XGBoost的全称是eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。XGBoost是大规模并行boosting tree的工具,它是目前最快最好的开源 boosting tree工具包,比常见的工具包快10倍以上。在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、 Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。
XGBoost的基本思想差不多可以理解成以损失函数的二阶泰勒展开式作为其替代函数,求解其最小化(导数为0)来确定回归树的最佳切分点和叶节点输出数值(这一点和cart回归树不同)。此外,XGBoost通过在损失函数中引入子树数量和子树叶节点数值等,充分考虑到了正则化问题,能够有效避免过拟合。在效率上,XGBoost通过利用独特的近似回归树分叉点估计和子节点并行化等方式,加上二阶收敛的特性,建模效率较一般的GBDT有了大幅的提升。
#XGBoost
import xgboost as xgb
xgb_model = xgb.XGBClassifier(max_depth=2,n_estimators=100)
xgb_model.fit(horse_train_x,horse_train_y)
y_pre_xgb = xgb_model.predict(horse_test_x)
sum(y_pre_xgb==horse_test_y)/float(horse_test_y.shape[0])
XGBoost和GBDT两者都是boosting方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。因此,本文我们从目标函数开始探究XGBoost的基本原理。
XGBoost是由个基模型组成的一个加法模型,假设我们第次迭代要训练的树模型是 ,则有:

损失函数可由预测值与真实值进行表示:

其中,表示样本量。
模型的预测精度由模型的偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要在目标函数中添加正则项,用于防止过拟合。所以目标函数由模型的损失函数与抑制模型复杂度的正则项组成,目标函数的定义如下:
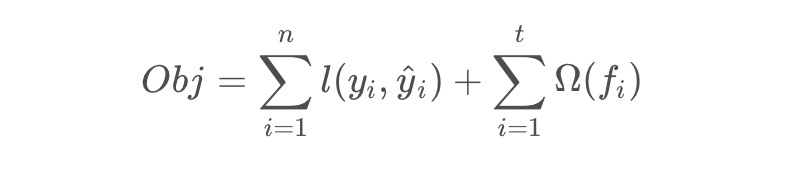
其中,上式的第二部分求和内容是将棵树的复杂度进行求和,添加到目标函数中作为正则化项,用于防止模型过度拟合。
根据boosting族中的算法是遵从前向分步加法,所以以第步的模型为例,模型对第个样本的预测值为:

其中,上式的第一部分是第步给出的预测值,第二部分是第步需要加上的新模型的预测值,此时目标函数就可以等价写成:
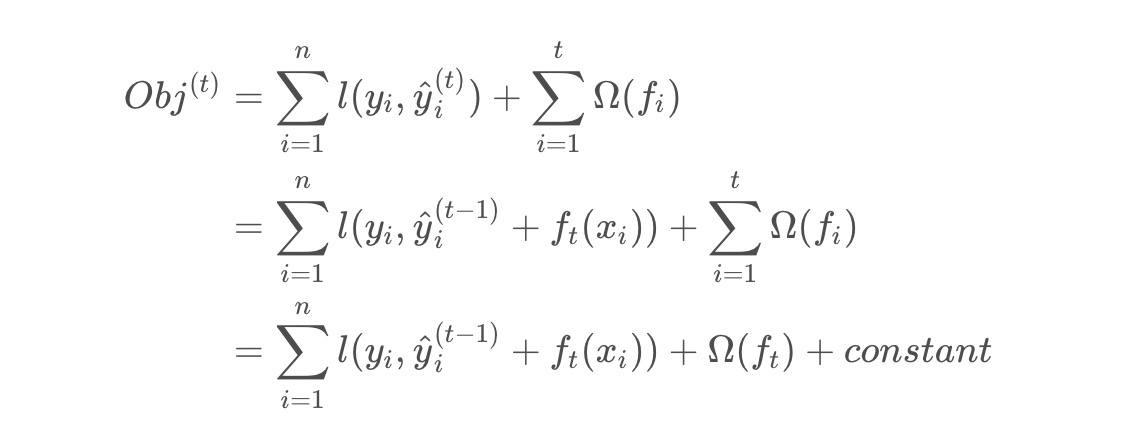
根据公示转换,最终的目标函数就可以转换成一个变量和常量的关系。
第二个等号到第三个等号之间的关系:
将正则化项进行拆分,由于前棵树的结构已经确定,因此前棵树的复杂度之和可以用一个常量表示,如下所示:

