这里我们使用zabbix对其进行监控,使用的是ss命令,不使用netstat命令,因为ss的速度快很多,不信的话可以去测一下哈,一台机器的socket越多,对比越明显。而且ss命令能显示更多的内容,其实我对这两个命令不是特别的熟悉,通过man ss可以看到:

ss命令用于显示socket状态. 他可以显示PACKET sockets, TCP sockets, UDP sockets, DCCP sockets, RAW sockets, Unix domain sockets等等统计. 它比其他工具展示等多tcp和state信息. 它是一个非常实用、快速、有效的跟踪IP连接和sockets的新工具.SS命令可以提供如下信息:
很多流行的Linux发行版都支持ss以及很多监控工具使用ss命令.熟悉这个工具有助于您更好的发现与解决系统性能问题.本人强烈建议使用ss命令替代netstat部分命令,例如netsat -ant/lnt等
直接ss命令

对上面解释一波:
Netid #socket类型,在上面的例子中,有 TCP、u_str(unix流)等套接字 State #套接字处于什么状态,下面是TCP套接字的所有状态及说明, 实际上就是TCP的三次握手和四次挥手的所有状态 Recv-Q #在 ESTAB 状态下,表示内核中还有多少字节的数据没有被上层应用读取,如果这里数值很大,应用程序可能发生了阻塞 Send-Q #在 ESTAB 状态下,表示内核发送队列中还有多少字节的数据没有收到确认的ACK,如果这个数值很大,表明接收端的接收以及处理需要加强 Local Address:Port #本地地址和端口 Peer Address:Port #远程地址和端口
然后我们接着看上面的state有哪些呢,如果特别熟悉网络的人应该很懂,至少我现在是不是特别熟悉,三次握手和四次挥手的状态:
LISTEN #服务端侦听套接字等待客户端的连接 SYN-SENT #客户端已发送套接字连接请求报文,等待连接被服务器接收 SYN-RECEIVED #服务器端接收连接请求报文后,等待客户端的确认连接的回复报文 ESTABLISHED #服务端和客户端之间成功建立了一条有效的连接,可以互相传输数据 FIN-WAIT-1 #服务器或客户端调用close函数主动向对方发出终止连接的请求报文,同时等待对方确认终止连接的回复报文 FIN-WAIT-2 #主动关闭连接端收到对方确认终止连接的回复报文,同时等待对方连接终止的请求报文,这时的状态是TCP连接的半关闭状态,可以接受数据,但是不能发送数据 CLOSE-WAIT #被动关闭端收到主动关闭端终止连接的请求报文后,向主动关闭端发送确认终止连接的回复报文,同时被动关闭端等待本地用户终止连接,这时被动关闭端的状态是TCP连接的半关闭状态,可以发送数据,但是不能接收数据 CLOSING #服务器和客户端同时向对方发送终止连接(调用close函数)请求报文,并且双方都是在收到对方发送的终止连接回复报文之前收到了对方的发送的终止连接请求报文,这个时候双方都进入了CLOSING状态,进入CLOSING状态之后,只要收到了对方对自己终止连接的回复报文,就会进入TIME-WAIT状态,所以CLOSING状态的持续时间会特别短,一般很难捕获到 LAST-ACK #被动关闭端发送完全部数据之后,向主动关闭端发送终止连接的请求报文,等待主动关闭端发送终止连接的回复报文 TIME-WAIT #主动关闭端收到被动关闭端终止连接的请求报文后,给被动关闭端发送终止连接的回复报文,等待足够时间以确保被动关闭端收到了主动关闭段发送的终止连接的回复报文 CLOSED #完全没有连接,套接字连接已经终止了
