一、nutch1.2
二、nutch1.5.1
三、nutch2.0
四、配置SSH
五、安装Hadoop Cluster(伪分布式运行模式)并运行Nutch
六、安装Hadoop Cluster(分布式运行模式)并运行Nutch
七、配置Ganglia监控Hadoop集群和HBase集群
八、Hadoop配置Snappy压缩
九、Hadoop配置Lzo压缩
十、配置zookeeper集群以运行hbase
十一、配置Hbase集群以运行nutch-2.1(Region Servers会因为内存的问题宕机)
十二、配置Accumulo集群以运行nutch-2.1(gora存在BUG)
十三、配置Cassandra 集群以运行nutch-2.1(Cassandra 采用去中心化结构)
十四、配置MySQL 单机服务器以运行nutch-2.1
十五、nutch2.1 使用DataFileAvroStore作为数据源
十六、nutch2.1 使用AvroStore作为数据源
十七、配置SOLR
十八、Nagios监控
十九、配置Splunk
二十、配置Pig
二十一、配置Hive
二十二、配置Hadoop2.x集群
一、nutch1.2
步骤和二大同小异,在步骤 5、配置构建路径 中需要多两个操作:在左部Package Explorer的 nutch1.2文件夹上单击右键 > Build Path > Configure Build Path... > 选中Source选项 > Default output folder:修改nutch1.2/bin为nutch1.2/_bin,在左部Package Explorer的 nutch1.2文件夹下的bin文件夹上单击右键 > Team > 还原
二中黄色背景部分是版本号的差异,红色部分是1.2版本没有的,绿色部分是不一样的地方,如下:
1、Add JARs... > nutch1.2 > lib ,选中所有的.jar文件 > OK
2、crawl-urlfilter.txt
3、将crawl -urlfilter.txt.template改名为crawl -urlfilter.txt
4、修改crawl-urlfilter.txt,将
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
# skip everything else
-.
5、cd /home/ysc/workspace/nutch1.2
nutch1.2是一个完整的搜索引擎,nutch1.5.1只是一个爬虫。nutch1.2可以把索引提交给SOLR,也可以直接生成LUCENE索引,nutch1.5.1则只能把索引提交给SOLR:
1、cd /home/ysc
2、wget
http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-7/v7.0.29/bin/apache-tomcat-7.0.29.tar.gz
3、tar -xvf apache-tomcat-7.0.29.tar.gz
4、在左部Package Explorer的 nutch1.2文件夹下的build.xml文件上单击右键 > Run As > Ant Build... > 选中war target > Run
5、cd /home/ysc/workspace/nutch1.2/build
6、unzip nutch-1.2.war -d nutch-1.2
7、cp -r nutch-1.2 /home/ysc/apache-tomcat-7.0.29/webapps
8、vi /home/ysc/apache-tomcat-7.0.29/webapps/nutch-1.2/WEB-INF/classes/nutch-site.xml
加入以下配置:
searcher.dir
/home/ysc/workspace/nutch1.2/data
9、vi /home/ysc/apache-tomcat-7.0.29/conf/server.xml
将
cOnnectionTimeout="20000"
cOnnectionTimeout="20000"
10、cd /home/ysc/apache-tomcat-7.0.29/bin
关于nutch1.2更多的BUG修复及资料,请参看我在CSDN发布的资源:
http://download.csdn.net/user/yangshangchuan
二、nutch1.5.1
1、下载并解压eclipse(集成开发环境)
下载地址:
http://www.eclipse.org/downloads/,下载Eclipse IDE for Java EE Developers
2、安装Subclipse插件(SVN客户端)
插件地址:
http://subclipse.tigris.org/update_1.8.x,
3、安装IvyDE插件(下载依赖Jar)
插件地址:
http://www.apache.org/dist/ant/ivyde/updatesite/
4、签出代码
File > New > Project > SVN > 从SVN 检出项目
创建新的资源库位置 > URL:
https://svn.apache.org/repos/asf/nutch/tags/release-1.5.1/ > 选中URL > Finish
弹出New Project向导,选择Java Project > Next,输入Project name:nutch1.5.1 > Finish
5、配置构建路径
在左部Package Explorer的 nutch1.5.1文件夹上单击右键 > Build Path > Configure Build Path...