泰勒公式定义:

回到XGBoost上,,,,因此目标函数可以写成:

其中,为损失函数的一阶导,为损失函数的二阶导,注意这里的求导是对求导。
以平方损失函数为例,有:

则:
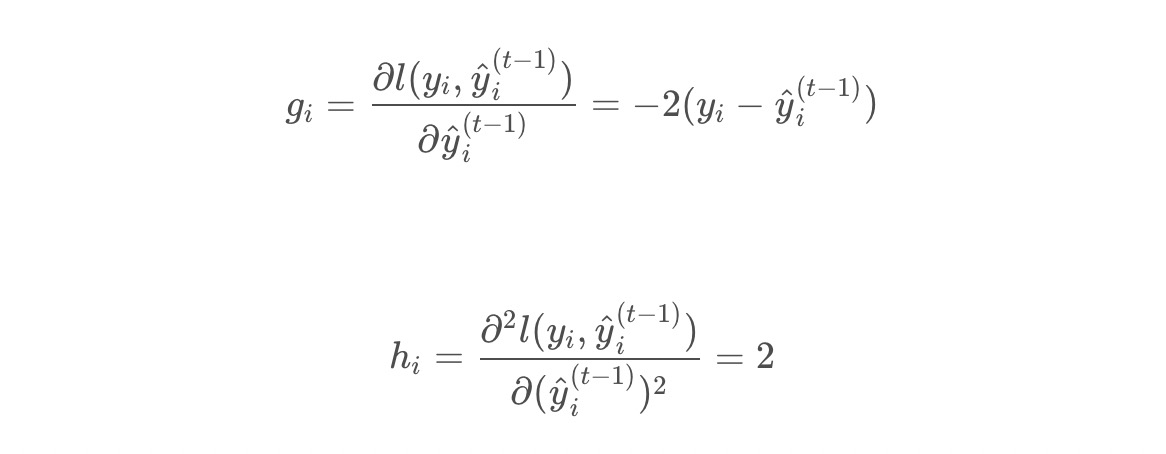
将上述的二阶展开式,带入到XGBoost的目标函数中,可以得到目标函数的近似值为:

由于在第步时,其实是一个已知的值,所以 是一个常数,其对函数的优化不会产生影响。因此,去掉全部的常数项,得到目标函数为:

所以我们只需要求出每一步损失函数的一阶导和二阶导的值(由于前一步的 是已知的,所以这两个值就是常数),然后最优化目标函数,就可以得到每一步的,最后根据加法模型得到一个整体模型。
XGBoost的基模型不仅支持决策树,还支持线性模型,主要介绍基于决策树的目标函数,可以重新定义一棵决策树,其包括两个部分:

