1、你们这个项目数据访问量大不大?
根据项目实际情况来讲,这里给大家举个栗子。
传统项目若不是sass这种的,给企业来应用,用户一般在1000左右,并发的话很少出现,一般通过redis缓存、线程这些就可以处理。
互联网项目,一般差不多的项目日活在1W左右,并发在200到500间,考虑到后期的用户递增,处理方案就比较广泛了。
DNS、服务的前置、后置、缓存优化、线程池、nginx、页面静态化、集群、高可用架构、读写分离等。方案有很多,可以根据项目的实际需要做选择。
2、用redis是做那一块的处理?
咱上面也讲了,redis主要是做缓存处理的。诸如文件、信息的存储这些,根据不同的业务场景应用不同的数据类型,也顺带解决了下面的第4题,在之前的文章中有具体的讲解,这里就不赘述了。
其次,redis还涉及到:redis集群的搭建、雪崩、穿透、一致性、读写分离、主备、过期时间设置、同类型非关系型数据库间的比较,有的可能会问到数据怎么存储的可以结合上面的类型进行讲解,基本就是这些点了。
3、如果redis崩了是怎么处理的?
产生雪崩的原因:
缓存雪崩通俗简单的理解就是:由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,造成系统的崩溃。
基本解决思路如下:
第一,大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,避免缓存失效时对数据库造成太大的压力,虽然能够在一定的程度上缓解了数据库的压力但是与此同时又降低了系统的吞吐量。
第二,分析用户的行为,尽量让缓存失效的时间均匀分布。
第三,如果是因为某台缓存服务器宕机,可以考虑做主备,比如:redis主备,但是双缓存涉及到更新事务的问题,update可能读到脏数据,需要好好解决。
Redis雪崩效应的解决方案:
1、可以使用分布式锁,单机版的话本地锁
当突然有大量请求到数据库服务器时候,进行请求限制。使用所的机制,保证只有一个线程(请求)操作。否则进行排队等待(集群分布式锁,单机本地锁)。减少服务器吞吐量,效率低。
保证只能有一个线程进入 实际上只能有一个请求在执行查询操作。
也可以在此处进行使用限流的策略。
2、消息中间件方式
如果大量的请求进行访问时候,Redis没有值的情况,会将查询的结果存放在消息中间件中(利用了MQ异步步特性)。
3、一级和二级缓存Redis+Ehchache
4、均摊分配Redis的key的失效时间
不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
4、redis你们经常用哪几种数据类型?
String——字符串、Hash——字典、List——列表、Set——集合、Sorted Set——有序集合
5、如何保证redis缓存一致性问题?
1.第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(500);
redis.delKey(key);
}
2.具体的步骤就是:
1)先删除缓存
2)再写数据库
3)休眠500毫秒
4)再次删除缓存
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
3.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
4.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
2、第二种方案:异步更新缓存(基于订阅binlog的同步机制)
1.技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1)读Redis:热数据基本都在Redis
2)写MySQL:增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
1)数据操作主要分为两大块:
一个是全量(将全部数据一次写入到redis)
一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
6、比如你在springboot中自定义了一个属性,如何在一个bean里面引用?
1.在Spring Boot可以扫描的包下
写的工具类为SpringUtil,实现ApplicationContextAware接口,并加入Component注解,让spring扫描到该bean
2.不在Spring Boot的扫描包下方式
这种情况处理起来也很简单,先编写SpringUtil类,同样需要实现接口:ApplicationContextAware
7、JWT执行原理?
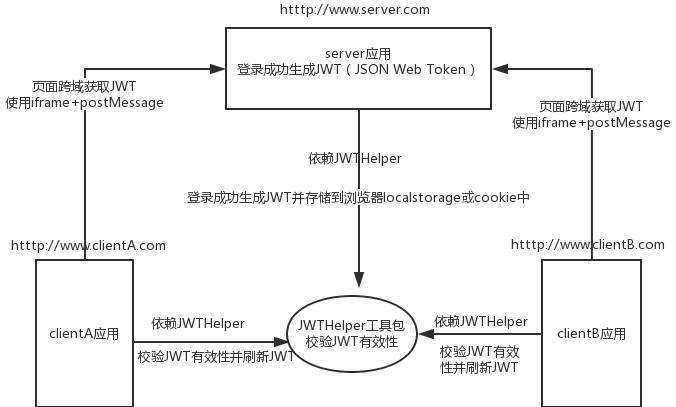
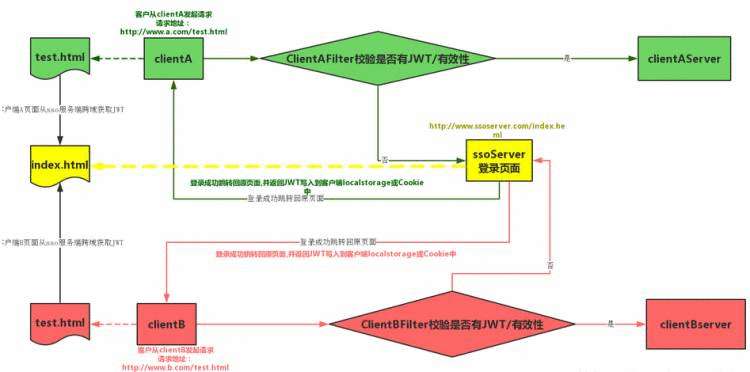
主要注意其认证和授权,其次长令牌、短令牌的失效问题这些点也可以同步看看。
8、注册时由于网络波动原因用户多次点击,数据库没有做唯一索引的校验,你怎么做处理呢?用户发两个请求过来,你怎么处理?
