作者:摄影师张恒 | 来源:互联网 | 2023-09-17 11:03
限流、熔断与降级限流、熔断与降级,此三者都是流量过大时,通过一定的方式去保护系统的手段,是应对海量服务的三大“神器”如上图所述中ServiceA是主调,有两个实例A1和A2。S
限流、熔断与降级
限流、熔断与降级,此三者都是流量过大时,通过一定的方式去保护系统的手段,是应对海量服务的三大“神器”
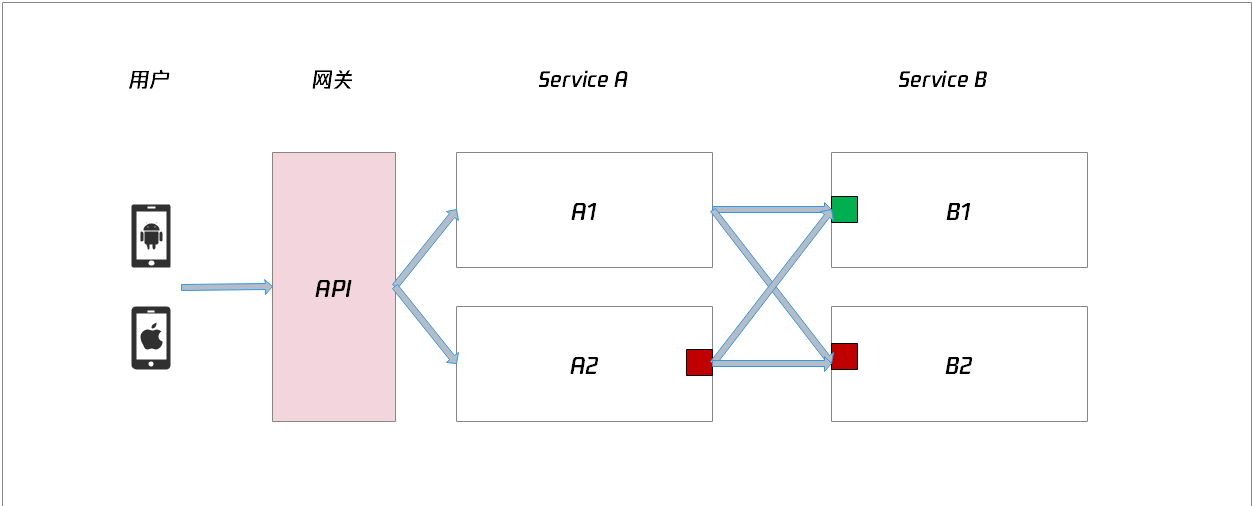
如上图所述中 ServiceA 是主调,有两个实例 A1 和 A2。ServiceB 是被调,也有两个实例 B1 和 B2。
限流:一般是在被调生效,即图中的绿色框框所处的位置
熔断:一般是在主调生效,也有一部分熔断设计是在被调生效的,如图中红色块所处的位置。
降级:一般的视角是从用户侧观察,所享有的服务变差了。限流和熔断都会带来降级。
1. 限流
限流是从系统的流量入口考虑,从进入的流量上进行限制,达到保护系统的作用
是指需要限制并发/请求量的场景(如秒杀等),通过限流保护服务免受雪崩之灾。
主流的限流算法有:
1.1 计数器
多少次每秒/每分/每天,根据作用范围的不同,计算器可以分为单机计数器即 Local Counter(每个机器都有自己的计数器)和全局计数器也就是分布式计数器即 Global Counter(所有机器公有一个计数器阈值)
大公司一般都有自己的限流组件(已经包括了单机和分布式计数器功能)
1.2 令牌桶

令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
1.3 漏桶

漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
一般限流需要配合压测来做,不然也不知道系统的负载极限在哪里。初期的做法是通过单一服务的压测或者全链路压测得到一个阈值(静态),该处做法就是简单,缺点是随着业务复杂度的上升静态阈值不能代表服务的真实服务能力,所以一般在活动或者大促前会组织一批压测。更好的做法是全链路压测日常化,然后随时来调整这个阈值。实现阈值从静态到动态的转变。
下面比较下限流的三种方法的区别
方法 |
优点 |
缺点 |
|---|
计数器 |
简单方便 |
存在一下子被刷完计数器的情况 |
令牌桶 |
可以处理瞬间突发的流量 |
~ |
漏桶 |
限制请求的平均速率 |
不能处理瞬间流量的情况,当流量把漏桶装满后,大部分的请求都会被丢弃掉 |
2. 熔断