决策树的复杂度可由叶子数组成,叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重(类比 LR 的每个变量的权重),所以目标函数的正则项由生成的所有决策树的叶子节点数量,和所有节点权重所组成的向量的范式共同决定。
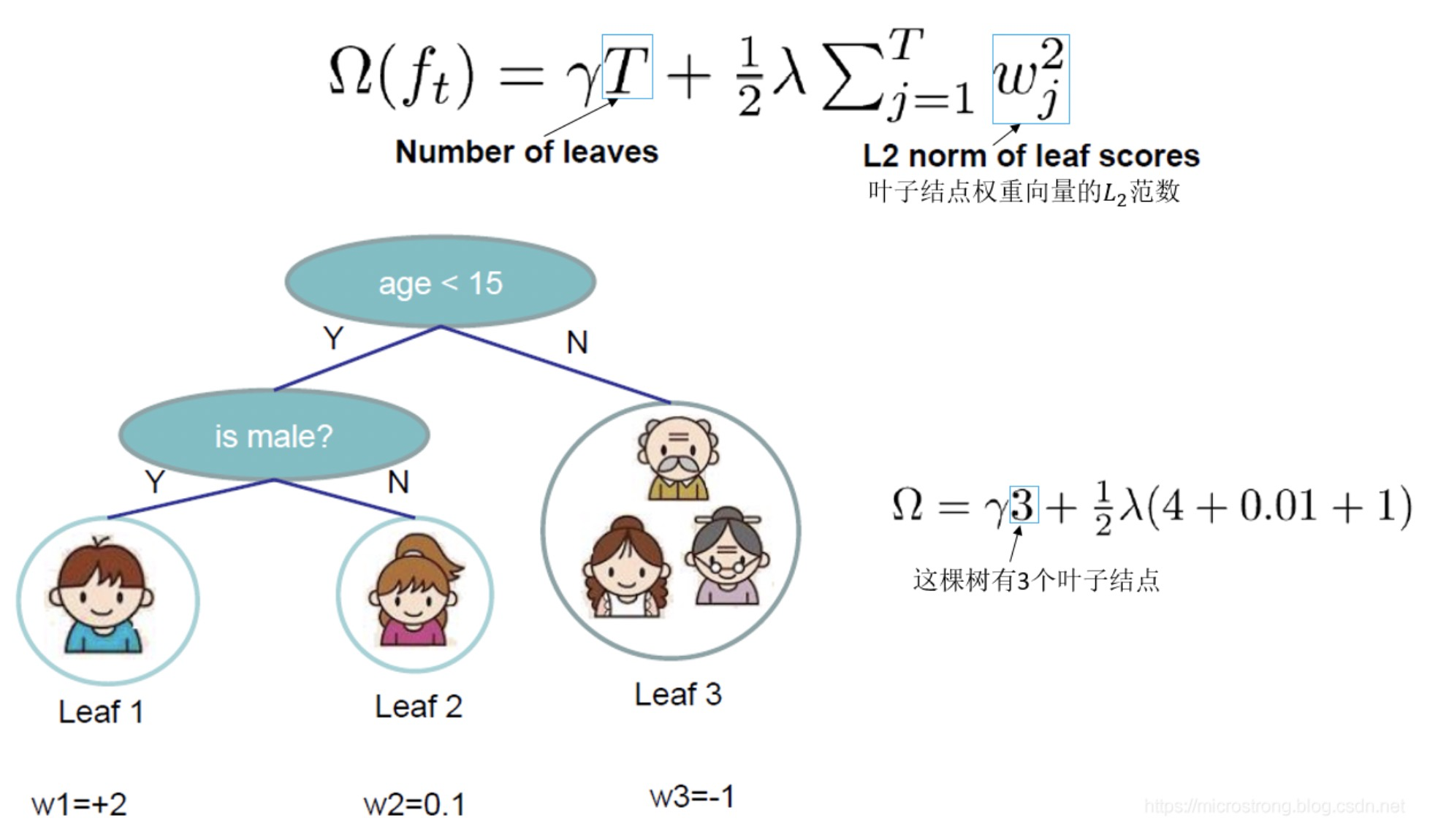
我们将属于第个叶子结点的所有样本划入到一个叶子结点的样本集合中,数学表示为:,那么XGBoost的目标函数可以写成:
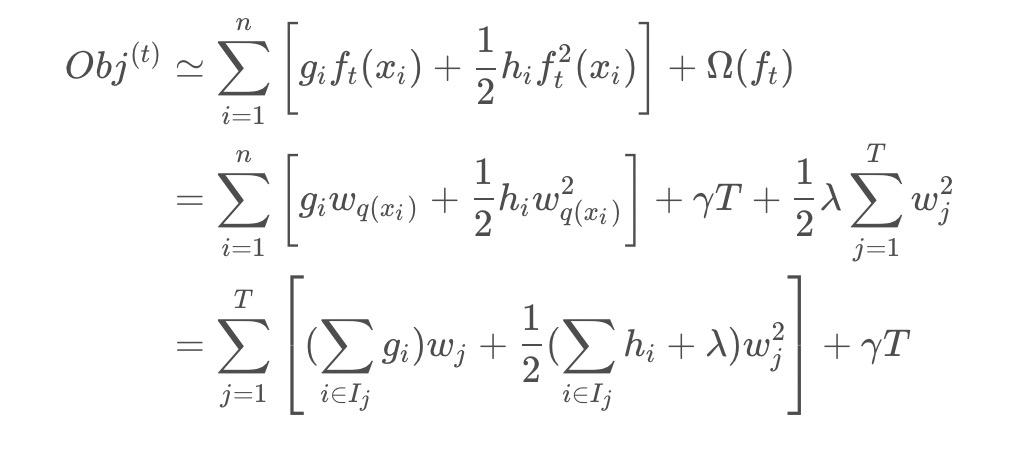
第二行是遍历所有的样本后求每个样本的损失函数,但样本最终会落在叶子节点上,所以我们也可以遍历叶子节点,然后获取叶子节点上的样本集合,最后再求损失函数。即我们之前是单个样本,现在都改写成叶子结点的集合,由于一个叶子结点有多个样本存在,因此才有了 和 这两项,为第个叶子节点取值。
为简化表达式,定义, ,含义如下:- :叶子结点所包含样本的一阶偏导数累加之和,是一个常量;- :叶子结点 j jj 所包含样本的二阶偏导数累加之和,是一个常量;
将和带入XGBoost的目标函数,则最终的目标函数为:

其中,和是前步得到的结果,其值已知可视为常数,只有最后一棵树的叶子节点不确定;


那么,假设目前树的结构已经固定,套用一元二次函数的最值公式,将目标函数对求一阶导,并令其等于,则可以求得叶子结点对应的权值:

所以目标函数可以化简为:
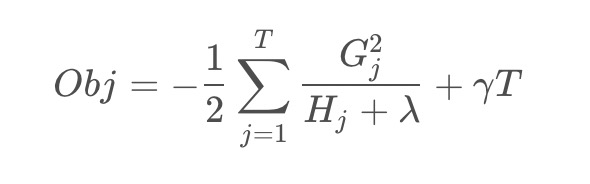

上图给出目标函数计算的例子,求每个节点每个样本的一阶导数和二阶导数,然后针对每个节点对所含样本求和得到和,最后遍历决策树的节点即可得到目标函数。
在实际训练过程中,当建立第棵树时,一个非常关键的问题是如何找到叶子节点的最优切分点,XGBoost支持两种分裂节点的方法——贪心算法和近似算法。
(1)贪心算法
从树的深度为0开始:
那么如何计算每个特征的分裂收益呢?
假设在某一节点完成特征分裂,则分裂前的目标函数可以写为:
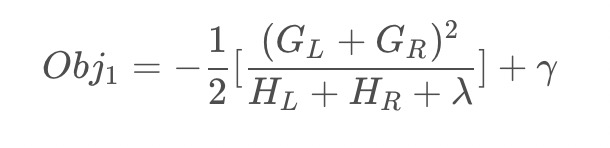
分裂后的目标函数为:

则对于目标函数来说,分裂后的收益为:

