目录1.IA-32架构的基本执行环境1.1寄存器的扩展1.1.1通用寄存器的扩展1.1.2IP寄存器的扩展1.1.3FLAGS寄存器的扩展1.1.4段寄存器的扩展1.
目录
1. IA-32架构的基本执行环境
1.1 寄存器的扩展
1.1.1 通用寄存器的扩展
1.1.2 IP寄存器的扩展
1.1.3 FLAGS寄存器的扩展
1.1.4 段寄存器的扩展
1.2 32位处理器内存访问概况
1.2.1 逻辑地址、有效地址、线性地址与物理地址
1.2.2 平坦模式(Flat Mode)
1.3 32位处理器寻址方式概况
2. 现代处理器的结构和特点
2.1 流水线(Pipe-Line)
2.1.1 指令预取队列
2.1.2 流水线基本原理
2.2 高速缓存(Cache)
2.2.1 局部性原理
2.2.2 高速缓存基本原理
2.3 乱序执行(Out-Of-Order Execution)
2.3.1 微操作(micro operations,μops)
2.3.2 乱序执行基本原理
2.4 寄存器重命名
2.5 分支目标预测(Branch Prediction)
1. IA-32架构的基本执行环境
1.1 寄存器的扩展
1.1.1 通用寄存器的扩展

① 32位处理器在16位处理器的基础上,扩展了8个通用寄存器,使之达到32位
② 为了在汇编语言中使用经过扩展(Extend)的寄存器,需要给扩展后的寄存器命名,分别为EAX / EBX / ECX / EDX / ESI / EDI / ESP / EBP
③ 32位通用寄存器的高16位不可独立使用,但是低16位保持和16位处理器的兼容
说明:即使在实模式下,也可以使用扩展后的寄存器
1.1.2 IP寄存器的扩展
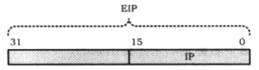
在32位模式下,为了生成32位物理地址,处理器需要使用32位的指令指针寄存器。为此,32位处理器将IP寄存器扩展为EIP寄存器
说明1:在16位实模式下,依然使用16位的IP寄存器
说明2:和在16位实模式下一样,在32位保护模式下,EIP寄存器也只能处理器内部使用(e.g. 被jmp、call、ret和iret等指令隐式修改),程序无法直接访问
1.1.3 FLAGS寄存器的扩展
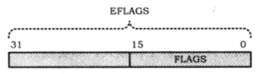
FLAGS寄存器被扩展为32位的EFLAGS寄存器,其中低16位与原先保持一致
1.1.4 段寄存器的扩展
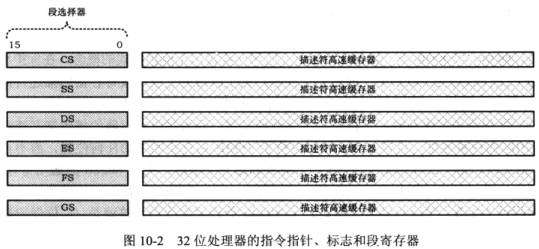
① 新增了FS、GS段寄存器
② 段寄存器仍然为16位,在实模式下,用法与8086一致,存储段基址;在保护模式下,存储段选择符
③ 每个段寄存器还包含一个不可见部分,称为描述符高速缓存器,用于缓存段选择符选择的段描述符。其中包含段的基地址和各种访问属性
这部分内容程序不可访问,由处理器自动使用
说明:32位处理器对寄存器的扩展,主要目的是支持32位保护模式的运行
1.2 32位处理器内存访问概况
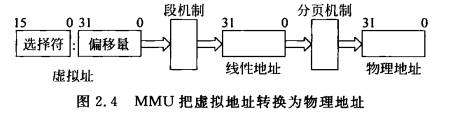
1.2.1 逻辑地址、有效地址、线性地址与物理地址
在讨论上述4个地址的关系之前,先说明如下2点前提,
① 在32位保护模式下,MMU引入了段机制和分页机制,其中段机制是必选的,分页机制是可选的