> 选中Source选项 > 选择src > Remove > Add Folder... > 选择src/bin, src/java, src/test 和 src/testresources(对于插件,需要选中src/plugin目录下的每一个插件目录下的src/java , src/test文件夹) > OK
切换到Libraries选项 >
Add Class Folder... > 选中nutch1.5.1/conf > OK
Add JARs... > 需要选中src/plugin目录下的每一个插件目录下的lib目录下的jar文件 > OK
Add Library... > IvyDE Managed Dependencies > Next > Main > Ivy File > Browse > ivy/ivy.xml > Finish
切换到Order and Export选项>
选中conf > Top
6、执行ANT
在左部Package Explorer的 nutch1.5.1文件夹下的build.xml文件上单击右键 > Run As > Ant Build
在左部Package Explorer的 nutch1.5.1文件夹上单击右键 > Refresh
在左部Package Explorer的 nutch1.5.1文件夹上单击右键 > Build Path > Configure Build Path... > 选中Libraries选项 > Add Class Folder... > 选中build > OK
7、修改配置文件nutch-site.xml 和regex-urlfilter.txt
将nutch-site.xml.template改名为nutch-site.xml
将regex-urlfilter.txt.template改名为regex-urlfilter.txt
在左部Package Explorer的 nutch1.5.1文件夹上单击右键 > Refresh
将如下配置项加入文件nutch-site.xml:
http.agent.name
nutch
http.content.limit
-1
修改regex-urlfilter.txt,将
# accept anything else
+.
替换为:
+^http://([a-z0-9]*\.)*news.163.com/
-.
8、开发调试
在左部Package Explorer的 nutch1.5.1文件夹上单击右键 > New > Folder > Folder name: urls
在刚新建的urls目录下新建一个文本文件url,文本内容为:
http://news.163.com
打开src/java下的org.apache.nutch.crawl.Crawl.java类,单击右键Run As > Run Configurations > Arguments > 在Program arguments输入框中输入: urls -dir data -depth 3 > Run
在需要调试的地方打上断点Debug As > Java Applicaton
9、查看结果
查看segments目录:
打开src/java下的org.apache.nutch.segment.SegmentReader.java类
单击右键Run As > Java Applicaton,控制台会输出该命令的使用方法
单击右键Run As > Run Configurations > Arguments > 在Program arguments输入框中输入: -dump data/segments/* data/segments/dump
用文本编辑器打开文件data/segments/dump/dump查看segments中存储的信息
查看crawldb目录:
查看linkdb目录:
11、索引和搜索
cp ${NUTCH_RUNTIME_HOME}/conf/schema.xml ${APACHE_SOLR_HOME}/example/solr/conf/
修改${APACHE_SOLR_HOME}/example/solr/conf/solrconfig.xml,将里面的text 都替换为content
把${APACHE_SOLR_HOME}/example/solr/conf/schema.xml中的 修改为
http://127.0.0.1:8983/solr/admin/
cd /home/ysc/workspace/nutch1.5.1/runtime/local
执行完整crawl:
使用以下命令分页查看所有索引的文档:
12、查看索引信息
13、配置SOLR的中文分词
推荐阅读
原文地址:http:blog.csdn.netchichengitarticledetails9235157http:blog.csdn.netnjpjsoftdevarticle ...
[详细]
蜡笔小新 2023-10-11 18:30:46
如何在mysqlshell命令中执行sql命令行本文介绍MySQL8.0shell子模块Util的两个导入特性importTableimport_table(JS和python版本 ...
[详细]
蜡笔小新 2023-10-17 08:53:00
本文介绍了解决Netty拆包粘包问题的一种方法——使用特殊结束符。在通讯过程中,客户端和服务器协商定义一个特殊的分隔符号,只要没有发送分隔符号,就代表一条数据没有结束。文章还提供了服务端的示例代码。 ...
[详细]
蜡笔小新 2023-12-14 18:02:45
本文详细介绍了搭建Windows Server 2012 R2 IIS8.5+PHP(FastCGI)+MySQL环境的步骤,包括环境说明、相关软件下载的地址以及所需的插件下载地址。 ...
[详细]
蜡笔小新 2023-12-14 17:03:58
本文介绍了如何使用php限制数据库插入的条数并显示每次插入数据库之间的数据数目,以及避免重复提交的方法。同时还介绍了如何限制某一个数据库用户的并发连接数,以及设置数据库的连接数和连接超时时间的方法。最后提供了一些关于浏览器在线用户数和数据库连接数量比例的参考值。 ...
[详细]
蜡笔小新 2023-12-14 14:06:10
本文介绍了如何使用C#制作Java+Mysql+Tomcat环境安装程序,实现一键式安装。通过将JDK、Mysql、Tomcat三者制作成一个安装包,解决了客户在安装软件时的复杂配置和繁琐问题,便于管理软件版本和系统集成。具体步骤包括配置JDK环境变量和安装Mysql服务,其中使用了MySQL Server 5.5社区版和my.ini文件。安装方法为通过命令行将目录转到mysql的bin目录下,执行mysqld --install MySQL5命令。 ...
[详细]
蜡笔小新 2023-12-12 19:29:55
本文介绍了大数据Hadoop生态(20)MapReduce框架原理OutputFormat的开发笔记,包括outputFormat接口实现类、自定义outputFormat步骤和案例。案例中将包含nty的日志输出到nty.log文件,其他日志输出到other.log文件。同时提供了一些相关网址供参考。 ...
[详细]
蜡笔小新 2023-12-10 11:44:06
前言相信大家对ZooKeeper应该不算陌生。但是你真的了解ZooKeeper是个什么东西吗?如果别人面试官让你给他讲讲ZooKeeper是个什么东西, ...