注意: 该特征收益也可作为特征重要性输出的重要依据。
对于每次分裂,都需要枚举所有特征可能的分割方案,如何高效地枚举所有的分割呢?
假设要枚举某个特征所有这样条件的样本,对于某个特定的分割点,要计算左边和右边的导数和。
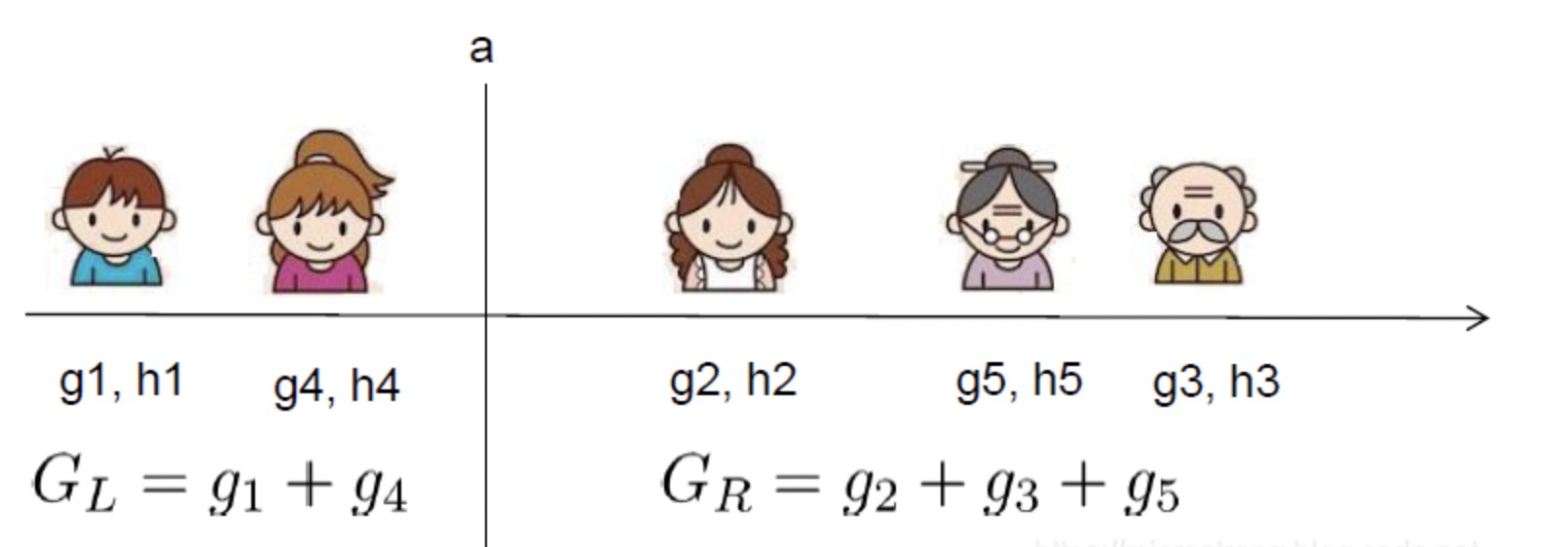
可以发现对于所有的分裂点,只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和、,然后用上面的公式计算每个分割方案的收益就可以了。
观察分裂后的收益,会发现节点划分不一定会使得结果变好,因为有一个引入新叶子的惩罚项,也就是说引入的分割带来的增益如果小于一个阀值的时候,就可以剪掉这个分割。
(2)近似算法
贪心算法可以得到最优解,但当数据量太大时则无法读入内存进行计算,近似算法主要针对贪心算法这一缺点给出了近似最优解。对于每个特征,只考察分位点可以减少计算复杂度。该算法首先根据特征分布的分位数提出候选划分点,然后将连续型特征映射到由这些候选点划分的桶中,然后聚合统计信息找到所有区间的最佳分裂点。
在提出候选切分点时有两种策略:
直观上来看,Local策略需要更多的计算步骤,而Global策略因为节点已有划分所以需要更多的候选点。
下图给出不同种分裂策略的AUC变化曲线,横坐标为迭代次数,纵坐标为测试集AUC,eps为近似算法的精度,其倒数为桶的数量。

从上图可以看到, Global策略在候选点数多时(eps 小)可以和 Local 策略在候选点少时(eps 大)具有相似的精度。还可以发现,在eps取值合理的情况下,分位数策略可以获得与贪心算法相同的精度。
近似算法简单来说,就是根据特征的分布来确定个候选切分点,然后根据这些候选切分点把相应的样本放入对应的桶中,对每个桶的进行累加。最后在候选切分点集合上贪心查找。该算法描述如下:

