#xff09;,(a,(b,c)))- - D是一个长度为三深度为三的广义表、
&#xff08;5&#xff09;E&#61;(C,d)&#61;((a,(b,c)),d)- - E是一个长度为2的广义表&#xff0c;第一个元素是子表&#xff0c;第二个元素是原子&#xff0c;深度为3
&#xff08;6&#xff09;F&#61;(e,F)&#61;(e,(e,(e,…)))- - 是一个递归的表&#xff0c;它的长度是2&#xff0c;第一个元素是原子&#xff0c;第二个元素是表自身&#xff0c;展开后它是一个无限循环的广义表&#xff0c;深度为正无穷。
&#xff08;1&#xff09;广义表的元素可以是字表&#xff0c;而字表又可以含有字表&#xff0c;因此广义表是一个多层次结构的表&#xff0c;它可以用图形象的表示。
广义表是对线性表和树的推广&#xff0c;广义表的大部分运算与这些数据结构上的运算类似。因此&#xff0c;只讨论广义表的两个特殊的基本运算&#xff1a;
取表头head(Ls)和取表尾tail&#xff08;Ls&#xff09;.任何一个非空的广义表其表头可能是原子&#xff0c;也可能是字表&#xff0c;二其表尾一定是子表。
例已知有下列的广义表&#xff0c;试求出下面广义表的表头head()/表尾tail()、表长length&#xff08;&#xff09;和深度depth&#xff08;&#xff09;。
&#xff08;1&#xff09;A&#61;(a,(b,c,d),e,(f,g)) (2)B&#61;&#xff08;&#xff08;a&#xff09;&#xff09;;
(3)C&#61;(y,(z,w),(x,(z,w),a)); (4)D&#61;&#xff08;x&#xff0c;&#xff08;&#xff08;y&#xff09;,b&#xff09;,D&#xff09;。
(1)head&#61;a tail&#61; length&#61;4 depth&#61;2
(2)head&#61;(a) tail&#61; length&#61;1 depth&#61;2
(3)head&#61;y tail&#61; length&#61;3 depth&#61;3
(4)head&#61;x tail&#61;D length&#61;3 depth&#61;无穷
取出广义表A&#61;((x,y,z),(a,b,c,d))中原子b的函数是 ______.tail(head&#xff08;tail&#xff08;A&#xff09;&#xff09;)
1、结点结构
tag data/slink link
说明&#xff1a;&#xff08;1&#xff09;tag标志位&#xff0c;tag&#61;1,该结点是字表&#xff0c;第二个域为slink,用以存放字表的地址&#xff1b;当tag&#61;0时&#xff0c;该结点是原子结点&#xff0c;第二个域为data。用以存放元素值。
&#xff08;2&#xff09;link域是用来存放与本元素同一层的下一个元素对应结点的地址&#xff0c;当该元素是所在层的最后一个元素是&#xff0c;link的值为NULL.
例
A&#61;()
A&#61;NULL
B&#61;&#xff08;a&#xff09;
B----->0 a ^
c&#61;(a,(b,c))
D&#xff08;A,B,C&#xff09;&#61;((),(a),(a))
前两张讨论的是线性表、栈和队列都是典型的线性结构&#xff0c;结构中数据元素都是不能分解的非结构的原子类型。他们的逻辑特征是&#xff1a;每个数据元素至多有一个直接前趋和直接后续。而多维数组和广义表是一种复杂的线性结构&#xff0c;他们的逻辑特征是;一个数据元素可能有多个直接前驱和直接后继。
多维数组可以看成是线性表的推广。因为一旦确定数组是按行或案列优先顺序存储之后&#xff0c;每个数组元素之间的关系就同一位数组一样变成线性的了。
因此&#xff0c;只要弄清楚多维数组按行优先顺序存储结构之后&#xff0c;它的运算就同线性表运算类似。
本章主要介绍数组的逻辑结构特征及其存储方法、特殊矩阵和稀疏矩阵的压缩存储方法&#xff0c;压缩存储特殊矩阵和稀疏聚餐的各种运算及应用。以及广义表的逻辑结构&#xff0c;表的表头及表尾的求解。
第一节 输的基本概念和术语
一、引言
树形结构是一类重要的非线性数据结构&#xff0c;树中结点之间具有明确的层次关系&#xff0c;并且结点之间有分支&#xff0c;非常类似于真正的树。树形结构在客观世界中大量存在&#xff0c;如行政组织机构和人类社会家谱等都可以用树形结构形象表示。
1、树Tree 是n(n>&#61;)个结点的有限集T,n&#61;0时称为空树&#xff0c;任意非空树
&#xff08;1&#xff09;有且仅有一个特定的称为根&#xff08;Root&#xff09;的结点。
&#xff08;2&#xff09;n>1时&#xff0c;除根结点外的其余结点可分为m(m>&#61;0)个互不交互的子集T1,T2…Tm,其中每个子集本身又是一颗树&#xff0c;并称为根的子树&#xff08;Subtree&#xff09;
2、从逻辑上看&#xff0c;树型结构具有以下特点&#xff1a;
&#xff08;1&#xff09;任何非空树中有且仅有一个结点没有前驱结点&#xff0c;这个结点就是树的根结点
&#xff08;2&#xff09;除根结点之外&#xff0c;其余所有结点有且仅有一个直接前驱结点
&#xff08;3&#xff09;包括根结点在内&#xff0c;每个结点可以有多个直接后继结点。
&#xff08;4&#xff09;树形结构是一种具有递归特征的数据结构
&#xff08;5&#xff09;树形结构中的数据元素之间存在的关系通常是一对多&#xff0c;或者多对一的关系
(2)树的度&#xff1a;树中结点度的最大值。
(3)叶子&#xff1a;度为0的结点
(4)分支结点&#xff1a;度不为0的结点。除根及诶点之外的分支结点统称为内部及诶点。根及诶点又称为开始结点
(5)孩子&#xff1a;结点的直接后继&#xff08;结点的子树的根&#xff09;
(6)双亲&#xff1a;结点直接前趋
(7)兄弟&#xff1a;同一双亲的孩子互为兄弟
(8)子孙&#xff1a;一颗树上的任何结点称为根的子孙
(9)祖先&#xff1a;从根结点开始到该及诶点连线上的所有结点都是该结点的祖先
(10)路径&#xff1a;树中存在一个结点序列k1&#xff0c;k2…ki&#xff0c;使得ki是ki&#43;1的双亲&#xff08;1《i
注意&#xff1a;
若一个结点序列是路径&#xff0c;则在树的树形图表示中&#xff0c;该结点序列’自上而下‘地通过路径上的每条边。
(11)结点的层&#xff1a;设跟结点的层数为1&#xff0c;其余结点的层数等于双亲结点的层数加1。
(12)输的高度&#xff08;或深度&#xff09;&#xff1a;树中所有结点层数的最大值。
(13)有序树和无序树&#xff1a;将树中每个结点的各子树看成是从左到右有次序的&#xff08;即不能互换&#xff09;&#xff0c;则称该树为有序树&#xff1b;否则称为无序树。
(14)森林&#xff1a;是m(m>&#61;0)棵互不相交的树的集合。树和森林的概念相近&#xff0c;删去一棵树的根&#xff0c;就得到一个森林&#xff1b;反之加上一个节点做为根&#xff0c;森林变成一棵树。




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有