② 在32位保护模式下,依然使用分段模式,只不过引入了段描述符的概念,并在其上构建了保护模式
1.2.1.1 逻辑地址
① 段地址 + 偏移地址的地址描述形式称为逻辑地址
② 这里的段地址由段选择符指向的段描述符提供
1.2.1.2 有效地址
① 偏移地址称为有效地址(Effective Address,EA)
② 在指令中给出有效地址的方式叫做寻址方式(Addressing Mode)
1.2.1.3 线性地址
① 段机制将段地址和偏移地址相加,得到线性地址(Linear Address)
② 线性地址的概念用来描述任务的地址空间,IA-32处理器上的每个任务都可以拥有4GB的虚拟地址空间
1.2.1.4 物理地址
① 如果不使能分页机制,段机制产生的线性地址就是物理地址
② 如果使能分页机制,段机制产生的线性地址还需要经过转换,才能得到物理地址
1.2.2 平坦模式(Flat Mode)
① 将整个4GB内存定义为一个段,即段的基地址为0x00000000,段的长度为4GB,就是所谓的平坦模式。在这种情况下,可以视为不分段
② 在平坦模式下,可以执行4GB范围内的控制转移,也可以使用32位的偏移量访问任何4GB范围内的任何位置
③ 在平坦模式下,在地址数值上有如下关系,
偏移量 = 有效地址 = 线性地址
说明1:Linux操作系统在IA-32体系结构中就使用了平坦模式
说明2:在32位保护模式下,处理器要求在加载程序时先定义该程序所拥有的段,然后允许使用这些段。定义段时,除了基地址(起始地址)外,还附加了段界限、特权级别、类型等属性。当程序访问一个段时,处理器将用固件实施各种检查,防止对内存的违规访问
1.3 32位处理器寻址方式概况
首先来回顾一下16位处理器的内存寻址方式,
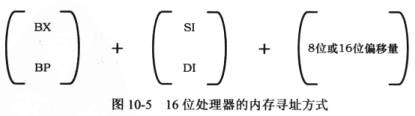
上述3个部分保留1 ~ 3个即构成了各种寻址方式,包括直接寻址、基址寻址、变址寻址和基址变址寻址
32位处理器将内存寻址方式扩展为如下形式,
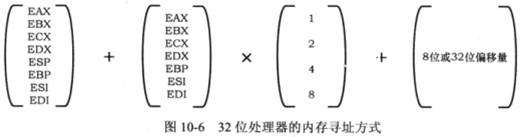
mov ecx, [eax + ebx * 8 + 0x02]
说明1:立即寻址和寄存器寻址在16位和32位处理器中没有区别
说明2:32位寻址方式目的是给保护模式使用的。在实模式下,虽然可以使用32位寄存器提供偏移地址,但是仍然不能超过64KB的段长度界限
2. 现代处理器的结构和特点
2.1 流水线(Pipe-Line)
2.1.1 指令预取队列
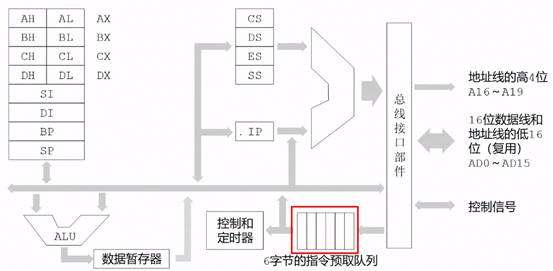
在8086处理器中就引入了指令预取队列,当指令执行时,如果总线是空闲的(没有访问内存的操作),就可以在指令执行的同时预取指令并提前译码
2.1.2 流水线基本原理
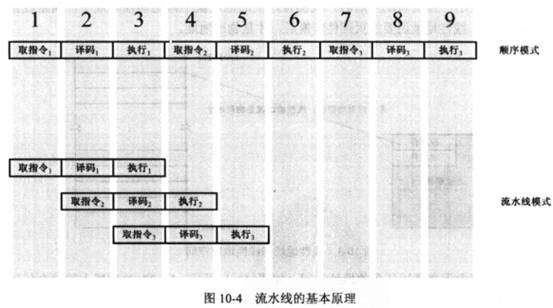
将指令的执行拆分成若干个步骤,并分配给相应的单元来完成。各个单元的执行是独立的、并行的,这样各个步骤的执行在时间上就会重叠起来,这就是流水线技术
2.2 高速缓存(Cache)
2.2.1 局部性原理
时间局部性:如果一个数据正在被访问,那么在近期他可能还会被再次访问(e.g. 循环操作)
空间局部性:如果一个数据正在被访问,那么与他在空间上临近的数据在近期可能会被访问(e.g. 指令顺序执行,数组连续存放数据)