算法讲解:
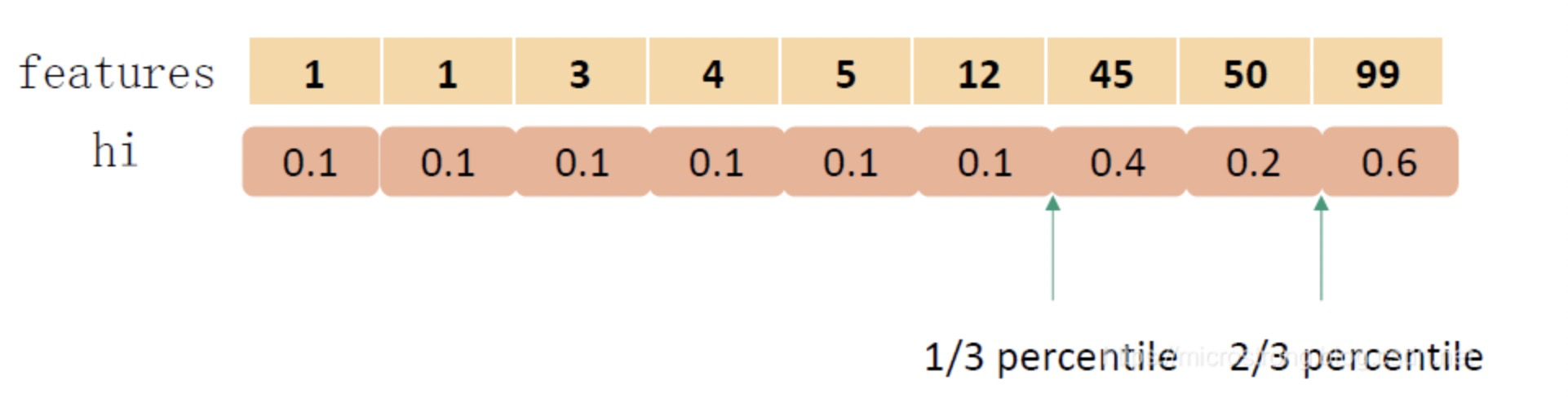
下图给出近似算法的具体例子,以三分位为例:
根据样本特征进行排序,然后基于分位数进行划分,并统计三个桶内的值,最终求解节点划分的增益。
实际上,XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值作为样本的权重进行划分。为了处理带权重的候选切分点的选取,作者提出了Weighted Quantile Sketch算法。加权分位数略图算法提出了一种数据结构,这种数据结构支持merge和prune操作。
现在我们简单介绍加权分位数略图侯选点的选取方式,如下:
模型的目标函数为:
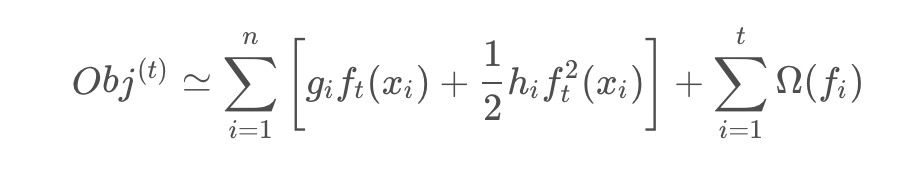
整理可得:

其中,加入是因为和是上一轮的损失函数求导与 constant 皆为常数,可以看到就是平方损失函数中样本的权重。
实际工程中一般会出现输入值稀疏的情况。比如数据的缺失、one-hot编码都会造成输入数据稀疏。XGBoost在构建树的节点过程中只考虑非缺失值的数据遍历,而为每个节点增加了一个缺省方向,当样本相应的特征值缺失时,可以被归类到缺省方向上,最优的缺省方向可以从数据中学到。至于如何学到缺省值的分支,其实很简单,分别枚举特征缺省的样本归为左右分支后的增益,选择增益最大的枚举项即为最优缺省方向。
在构建树的过程中需要枚举特征缺失的样本,乍一看这个算法会多出相当于一倍的计算量,但其实不是的。因为在算法的迭代中只考虑了非缺失值数据的遍历,缺失值数据直接被分配到左右节点,所需要遍历的样本量大大减小。作者通过在Allstate-10K数据集上进行了实验,从结果可以看到稀疏算法比普通算法在处理数据上快了超过50倍。
在树生成过程中,最耗时的一个步骤就是在每次寻找最佳分裂点时都需要对特征的值进行排序。而 XGBoost 在训练之前会根据特征对数据进行排序,然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(Compressed Sparse Columns Format,CSC)进行存储,后面的训练过程中会重复地使用块结构,可以大大减小计算量。
作者提出通过按特征进行分块并排序,在块里面保存排序后的特征值及对应样本的引用,以便于获取样本的一阶、二阶导数值。具体方式如图:
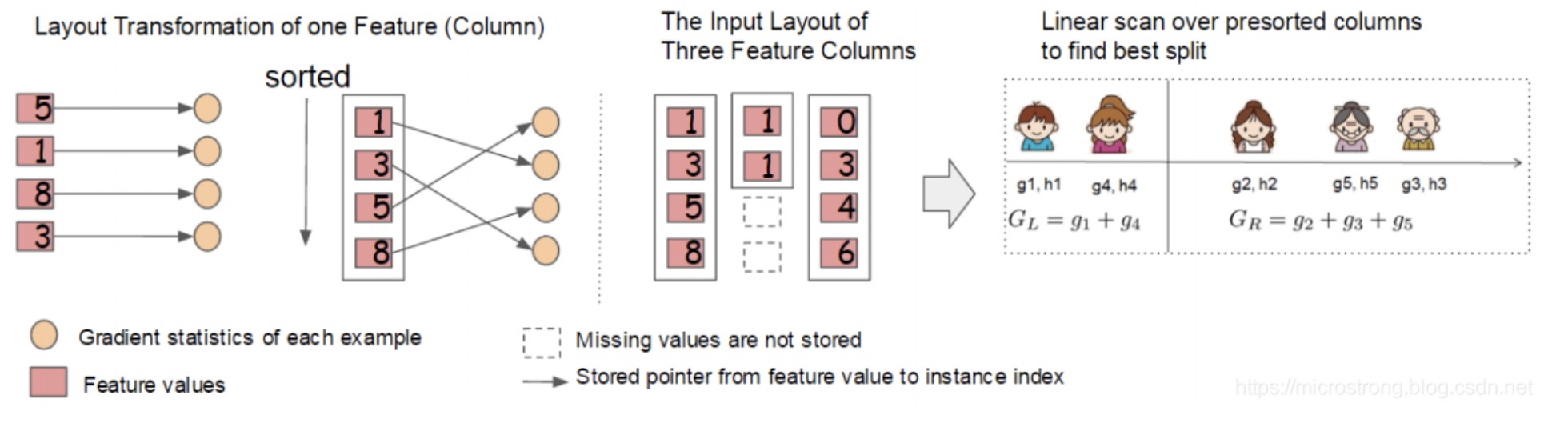
通过顺序访问排序后的块遍历样本特征的特征值,方便进行切分点的查找。此外分块存储后多个特征之间互不干涉,可以使用多线程同时对不同的特征进行切分点查找,即特征的并行化处理。在对节点进行分裂时需要选择增益最大的特征作为分裂,这时各个特征的增益计算可以同时进行,这也是 XGBoost 能够实现分布式或者多线程计算的原因。
列块并行学习的设计可以减少节点分裂时的计算量,在顺序访问特征值时,访问的是一块连续的内存空间,但通过特征值持有的索引(样本索引)访问样本获取一阶、二阶导数时,这个访问操作访问的内存空间并不连续,这样可能造成cpu缓存命中率低,影响算法效率。
为了解决缓存命中率低的问题,XGBoost 提出了缓存访问算法:为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中,这样就实现了非连续空间到连续空间的转换,提高了算法效率。此外适当调整块大小,也可以有助于缓存优化。
当数据量非常大时,我们不能把所有的数据都加载到内存中。那么就必须将一部分需要加载进内存的数据先存放在硬盘中,当需要时再加载进内存。这样操作具有很明显的瓶颈,即硬盘的IO操作速度远远低于内存的处理速度,肯定会存在大量等待硬盘IO操作的情况。针对这个问题作者提出了“核外”计算的优化方法。具体操作为,将数据集分成多个块存放在硬盘中,使用一个独立的线程专门从硬盘读取数据,加载到内存中,这样算法在内存中处理数据就可以和从硬盘读取数据同时进行。此外,XGBoost 还用了两种方法来降低硬盘读写的开销:
本篇文章所有数据集和代码均在地址中。
pip install xgboost
XGBoost有两大类接口:XGBoost原生接口 和 scikit-learn接口 ,并且XGBoost能够实现分类和回归两种任务。
(1)基于XGBoost原生接口的分类
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split# read in the iris data
iris = load_iris()X = iris.data
y = iris.target# split train data and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565)# set XGBoost's parameters
params = {'booster': 'gbtree','objective': 'multi:softmax', # 回归任务设置为:'objective': 'reg:gamma','num_class': 3, # 回归任务没有这个参数'gamma': 0.1,'max_depth': 6,'lambda': 2,'subsample': 0.7,'colsample_bytree': 0.7,'min_child_weight': 3,'silent': 1,'eta': 0.1,'seed': 1000,'nthread': 4,
