
©作者 | 邴立东、彭海韵、许璐、谢耀赓
单位 | 阿里巴巴达摩院自然语言智能实验室
研究方向 | 自然语言处理

ABSA 和 ASTE 任务简介
情感分析作为自然语言理解里最重要也是最有挑战的主要任务之一,有很大的研究空间和广阔的应用价值。细粒度的情感分析(i.e. Aspect-Based Sentiment Analysis(ABSA))的相关研究已历经多年,有大量的相关论文发表。
先给一个 ABSA 的例子,对于一句餐馆评论:“Waiters are very friendly and the pasta is simply average.”,提到了两个评论目标:“waiter”和“pasta”;用来评价他们的词分别是:“friendly”和“average”;这句话评论的分别是餐馆的“service”和“food”方面。
以上便是 ABSA 任务中处理的三类对象:aspect、opinion、aspect category。也就是下图中的最上层。从目标识别角度,针对 aspect term 和 opinion term,存在抽取问题;针对 aspect category,存在分类问题(假设预定义 aspect categories)。
从情感分析角度,对 aspect term 和 aspect category 存在情感分类问题。这些原子任务如下图中间层所示。注意,一句评论里可能没有显示提及 aspect term,但同样可以存在 aspect category,比如“I was treated rudely.”讲的是“service”。

在已有的工作中,研究者也探索了结合两个或以上原子任务,如上图底层所示。基于任务之间的耦合关系,期望联合任务能取得更优的效果。比如我们提出的在做 aspect extraction 的同时预测 sentiment 极性(对应于上图底层最左侧圆圈),这个任务被称作 End-to-End ABSA(E2E-ABSA)[1,2]。
Aspect 及其 sentiment 极性(即 E2E-ABSA 任务),与表明这个极性的 opinion term,这三者之间是紧密相关的。为此我们提出 Aspect Sentiment Triplet Extraction(ASTE)任务(对应于上图底层蓝色填充圆圈)[3],并发表于 AAAI 2020。
继此工作之后,我们又提出了两个新模型:Jointly Extracting Triplet(JET)[4] 和 Span-based ASTE(Span-ASTE)[5],分别发表于 EMNLP 2020 和 ACL 2021。为克服 AAAI 工作中两阶段模型的局限,JET 模型提出通过丰富标签语义来实现 End-to-End 的方法解决 ASTE。
而 Span-ASTE 则通过明确考虑 ASTE 任务中词组与词组之间的交互作用,避免了已有方法中抽取不完整和情感冲突的问题。同时,Span-ASTE 提出了双通道词组剪枝策略,通过结合 Aspect Term Extraction(ATE)和Opinion Term Extraction(OTE)任务的显式监督,以降低词组枚举造成的高计算成本。

ASTE任务的提出
本小节工作来自论文:
Knowing What, How and Why: A Near Complete Solution for Aspect-based Sentiment Analysis, In AAAI 2020.
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/6383/6239
数据代码:
https://github.com/xuuuluuu/SemEval-Triplet-data
2.1 问题定义
