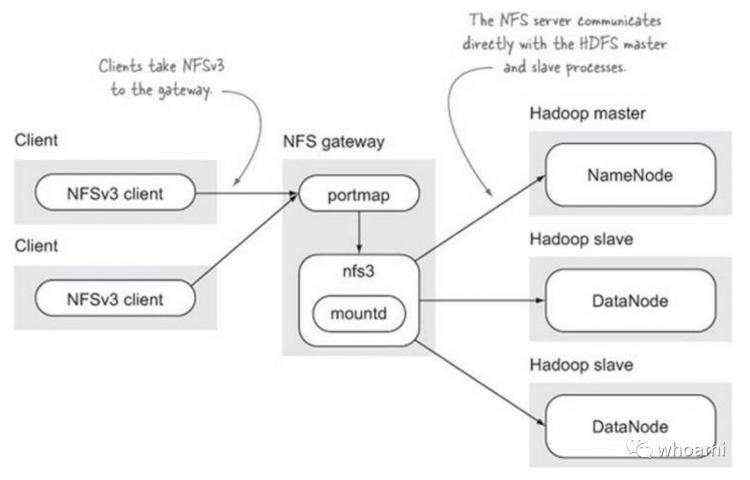
今天我们聊NFSGateway,近期真的是忙得不可开交,在构建100个节点集群的时,由于一些特殊的业务需求需要使用NFS-Gateway或者HDFS-fuse功能,把HDFS分布式文件系统挂在到某些机器上,可以通过访问Linux本地文件系统操纵HDFS中的数据,这就是类似传统的NFS
文件系统的功能。通过把HDFS整个分布式文件系统,挂载到某些Linux机器,通过往挂载的目录中传递数据,即可直接上传到HDFS,让HDFS的使用方式非常的方便。
目前开源世界有很多分布式文件系统的优秀软件,比如:Ceph,Glusterfs,Alluxio等都提供了类似nfs,fuse挂载分布式文件系统到Linux主机的能力,也都大量复用了Linux本身已经有的软件,所以都是兼容NFS,FUSE的接口的。HDFS也不例外,也都通过类似的技术来支持这样的功能。
在HDFS中目前提供了两种方式:
HDFS-NFSGateway 在HDP版本中原生支持此方式
HDFS-Fuse
HDP 2.6.1.0-129
$ hdp-select versions
2.6.1.0-129
Linux
$ cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
通过ambari
界面自动化去安装NFSGateway
的方法,在Ambari管理的最新的Hadoop2.x以上的版本都是支持这种方式的,并且在界面上可以自动化安装NFSGateway
。
首先,登录ambari-server的可视化界面,点击“Hosts”,任意选择一个主机单机。
其次,点击+Add
按钮,选择NFSGateway
,点击Confirm Add
进行安装NFSGateway。
最后,点击Start
按钮,启动NFSGateway。
手动教程参考:http://itweet.cn/blog/2014/02/04/HDFS_NFS_Gateway
首次挂载遇到如下问题,环境是Centos 7.2
我亲自安装的,采用的是最小化的安装Linux系统模式,而集群的版本HDP 2.6.1.0-129
。
# mount -t nfs -o vers=3,proto=tcp,nolock localhost:/ /hdfs
mount: wrong fs type, bad option, bad superblock on localhost:/,
missing codepage or helper program, or other error
(for several filesystems (e.g. nfs, cifs) you might
need a /sbin/mount.
In some cases useful info is found in syslog - try
dmesg | tail or so.
根据提示,并且进一步排除/sbin/mount.
目录发现,根本没有mount.
的文件,进而断定为缺少nfs-utils
软件包,安装即解决问题。
# yum install nfs-utils
NFSGateway挂载,HDFS分布式文件系统挂载到本地系统挂载点为/hdfs
,如下:
# mkdir /hdfs
# mount -t nfs -o vers=3,proto=tcp,nolock localhost:/ /hdfs
# df -h|grep hdfs
localhost:/ 4.8T 3.2G 4.8T 1% /hdfs
NFSGateway挂载成功之后,我们对他进行一些基本的读写测试,看是否满足我们的要求,让HDFS分布式文件系统的访问,就像访问Linux本地目录一样简单。
例如:
测试cp数据到目录
[root@bigdata-server-1 ~]# su - hdfs
[hdfs@bigdata-server-1 ~]$ echo aaa > test.txt
测试cp文件到挂载点(/hdfs
)的属于分布式文件系统的/hdfs/tmp
,出现错误,表现的现象为无法正常cp数据到此目录,并且在hdfs
看到生成此相关文件大小为0
$ cp test.txt /hdfs/tmp/
cp: cannot create regular file ‘/hdfs/tmp/test.txt’: Input/output error
既然是NFS的问题,首先排查NFS
服务相关日志,定位问题,发现如下警告信息。
# tail -300 /var/log/hadoop/root/hadoop-hdfs-nfs3-bigdata-server-1.log
cannot create regular file ‘/hdfs/tmp/test.txt’: Input/output error
关键错误信息如下:
2017-07-20 22:01:52,737 WARN oncrpc.RpcProgram (RpcProgram.java:messageReceived(172)) - Invalid RPC call program 100227
2017-07-20 22:04:08,184 WARN nfs3.RpcProgramNfs3 (RpcProgramNfs3.java:setattr(471)) - Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException):Access time for hdfs is not configured. Please set dfs.namenode.accesstime.precision configuration parameter.