[详细]
蜡笔小新 2023-10-17 17:07:40
Hdfs的数据模型在对读写流程进行分析之前,我们需要先对Hdfs的数据模型有一个简单的认知。数据模型如上图所示,在NameNode中有一个唯一的FSDirectory类负责维护文件 ...
[详细]
蜡笔小新 2023-10-17 11:27:29
2018-02-1420:07:13,610ERROR[main]regionserver.HRegionServerCommandLine:Regionserverexiting ...
[详细]
蜡笔小新 2023-10-16 20:08:57
TA(TencentAnalytics,腾讯分析)是一款面向第三方站长的免费网站分析系统,在数据稳定性、及时性方面广受站长好评,其秒级的实时数据更新频率也获得业界的认可。本文将从实 ...
[详细]
蜡笔小新 2023-10-16 19:05:20
nsitionalENhttp:www.w3.orgTRxhtml1DTDxhtml1-transitional.dtd ...
[详细]
蜡笔小新 2023-10-16 18:40:50
camelApacheSolr是建立在Lucene之上的“流行的,快速的开源企业搜索平台”。为了进行搜索(并查找结果),通常需要从不同的源(例如内容管理 ...
[详细]
蜡笔小新 2023-10-15 11:20:39
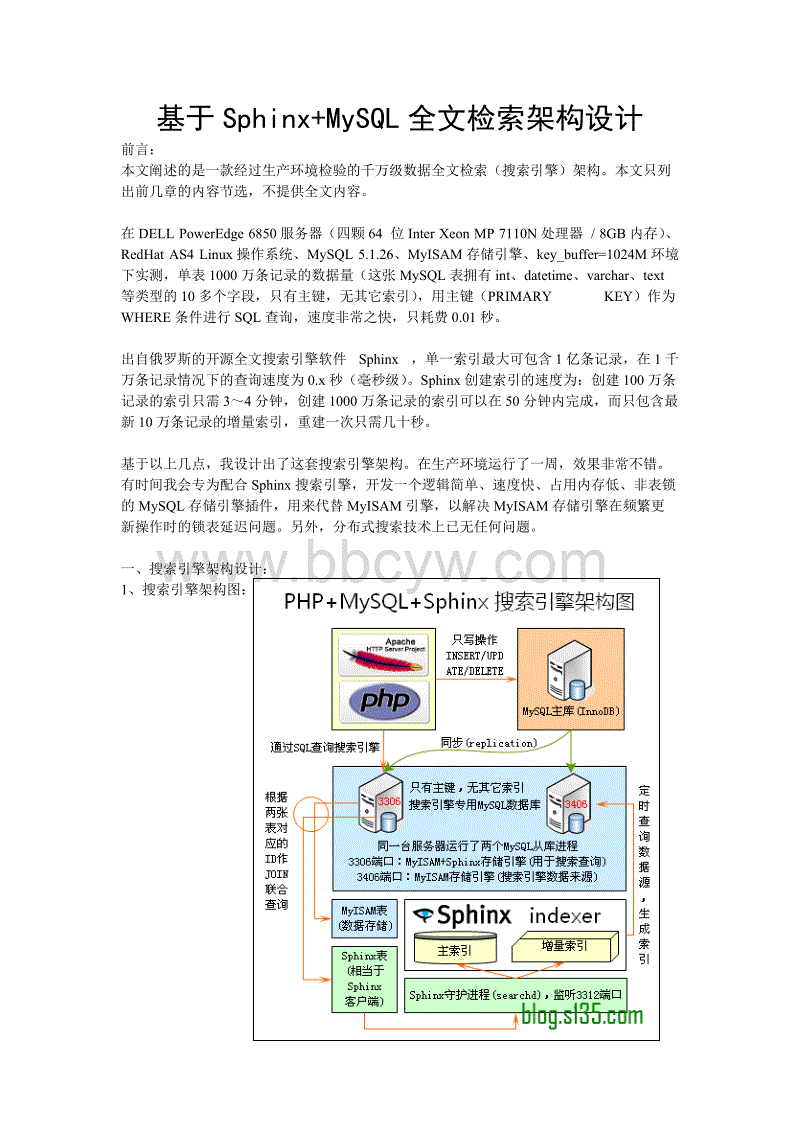
一、目标将MySQL数据库中的数据导入至Solr中,并且由Solr生成中文索引,使用Solr查询信息。二、数据导入1、将solr-8.2.0dist下的 ...
[详细]
蜡笔小新 2023-10-12 18:08:48
基于sphinxmysql全文检索架构设计.doc还剩2页未读,继续阅读下载文档到电脑,马上远离加班熬夜!亲,喜欢就下载吧& ...
[详细]
蜡笔小新 2023-10-12 12:34:51
Daro_olingke_572
这个家伙很懒,什么也没留下!








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有