如前述,opinion term 和其描述的 aspect 以及 sentiment 高度相关。如果在抽取出 aspect 及预测出 sentiment 同时,能给出表明该 sentiment 的 opinion term,将会使结果更加完整:aspect 给出了带有情感的评论目标,sentiment 给出了对目标的情感极性,opinion term 给出了情感的原因,这三者依次回答了 What(对于什么),How(情感怎么样)以及 Why(为什么是这个情感)三个问题,对于评论目标构成更全面的分析。
正如开篇所讲述的那个例子,“Waiters are very friendly and the pasta is simply average.”,提到了两个评论目标:“waiter”和“pasta”。在理解目标的情感极性之上,知道导致情感的原因,既“friendly”和“average”,在现实场景中更具有实用性和指导性。
本工作中第一次定义了 Aspect Sentiment Triplet Extraction(ASTE)任务。这个 Triplet Extraction(三元组抽取)任务旨在抽取评论中出现的所有 aspect,对应的 sentiment 以及对应的 opinion term,并完成三者的匹配工作,形成(aspect, sentiment, opinion term)的三元组,如上例中的(waiter, Positive, friendly)和(pasta, Negative, average)。
2.2 相关方法的局限
正如开篇关于评论目标情感分析任务的总览图所示,本工作之前尚未有研究 Aspect Sentiment Triplet Extraction(ASTE)任务的工作。之前的工作最多研究了两个原子任务的结合:例如 aspect term extraction 和 sentiment classification 的结合 [1] [2],aspect term 和 opinion term 的联合抽取 [3] [4],aspect category 和 sentiment classification 的结合 [5]。[6] 尝试针对已知 aspect 进行 opinion term 抽取,[7] 的模块化系统也仅进行 aspect term extraction 和 sentiment classification,未提取 opinion term。
2.3 我们的模型
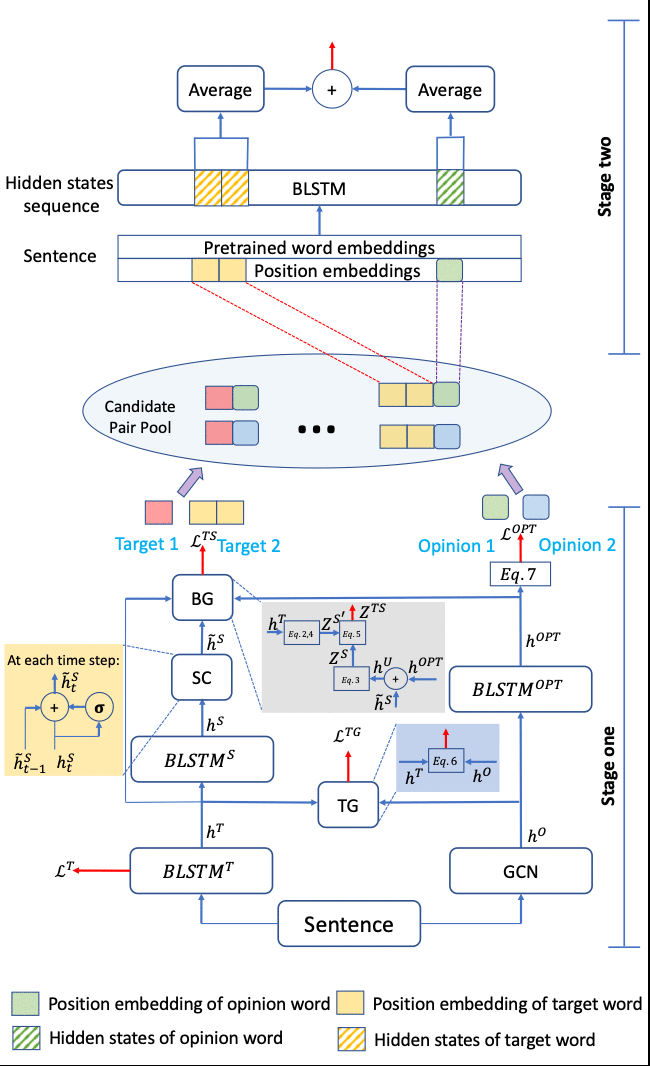
我们的设计采用了二阶段模型,如下模型图所示。第一阶段模型(stage one)主要分为两个部分:1. 预测所有评论目标词以及目标词的情感极性;2. 预测所有可能描述目标词的情感词。目标词以及带有其情感极性的标签主要由第一阶段模型的左侧结构标注得出。
句子向量通过第一层 Bi-LSTM 会进行一次序列预测来确定评论目标的范围,然后加以模型右侧图卷积网络(GCN)返回的情感词信息辅助输入第二层 Bi-LSTM 进行二次序列预测,由此获得带有情感极性的标签。描述目标词的情感词由模型第一阶段的右侧结构预测。具体地,句子向量首先通过两层图卷积网络加以模型左侧结构输出的主题词范围来确定相关的情感词。
然后将图卷积网络的隐状态输入 Bi-LSTM 层来进行情感词标签的预测。第一阶段模型是基于前述 E2E-ABSA 工作的改进。第二阶段模型(stage two)对第一阶段模型左侧输出的带情感的目标词和右侧输出的情感词进行配对。首先我们枚举可能出现的配对,加之文本信息以及目标词和情感词之间的距离信息通过分类器来确定哪些是有效的组合。
2.4 主要结果
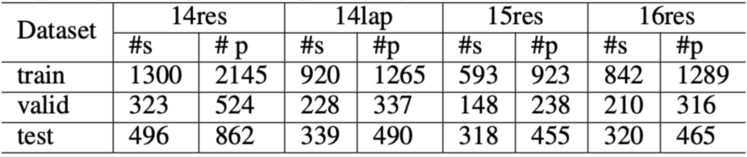
我们在现有 SemEval 14 Laptop 和 14,15,16 Restaurant 数据集上进行了补充标注。我们将同一个句子具有不同 aspects 和 opinons 标注的情形合并在一起,每个合成的数据包含原始句子,aspect 标注和 opinion 标注,并将它们配对,例如:
The best thing about this laptop is the price along with some of the newer features .