那么这些状态ss命令又怎么对应呢?(后面的是ss命令显示的状态信息)
[TCP_ESTABLISHED] = "ESTAB", [TCP_SYN_SENT] = "SYN-SENT", [TCP_SYN_RECV] = "SYN-RECV", [TCP_FIN_WAIT1] = "FIN-WAIT-1", [TCP_FIN_WAIT2] = "FIN-WAIT-2", [TCP_TIME_WAIT] = "TIME-WAIT", [TCP_CLOSE] = "UNCONN", [TCP_CLOSE_WAIT] = "CLOSE-WAIT", [TCP_LAST_ACK] = "LAST-ACK", [TCP_LISTEN] = "LISTEN", [TCP_CLOSING] = "CLOSING",
江到这里其实就可以去做下面的监控了,继续往下看ss命令的使用。
Usage: ss [ OPTIONS ]
       ss [ OPTIONS ] [ FILTER ]
-h, --help 帮助信息
-V, --version 程序版本信息
-n, --numeric 不解析服务名称
-r, --resolve 解析主机名
-a, --all 显示所有套接字(sockets)
-l, --listening 显示监听状态的套接字(sockets)
-o, --options 显示计时器信息
-e, --extended 显示详细的套接字(sockets)信息
-m, --memory 显示套接字(socket)的内存使用情况
-p, --processes 显示使用套接字(socket)的进程
-i, --info 显示 TCP内部信息
-s, --summary 显示套接字(socket)使用概况
-4, --ipv4 仅显示IPv4的套接字(sockets)
-6, --ipv6 仅显示IPv6的套接字(sockets)
-0, --packet 显示 PACKET 套接字(socket)
-t, --tcp 仅显示 TCP套接字(sockets)
-u, --udp 仅显示 UCP套接字(sockets)
-d, --dccp 仅显示 DCCP套接字(sockets)
-w, --raw 仅显示 RAW套接字(sockets)
-x, --unix 仅显示 Unix套接字(sockets)
-f, --family=FAMILY 显示 FAMILY类型的套接字(sockets),FAMILY可选,支持 unix, inet, inet6, link, netlink
-A, --query=QUERY, --socket=QUERY
QUERY := {all|inet|tcp|udp|raw|unix|packet|netlink}[,QUERY]
-D, --diag=FILE 将原始TCP套接字(sockets)信息转储到文件
-F, --filter=FILE 从文件中都去过滤器信息
FILTER := [ state TCP-STATE ] [ EXPRESSION ]
重点在下面的监控
做这个监控前可以熟悉下awk命令
这是使用的监控系统为zabbix,我们这里会结合zabbix的模板(这里选择模板是为了后期拓展),和自定义脚本的方式进行监控。
二话不多说上脚本先:
vim tcp_status.sh
#################脚本内容#################
#!/bin/bash
if [ $# -ne 1 ];then