}plst = params.items()dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds)# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)# 计算准确率
cnt1 = 0
cnt2 = 0
for i in range(len(y_test)):if ans[i] == y_test[i]:cnt1 += 1else:cnt2 += 1print("Accuracy: %.2f %% " % (100 * cnt1 / (cnt1 + cnt2)))# 显示重要特征
plot_importance(model)
plt.show()
(2)基于Scikit-learn接口的回归
这里用Kaggle比赛中回归问题:House Prices: Advanced Regression Techniques,地址来进行实例讲解。
该房价预测的训练数据集中一共有81列,第一列是Id,最后一列是label,中间79列是特征。这79列特征中,有43列是分类型变量,33列是整数变量,3列是浮点型变量。训练数据集中存在缺失值。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
import xgboost as xgb
from sklearn.metrics import mean_absolute_error# 1.读文件
data = pd.read_csv('./dataset/train.csv')
data.dropna(axis=0, subset=['SalePrice'], inplace=True)# 2.切分数据输入:特征 输出:预测目标变量
y = data.SalePrice
X = data.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object'])# 3.切分训练集、测试集,切分比例7.5 : 2.5
train_X, test_X, train_y, test_y = train_test_split(X.values, y.values, test_size=0.25)# 4.空值处理,默认方法:使用特征列的平均值进行填充
my_imputer = SimpleImputer()
train_X = my_imputer.fit_transform(train_X)
test_X = my_imputer.transform(test_X)# 5.调用XGBoost模型,使用训练集数据进行训练(拟合)
# Add verbosity=2 to print messages while running boosting
my_model = xgb.XGBRegressor(objective='reg:squarederror', verbosity=2) # xgb.XGBClassifier() XGBoost分类模型
my_model.fit(train_X, train_y, verbose=False)# 6.使用模型对测试集数据进行预测
predictiOns= my_model.predict(test_X)# 7.对模型的预测结果进行评判(平均绝对误差)
print("Mean Absolute Error : " + str(mean_absolute_error(predictions, test_y)))
在上一部分中,XGBoot模型的参数都使用了模型的默认参数,但默认参数并不是最好的。要想让XGBoost表现的更好,需要对XGBoost模型进行参数微调。下图展示的是分类模型需要调节的参数,回归模型需要调节的参数与此类似。
在普通的GBDT策略中,对于缺失值的方法是先手动对缺失值进行填充,然后当做有值的特征进行处理,但是这样人工填充不一定准确,而且没有什么理论依据。而XGBoost采取的策略是先不处理那些值缺失的样本,采用那些有值的样本搞出分裂点,在遍历每个有值特征的时候,尝试将缺失样本划入左子树和右子树,选择使损失最优的值作为分裂点。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有