The=O best=O thing=O about=O this=O laptop=O is=O the=O price=T-POS alOng=O with=O some=O of=O the=O newer=O features=TT-POS .=O
The=O best=S thing=O about=O this=O laptop=O is=O the=O price=O alOng=O with=O some=O of=O the=O newer=SS features=O .=O
上例中包含两个 aspect-opinion 对:‘price’ —‘best’和‘feature’ —‘newer’。我们同时也清除了少量的 aspect 标注和 opinion 标注有重合的数据。最终数据集统计如下:
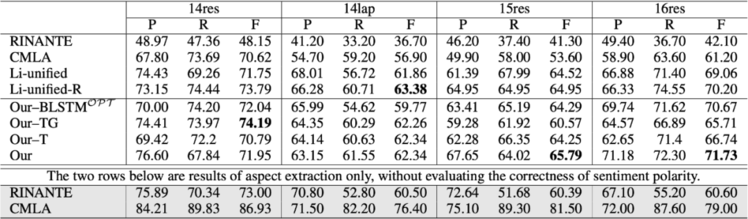
实验上,我们对模型的两阶段分别进行了验证。我们首先针对一阶段 unified aspect extraction 和 sentiment classification 进行了验证,结果如下表。我们的模型及变种全部优于现有方法,仅在 14lap 上稍逊于我们改进的 Li-unified [1] 方法。另外我们发现 RINANTE 和 CMLA 的实验结果较原文均大幅下滑,为公平起见,我们增设了最后两行的对比实验,参考以原文同样的实验设置。结果显示效果显著上升,一方面证明了我们复现的可靠性,另一方面佐证了三元组抽取任务的高难度。
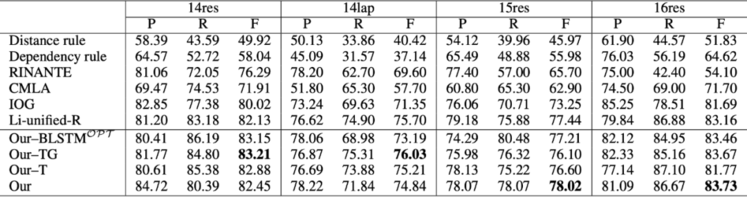
接下来,我们针对一阶段 opinion term extraction 进行了验证,结果如下表。我们的模型稳定地优于现有方法及其改进。证明了我们利用 aspect extraction 和 sentiment classification 来辅助 opinion term extraction 的设计的有效性。
最后我们进行了二阶段的验证实验,结果如下图。其中 pair 代表 aspect-opinion 的配对结果,triplet 代表 aspect-opinion-sentiment 的三元组结果。在 triplet 结果上,我们的模型一致性的优于其他现有方法。在 pair 的结果上,整体上对现有方法具有明显优势。


JET: End-to-End ASTE
本小节工作来自论文:
Position-Aware Tagging for Aspect Sentiment Triplet Extraction, in EMNLP 2020
论文链接:
https://aclanthology.org/2020.emnlp-main.183.pdf
模型代码:
https://github.com/xuuuluuu/Position-Aware-Tagging-for-ASTE
3.1 问题定义
上一节中我们首次提出了 ATSE 这个任务 [1],并且提出了一个两阶段模型来分别进行抽取和配对。此类分阶段模型的一个弊端是无法完全利用三元组合里面三元之间的关系,因为主体的情感方向主要由该主体词以及该主体的情感词以及语境来共同决定。主题词与情感词在语义层面有对应关系,分阶段的方式限制了模型提取此类特征。同时该两阶段是割裂开的,会有错误传递的问题。
一个句子中,Aspect 及其 sentiment 极性,与表明这个极性的 opinion term,这三者之间是紧密相关的,因此我们认为 End-to-End 的方案应该可以更好地解决 ASTE 这个任务。实现 End-to-End 方案的挑战在于,在抽取任务中,常用的序列标注的方法的标签设计(如 BIOES)只能标注本类实体,无法表达本实体和其他实体的关系。
例如,同时解决 Aspect 抽取和 Opinion 抽取的已有工作中(如上一节的现有方法 CMLA [2] 和 RINANTE [3]),使用两套 BIO 标签来在同一个序列里分别标注 Aspect 和 Opinion,但是无法在标注的同时,建立 Aspect 和 Opinion 的对应关系。
我们的模型是第一个采用端对端的方式直接避免了原有模型的采用分阶段导致提取出不完整特征的弊端,其次我们的模型主要根据三元之间的关系来计算每个词的标签,最后根据条件随机场的方式获得最佳的标签顺序。
3.2 我们的模型
标签形式:
为了克服上述问题,我们首先设计了一套新的、表达能力更强的标签。具体地,这套标签的标注对象是 Aspect,通过对 BIOES 标签中的‘B’和‘S’进行扩展,来表达其情感极性以及表达这个极性的 Opinion。
基于传统的 BIOES 标注方式,我们延展了 B 和 S 使他们带有更多的含义: ,,p 代表该主体情感方向,i 和 j 代表情感词和当前主体词的位置距离,其他 IOE 还是和传统的定义一样。如下图例子所示:
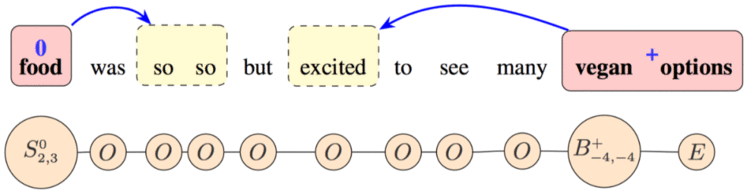
扩展标签的上标‘+’、‘-’、‘0’分别代表当前 Aspect 的正、负、中情感极性,下标则给出了表达该情感的 opinion phrase。如上图所示,句中有两个主体:“food” 和“vegan options”,除了主体词外,其余标识全是 O。
“food”的标识是 ,它说明了当前主体是词长为 1,主体情感是中性,情感词在主体词后面距离2位置起始,到 3 结束,即为“so so”。“vegan options”的标注分别是 和 E(代表主体词结束),它说明了当前主体词词长为2,主体情感是正向,情感词在主体词前距离4个词长,即为“excited”。