echo "Follow the script name with an argument "
fi
case $1 in
LISTEN)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/LISTEN/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
ESTAB)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/ESTAB/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
CLOSE-WAIT)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/CLOSE-WAIT/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
TIME-WAIT)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/TIME-WAIT/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
SYN-SENT)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/SYN-SENT/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
SYN-RECV)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/SYN-RECV/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
FIN-WAIT-1)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/FIN-WAIT-1/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
FIN-WAIT-2)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/FIN-WAIT-2/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
UNCONN)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/UNCONN/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
LAST-ACK)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/LAST-ACK/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
CLOSING)
result=`ss -ant | awk "NR>1 {a[$1]++} END {for (b in a) print b,a[b]}" | awk "/CLOSING/{print $2}"`
if [ "$result" == "" ];then
echo 0
else
echo $result
fi
;;
esac
vim zabbix_agent.conf ##############添加如下内容################# UnsafeUserParameters=1 #这个参数是自定义脚本需要配置的 UserParameter=tcp.status[*],sh /home/zabbix/tcp_status.sh $1 #这里就是用来指定刚刚写的脚本,后面传一个参数
配置好了以后记得重启zabbix agent
往其中添加item,trigger,graph
新增模板,然后往其中添加item,如下图所示

上图中key中的tcp.status指的是刚刚在第二步中的配置UserParameter=tcp.status[*],sh /home/zabbix/tcp_status.sh $1
然后中括号里面的内容就是$1进行传参的参数,具体的参数就是[UNCONN]里面的UNCONN,这些值对应第一步监控脚本中的case中的每一种情况,到这里基本上完成了,不,还是画个图吧,在模板中添加graph,如下图所示:
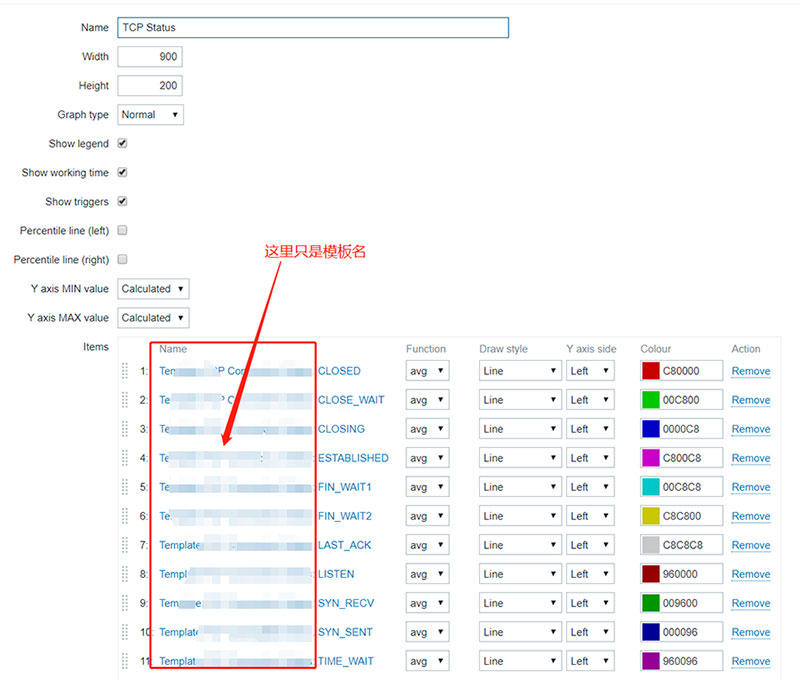
还有最重要的一步就是把配置好监控脚本的(第一步)的主机添加到该模板,到此为止这个监控就做完了,看个结果图吧
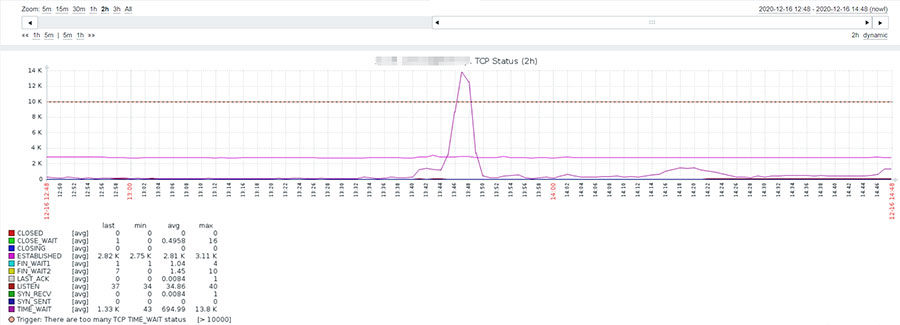
这个监控的目的就是看看到底是哪些机器访问目标机器比较频繁。
这个监控采用自发现的监控,比上面那个会难一点哈,为啥要选择自发现的监控呢,因为item不是确定的,这里选择:原地址ip和目的ip地址作为item,我们在目的ip地址进行监控,这个是不变的,所以原地址ip值会发生变化,所以这里采用的是自动生成item的方式进行监控,自动添加和删除item,其实挺好用的,只要学会了,超级简单
这里也是分为三步,写脚本,配置zabbix_agent.conf文件,配置Discovery
这里需要两个脚本,一个用来做自发现(需要输出json格式),一个用来做item的)
vim tcp_monitory.sh
##################tcp_monitor.sh##################
#!/bin/bash
#获取数据输出到data.txt文件中,格式为:原地址ip:count:目标地址ip
#并且过滤掉count小于200的数据,这里没有分socket的状态,眉毛胡子一把抓了,个人可以根据具体的需求改进
ip_addr=`ip addr | grep -w inet | grep -v "127.0.0.1" | awk "{print $2}"| awk -F "/" "{print $1}"`
ss -ant | awk "{ print $5}"|grep -Ev "127.0.0.1" | cut -d ":" -f4 | awk -v ip_addr=$ip_addr "NR>1 {++s[$1]} END {for(k in s)if(s[k]>=200){print k,s[k],ip_addr}}" | grep -E "^([0-9]{1,3}.){3}[0-9]" > /home/zabbix/data.txt
#执行Python脚本,这是为了输出json格式,
python /home/zabbix/get_json.py
#####################################
#如下是get_json.py的内容
##############get_json.py################
#!/usr/bin/env python
#coding=utf-8
import json
def create_json(path):