at org.apache.hadoop.hdfs.server.namenode.FSDirAttrOp.setTimes(FSDirAttrOp.java:105)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setTimes(FSNamesystem.java:2081)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setTimes(NameNodeRpcServer.java:1361)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setTimes(ClientNamenodeProtocolServerSideTranslatorPB.java:926)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1554)
at org.apache.hadoop.ipc.Client.call(Client.java:1498)
at org.apache.hadoop.ipc.Client.call(Client.java:1398)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:233)
at com.sun.proxy.$Proxy14.setTimes(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.setTimes(ClientNamenodeProtocolTranslatorPB.java:901)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:291)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:203)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:185)
at com.sun.proxy.$Proxy15.setTimes(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.setTimes(DFSClient.java:3211)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattrInternal(RpcProgramNfs3.java:401)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattr(RpcProgramNfs3.java:465)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattr(RpcProgramNfs3.java:407)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.handleInternal(RpcProgramNfs3.java:2193)
at org.apache.hadoop.oncrpc.RpcProgram.messageReceived(RpcProgram.java:184)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline$DefaultChannelHandlerContext.sendUpstream(DefaultChannelPipeline.java:787)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:281)
at org.apache.hadoop.oncrpc.RpcUtil$RpcMessageParserStage.messageReceived(RpcUtil.java:132)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline$DefaultChannelHandlerContext.sendUpstream(DefaultChannelPipeline.java:787)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:296)
at org.jboss.netty.handler.codec.frame.FrameDecoder.unfoldAndFireMessageReceived(FrameDecoder.java:462)
at org.jboss.netty.handler.codec.frame.FrameDecoder.callDecode(FrameDecoder.java:443)
at org.jboss.netty.handler.codec.frame.FrameDecoder.messageReceived(FrameDecoder.java:303)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:555)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:88)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:107)
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:312)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:88)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
根据日志定位问题,发现日志中有相关提示dfs.namenode.accesstime.precision
需要进行配置,在去查看相关配置的含义。
The access time for HDFS file is precise upto this value. The default value is 1 hour. Setting a value of 0 disables access times for HDFS.
理解之后,通过调整,在Ambari-Web
中查看发现默认值 dfs.namenode.accesstime.precision = 0
改为 dfs.namenode.accesstime.precision = 3600000
,根据提示重启集群相关受影响的足迹,即解决问题。
再次进行测试,发现此报错消失。
$ echo aaa > text.2
$ cp text.2 /hdfs/tmp/
$ cat /hdfs/tmp/text.2
aaa
到此,通过touch、echo、cp、cat、mv
等命令测试,依然正常使用,基本的nfs功能测试完成。
NFSGateway的功能相对来说是非常不错的,降低使用HDFS成本的特性,如上我总结的在配置NFSGateway遇到的一些小问题,因为对于几百个节点的HDFS集群来说,有NFS这样的特性,可以让很多Gateway服务器通过FTP-Server接收海量数据,只要进入FTP就进入HDFS集群,这样HDFS入库就变得特别简单,可以节省时间。后续集内容会提供数据对比深度剖析HDFS提供的类似NFSGateway功能的软件性能情况和原理。
事物都是两面性的,带来便利的同时也会带来一定的代价,使用此软件会导致数据传输性能降低很多。在使用dd
命令测试结果如下:
我通过dd
命令生成一个10G的大文件,让后通过hdfs fs put
这样的命令,对比三者的上传性能。
HDFS-NFSGateway 86 MB/秒
HDFS-Fuse 132 MB/秒
HDFS-PUT 310 MB/秒
如上,Hadoop原生提供的put
命令上传效率最高,其次是Fuse,最差的是NFSGateway,这是在5台服务器万兆网络(9.84 Gbits/sec)测试的结果,仅作为参考。
综上所述,我仅仅提供了一些基础的测试数据和结论,使用非原生提供的API进行数据接入,虽然方便了很多,但是性能有很大损耗,这个就是权衡的结果,看是否在你的业务忍耐限度以内,选择哪种方案,得通过数据和相关业务经验结合选择最合适的。
写到这里,内容相对浅显,后续我会对多方测试结果进行整理汇总,发布一版更加有力的测试数据对比情况。最近我也在做一些MPP数据库的测试优化,后续会有更多精彩的生产环境经验积累,原创文章发布,敬请关注。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
参考:
[1]. http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HdfsNfsGateway.html
[2]. https://discuss.pivotal.io/hc/en-us/articles/204185008-Write-data-to-HDFS-via-NFS-gateway-failed-with-Input-output-error-
[3]. https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