基于上述的标签形式,模型可以实现端对端的抽取并且可以抽取出一些多个 Aspect 对应同样 Opinion 这种情况稍微复杂的三元组。但是该形式也存在一定弊端。此标签形式不能很好地解决另外一种情况的三元组:一个 Aspect 对应多个 Opinion。我们发现,新的标签形式可以经过一个简单的变换可以弥补此类弊端。这个简单的变换是在延续之前标签形式的基础上,用其对 Opinion 打标,如下图所示:
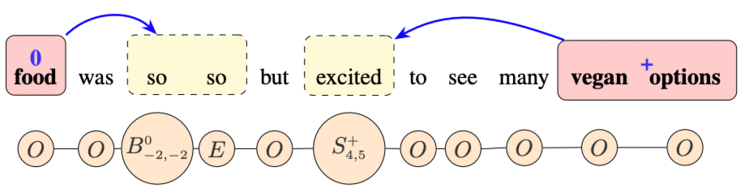
为了区分这两种标签形式,我们分别把他们定义为 以及 。
模型方法:
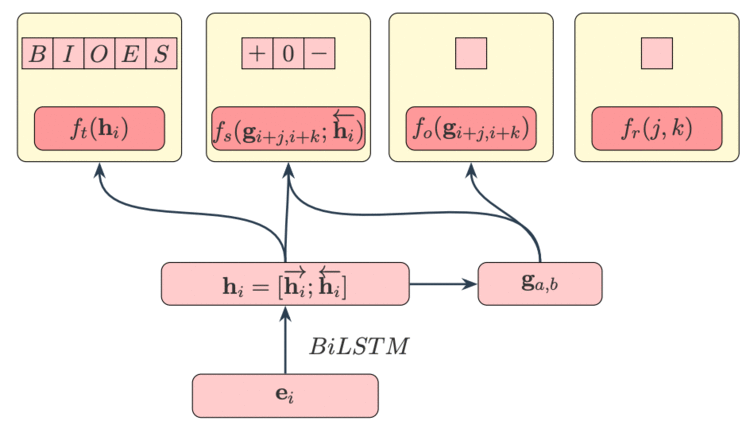
基于我们新提出的的标签形式,我们的模型主要启发于条件随机场模型 [4] 以及半马科夫条件随机场模型 [5],该模型可以同时抽取字与词的特征信息来帮助计算标识分数,具体特征分数计算方式如下图所示(详细可以参考原文 Section 2.2.2)。 输入层采用 300 维度的 Glove 词向量,然后输入双向的长短时记忆网络(Bi-LSTM)来获得基于给定语境的每个词的隐式表达。
每个标识的分数主要由四部分组成,1. 通过每个字的隐向量来计算每个字 BIOES 中标识分数,2. 通过情感词起始位置到句末的隐向量来计算情感方向的分数,3. 通过词组向量来计算该词组是情感词的分数, 4. 通过情感词与主体词的距离来计算该情感词是不是该主体词对应的情感词。最后基于前项后项算法来找出每句话最大可能性的标识。
3.3 主要结果
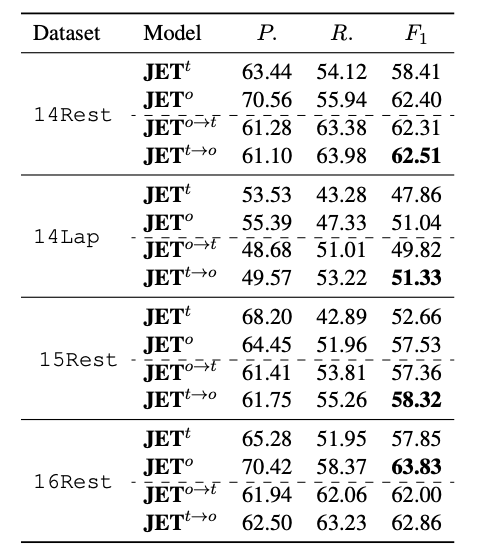
首先,我们在四个标准公开数据集上测试了模型在不同 encoder(Bi-LSTM 和 BERT without finetune)的表现,M 代表主体词与情感词之间的最大距离, 代表我们基于主体词的标签形式, 代表我们基于情感词的标签形式,这两种模型在所有的数据集上的表现均超过当前其他模型。如下表所示:
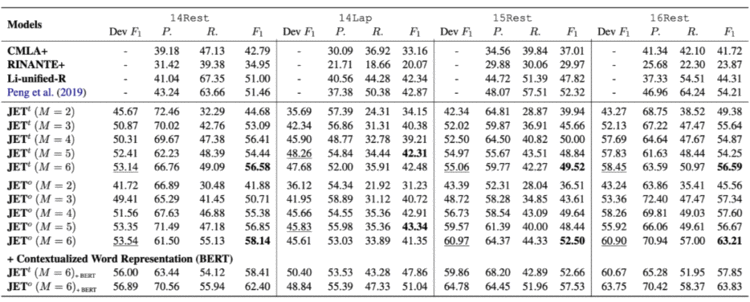
同时,我们测试了把基于主体的模型 和基于情感词的模型 的预测结果结合在一起,我们发现相结合的模型有更好的预测结果,实验结果证明这两种标签形式可以互相弥补,结果如下表所示:

Span-based ASTE
本小节工作来自论文:
Learning Span-Level Interactions for Aspect Sentiment Triplet Extraction, in ACL 2021
论文链接:
https://aclanthology.org/2021.acl-long.367.pdf
模型代码:
https://github.com/chiayewken/Span-ASTE
4.1 问题定义
除过我们上文提到的 JET [1],在 ASTE [2] 这个任务上,还有一些近期提出的端到端的方式进行三元组抽取。虽然这些端对端的模型可以提升抽取的效果,但是这些模型依赖于每个主体词和情感词单个词之间或者单个词与词组之间的互相作用来判断整体的情感极性。
在包含多个词(主体词或情感词)的三元组上,这些端对端的模型不能完整的识别词组之间的联系,因此降低了模型的有效性。我们在本文中提出了一种基于词组的模型,该模型在执行三元组抽取时明确考虑了主体词和情感词的整体词组之间的相互作用,从而确保了情感极性的一致性。同时,为了降低词组枚举导致的高计算成本,我们也提出了一种双通道词组剪枝策略,该策略结合了主体词抽取(ATE)和情感词抽取(OTE)两个任务的监督。
该策略不仅可以提高计算效率,而且可以更恰当地区分主体词和情感词。我们的模型在 ASTE、ATE 和 OTE 三个任务上均有明显的提升。实验分析表明,该模型尤其在包含多个单词(主体词或情感词)的三元组上有更大的优势。
4.2 我们的模型
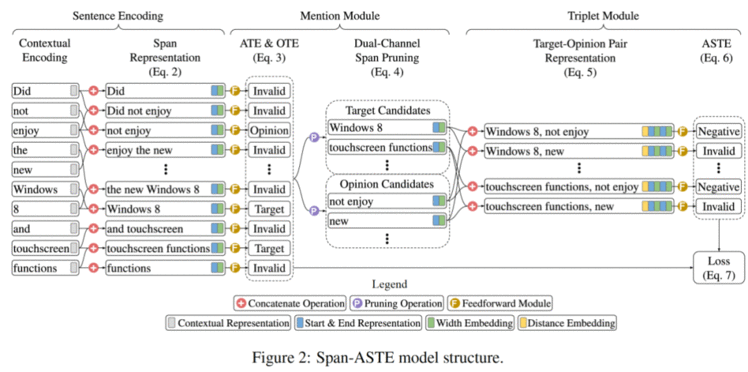
如上图例子:“Did not enjoy the new Windows 8 and touchscreen functions”。我们的模型首先通过 300 维度的 Glove [3] 向量和双向长短期记忆网络来得到句子中每一单词在当前句中的特征表达。或者,我们也使用预先训练的 BERT [4] 语言模型作为句子的编码器。然后,我们枚举句子内连续单词的所有可能词组,并拼接开始词、结束词和词组宽度的特征来形成相对应词组的特征表达。
我们的实体模块(mention module)主要由一个前馈神经网络组成,它以 ATE 和 OTE 任务的监督训练来判断主体词以及情感词各自的分数。为了降低大量枚举词组的计算成本,我们也提出了双通道词组剪枝策略,分别选择预测分数较高的主题词和情感词作为候选对象。
从上图中,预测分数最高的主体词候选对象是“Windows 8”和“touchscreen functions”,而情感词候选对象是“not enjoy”和“new”。这提高了将有效的主体词候选对象和情感抽选对象配对在一起的机率。对于主体词和情感词配对在一起的特征表示,我们把主体词组的表达,情感词组的表达以及主题词组和情感词组之间的距离表达来形成一个新的特征表示。
最后,我们使用前馈神经网络来预测两个词组之间的情感对关系。从上图中例子可以看出,该模型抽取了两个三元组:(“Windows 8”、“not enjoy”、Negative)和(“touchscreen functions”,“not enjoy”,Positive)。
4.3 主要结果