如上图所示,熔断器首先是关闭的,当主调失败到达了一定阈值后,此时熔断器打开(主调的请求不会再到被调了,压根就不会发出请求),过了一个”冷却时间”后,熔断器此时会处于一个半开的状态,会有请求到被调,如果请求成功就关闭熔断器(后端服务恢复),否则就继续打开熔断器。熔断强调的是服务之间的调用能实现自我恢复的状态。
例如你的 A 服务里面的一个功能依赖 B 服务,这时候 B 服务出问题了,返回的很慢。这种情况可能会因为这么一个功能而拖慢了 A 服务里面的所有功能,因此我们这时候就需要熔断!即当发现 A 要调用这 B 时就直接返回错误(或者返回其他默认值),就不去请求B了
2.1 主调熔断
主调熔断是熔断的主要场景,在微服务中是结合服务注册和发现组件来使用的。主调通过服务发现组件来获取被调的实例,如果主调的失败达到了一个阈值,服务发现组件会熔断被调的实例。
2.2 被调熔断
被调熔断,被调实例获取当前的实例负载情况,如果 cpu/内存/io 等超过了一定的阈值,那么就会触发熔断,将抛弃进来的请求。此时熔断和限流比较像,一个是基于负载情况,一个是根据配置的阈值情况。
3. 降级
降级,是从系统内部的平级服务或者业务的维度考虑,流量大了,可以干掉一些,保护其他功能正常使用。
降级也就是服务降级,当我们的服务器压力剧增为了保证核心功能的可用性 ,而选择性的降低一些功能的可用性,或者直接关闭该功能。这就是典型的丢车保帅了。当服务暂时不可用或者影响到核心流程时,需要待高峰或者问题解决后再打开。通过降级实现部分可用、有损服务。主流的降级策略有基于 RT(响应时间)、异常比率和异常数的降级。
就比如贴吧类型的网站,当服务器吃不消的时候,可以选择把发帖功能关闭,注册功能关闭,改密码,改头像这些都关了,为了确保登录和浏览帖子这种核心的功能。
降级的手段大致有这么三种
`强一致变为最后一致,延迟服务
干掉一些次要功能
简化流程
每个服务都需要制定自己的降级策略,根据服务不同的优先级来设定降级方案。另外降级策略最好是由开关系统或者配置系统统一控制。一般而言都会建立一个独立的降级系统,可以灵活且批量的配置服务器的降级功能。当然也有用代码自动降级的,例如接口超时降级、失败重试多次降级等。具体失败几次,超时设置多久,由你们的业务等其他因素决定。开个小会,定个值,扔线上去看看情况。根据情况再调优。
综述
触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
限流是持续性的服务,逻辑一般在服务端。此时客户端请求到达了服务端,但是服务端根据规则进行了限制(比如直接报频率限制错)。1 分钟限额 10000 的话,如果前 50 秒来了 1 万,那么后 10 的请求都会直接返回。整体来看服务端的服务是持续的
熔断是非持续性的服务,逻辑一般在客户端。此时客户端的请求并没有到服务端。当客户端调用北极星获取后端的服务出现比较多的错误的时候(错误数或者错误率超过一定的阈值),北极星会将该节点熔断。一段时间客户端的服务请求都不会到达服务端,所以服务端的服务看起来是不连续的。
降级是从整体资源使用的角度来考虑的,实质是解决资源不足和访问增加的情况。当整体资源不够的时候,可以牺牲低优先级服务的体验来保证高优先级服务的使用体验。
熔断和限流都可以认为是降级的一种方式
关注公众号 [龗孖] 或搜索公众号[lingmaW] , 获得更多新干货!!!
- 本文链接: https://blog.lingma.top/2022/09/07/b14fe88b84fa/限流、熔断与降级/index.html
- 版权声明: 本博客所有文章除特别声明外,均采用 反996许可证版本1.0 许可协议。转载请注明出处!







 京公网安备 11010802041100号
京公网安备 11010802041100号