json_list = []
with open(path) as f:
for line in f.readlines():
dict = {}
split = line.split(" ")
dict["{#DES_IP}"] = split[0]
//dict["{#LINK_COUNT}"] = split[1] //这个是可以不要的
dict["{#SOU_IP}"] = split[2][:-1]
json_list.append(dict)
sum = {}
sum["data"] = json_list
sum = json.dumps(sum)
print sum
if __name__ == "__main__":
path = "/home/zabbix/data.txt"
create_json(path)
##############分割线:上面的是自发现的脚本###############
##############分割线:下面的是item相关脚本###############
vim tcp_item.sh
##################tcp_item.sh####################
#!/bin/bash
export LANG="en_US.UTF-8"
path=/home/zabbix/data.txt
count=`cat $path | grep $1 | grep $2 | awk "{print $2}"`
[ 1"$count" -eq 1 ] && echo 0 || echo $count
两个脚本都搞定了,就可以进行zabbix_agent.conf的配置了
在配置文件中新增如下内容:
UnsafeUserParameters=1 #如果已经配置就不需要配置了 UserParameter=discovery.tcp_monitor[*],sh /home/zabbix/tcp_monitor.sh #自发现 UserParameter=alert.tcp_count[*],sh /home/zabbix/tcp_item.sh $1 $2 #item,其中$1,$2为item中的传递参数,用来区别item的不同
这里还是选择在zabbix的模板上进行配置,现在新增一个Discovery
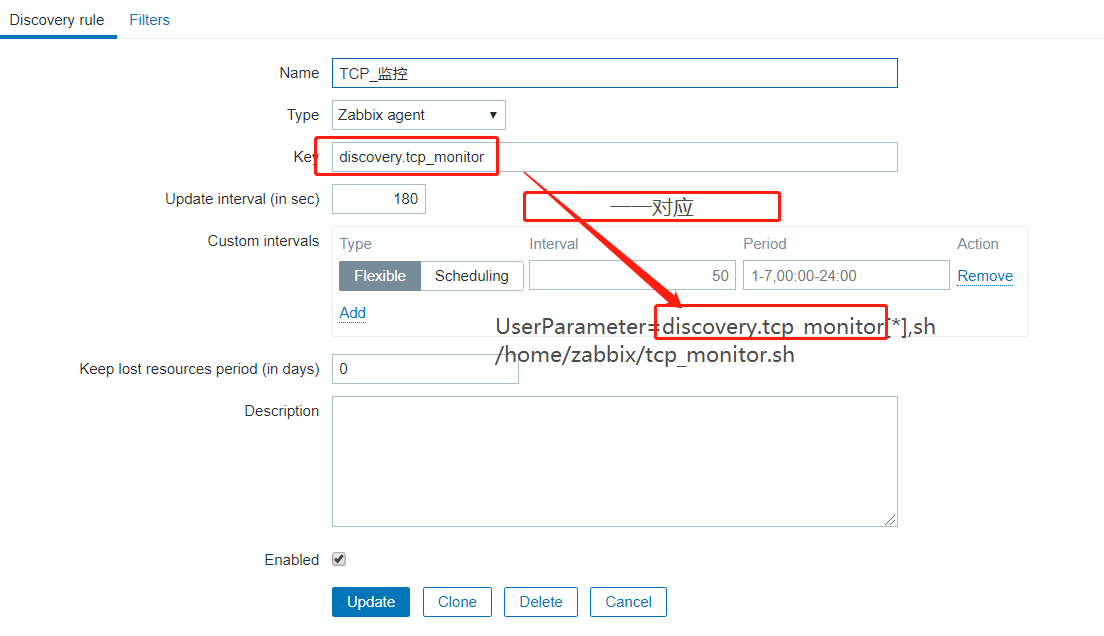
然后在Discovery上配置item,trigger,graph

配置item:
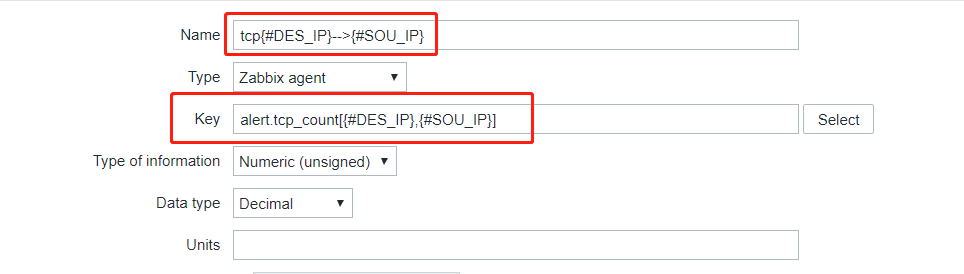
上面的DES_IP,SOU_IP来源于自发现脚本中的Python脚本,用于输出的格式。alter.tcp_count是UserParameter=alert.tcp_count[*],sh /home/zabbix/tcp_item.sh $1 $2,后面的$1,$2与DES_IP,SOU_IP相对应生成唯一确定的item。
item配置完毕后就可以配置trigger了:
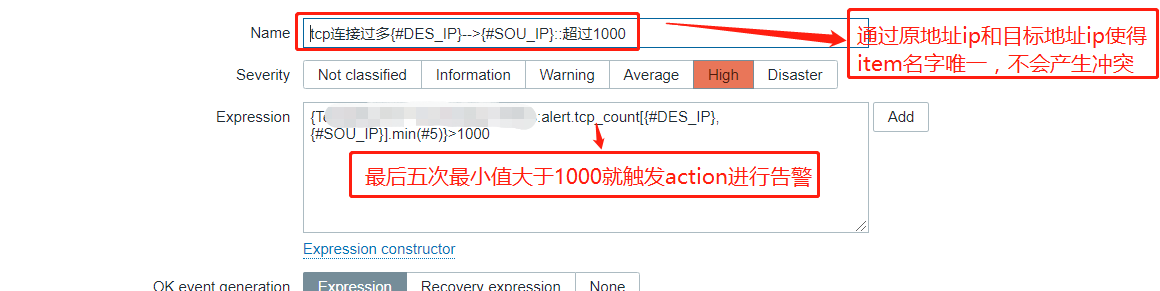
接下来继续配置graph了

最后把模板添加到机器,然后看结果

以上就是详解Linux使用ss命令结合zabbix对socket做监控的详细内容,更多关于Linux ss命令 zabbix socket监控的资料请关注编程笔记其它相关文章!









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有