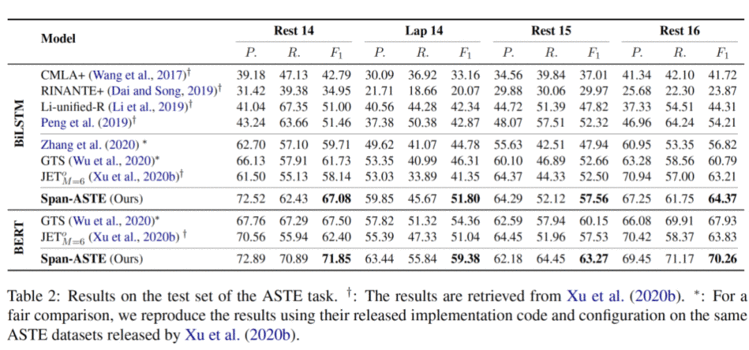
如上表所示,我们提出的 Span-ASTE 在四个 ASTE 数据上一贯地优于先前的方法。这表明我们的端到端模型能更有效地考虑多单词的主体词和情感词之间的相互作用,也减轻了以前分段方法所面临的错误传播问题。
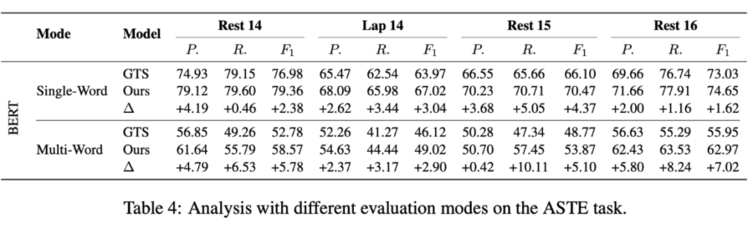
同时,我们对比了不同模型在单个词的三元组以及多个词的三元组上的表现。我们发现相比于之前的模型,我们模型在两种三元组上均有明显提升。在多词三元组上,我们的词组级别的模型表现的更好。综合来看,多词三元组的表现依然明显低于单词三元组,我们将来研究的重点可能在怎么提升模型在多词三元组上的表现。
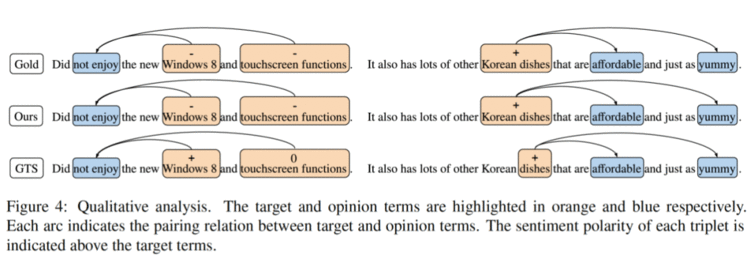
我们方法的优势可以根据上图例子进一步说明,该图显示了带有人工标注(Gold)的示例评论,以及来自 GTS [5] 模型和我们模型的预测。GTS 是最近在 ASTE 任务上提出的模型,它依赖单个词与单个词之间的相互作用。
对于第一个示例,GTS 正确地将“Windows 8”与“not enjoy”配对,但是情感极性预测不准确。这方法依赖于解码式方法来处理最终三元组的预测,在情感极性平局的情况下具有预设偏差的限制。在第二个例子中,GTS 只能不完整地抽取“dishes”当主体词,导致了错误的三元组预测。我们的模型可以成功的预测这两个三元组,并准确地抽取主体词和情感词配对的情感极性,即使主体词或情感词包含多个单词。

总结
ASTE 任务提出后在领域内引起了较大关注,也有一系列相关论文发表出来 [1,2,3,4, 5],由于篇幅所限不一一详述。ASTE 这个任务的重要性主要体现在该任务在抽取主体词以及预测其情感极性的同时,还能够附带抽取表明该情感极性的情感词。
该任务的输出结果一次性回答了三个问题:抽取主体是什么?针对该主体的情感极性是什么?以及为什么该主体词具有这样的情感极性?由此,ASTE 这个任务可以实现对于评论目标更全面的分析。
该任务提出的一年多以来,已经有多个方法被陆续尝试,我们也看到了实验效果的显著提升。但是从当前模型的综合表现看( 值刚刚超过 70),该任务的难度较高,依然有很大的研究和突破的空间。在最新的 Span-ASTE [6] 文章里,我们发现不同的三元组也有难易之分,模型在单个词三元组上的表现远高于多个词三元组。
所以我们下一个阶段的研究方向分为两类,第一类是从文本理解出发,在单个词和多个词的三元组上做到整体的提升;第二个类是理解为什么多词三元组抽取的难度,以及弥补单个词和多个词三元组之间的差异。




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有