2.2.2 高速缓存基本原理
① 在处理器与内存(DRAM)之间使用一个静态存储器(SRAM)作为缓存,用于缓解CPU与内存的速度差
② 将处理器正在访问和即将访问的指令和数据块从内存调入高速缓存中,于是每当处理器要访问内存时,首先检索高速缓存,如果命中(hit),则从高速缓存取数据;如果不中(miss),处理器会先将内存中的数据加载到高速缓存,然后再从高速缓存获取数据
③ 高速缓存的装载以块为单位
说明:当高速缓存不中时,需要额外的时间等待块从内存载入高速缓存,在该过程中损失的时间称为miss penalty
2.3 乱序执行(Out-Of-Order Execution)
2.3.1 微操作(micro operations,μops)
为了实现流水线技术,需要将指令拆分成更小的可独立执行部分,即微操作
下面给出3个微操作拆分示例,
add eax, ebx
; 只有寄存器加法一个微操作
add eax, [mem]
; 拆分为2个微操作
; 1. 将内存地址mem处的内容读取到临时寄存器
; 2. 将临时寄存器与EAX寄存器相加
add [mem], eax
; 拆分为3个微操作
; 1. 将内存地址mem处的内容读取到临时寄存器
; 2. 将EAX寄存器与临时寄存器相加
; 3. 将相加结果写回内存地址mem处
2.3.2 乱序执行基本原理
一旦将指令拆分成微操作,处理器就可以在必要时乱序执行,参考如下示例,
mov eax, [mem1] ; 1.读mem1内存EAX
shl eax, 5 ; 1.EAX左移
add eax, [mem2] ; 1.读mem2内存到临时寄存器 2. 临时寄存器加EAX
mov [mem3], eax ; 1.读mem3内存到临时寄存器 2. 临时寄存器加EAX; 3.将相加结果写回mem3地址处
在上例中,在指令EAX左移的同时,可以从mem2中取数据
2.4 寄存器重命名
考虑如下代码段,
mov eax, [mem1]
shl eax, 3
mov [mem2], eaxmov eax, [mem3]
add eax, 2
mov [mem4], eax
假设后3条指令不使用EAX寄存器,可以很明显看出后3条指令与前3条指令不相干。如果处理器为后3条指令使用内部的临时寄存器,后3条指令就可以和前3条指令并行执行
说明1:寄存器重命名以硬件完全自动的形式工作
说明2:所有通用寄存器、栈指针、标志寄存器、浮点寄存器,甚至段寄存器都可能被重命名
2.5 分支目标预测(Branch Prediction)
① 当处理器遇到转移指令时,需要清空(flush)流水线,并从转移的目标位置处重新取指令放入流水线
流水线越长,处理器在用错误的分支填充流水线时浪费的时间越多
② 在处理器内部,有一个小容量的高速缓存器,叫分支目标缓存器(Branch Target Buffer, BTB)。当处理器执行了一条分支语句后,会在BTB中记录当前指令的地址、分支目标的地址,以及本次分支预测的结果
下一次,在那条转移指令实际执行之前,处理器会查询BTB是否有最近的转移记录。如果能找到对应的条目,则推测执行和上一次相同的分支,把该分支的指令送入流水线
③ 如果预测失败,将清空流水线,同时刷新TBT中的记录,这个代价较大









 京公网安备 11010802041100号
京公网安备 11010802041100号