首先对其做拦截,设置在1分钟内发起多次请求只处理一次;
放到消息队列中;
未做唯一索引的校验,这部分可以先从缓存中进行查询,没有再走数据库;
两个请求属于并发操作:
线程有其自带的分发型、锁机制的应用、redis缓存、队列等均可进行处理,可以根据其场景来具体讲解。
9、spring源码读过吗?一个bean的注入过程是怎样的?
这个时候就考咱们的基本功了。
首先创建一个bean类,其中@Configuration
注解和@ComponentScan
注解是必须的,如果你写了前缀,那么就需要@ConfigurationProperties
注解;
然后在配置文件,比如application.propertity中注入属性。
10、springboot想写一个bean注入到IOC容器怎么做?
第一种方式:待注入bean的类添加@Service
或者@Component
等注解
第二种方式:使用@Configuration
和@Bean
注解来配置bean到ioc容器
第三种方式:使用@Import
注解
第四种方式:springboot自动装配机制
11、mybatis防止SQL注入怎么做?为什么#号可以防止SQL注入?
#{}是经过预编译的,是安全的;${}是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入;
PreparedStatement。
12、vue和后端交互接口文档是怎么处理的?
考察的应该是对vue的了解,前后端的交互。可从vue的一些常见应用方式着手。
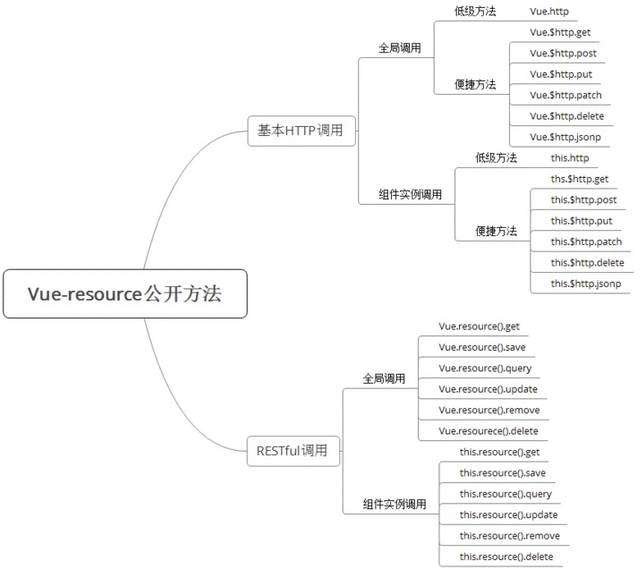
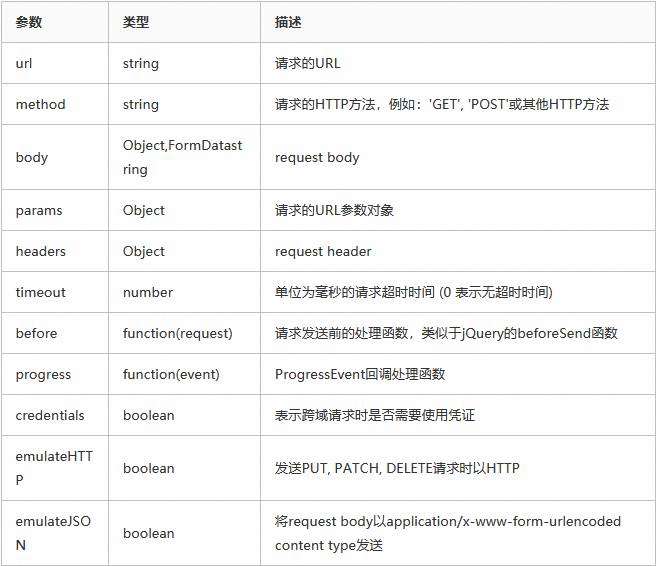
以上是一些参数方法的列举,可以作为参考。
13、AOP用到过吗?每个接口的耗时你是怎么记录的?
首先,需要创建一个类,然后在类名上加上两个注解
@Component
@Aspect
@Component 注解是让这个类被spring当作一个bean管理,@Aspect 注解是标明这个类是一个切面对象。
类里面每个方法的注解含义如下:
@Pointcut 用于定义切面的匹配规则,如果想要同事匹配多个的话,可以使用 || 把
两个规则连接起来,具体可以参照上面的代码
@Before 目标方法执行前调用
@After 目标方法执行后调用
@AfterReturning 目标方法执行后调用,可以拿到返回结果,执行顺序在 @After 之后
@AfterThrowing 目标方法执行异常时调用
@Around 调用实际的目标方法,可以在目标方法调用前做一些操作,也可以在目标方法
调用后做一些操作。使用场景有:事物管理、权限控制,日志打印、性能分析等等。
以上就是各个注解的含义和作用,重点的两个注解就是 @Pointcut 和 @Around
注解,@Pointcut用来指定切面规则,决定哪些地方使用这个切面;@Around
会实际的去调用目标方法,这样就可以在目标方法的调用前后做一些处理,例如事物、权限、日志等等。
需要注意的是,这些方法的执行顺序:
执行目标方法前:先进入 around ,再进入 before
目标方法执行完成后:先进入 around ,再进入 after ,最后进入 afterreturning
实际的日志信息如下,可以看出各个方法的执行顺序:

另外,使用spring aop 需要在spring的配置文件加上以下这行配置,以开启aop :
同时,maven中需要加入依赖的jar包:
org.aspectj
aspectjrt
1.6.12
org.aspectj
aspectjweaver
1.6.12
总结一下,Spring AOP 其实就是使用动态代理来对切面层进行统一的处理,动态代理的方式有:JDK动态代理和 cglib
动态代理,JDK动态代理基于接口实现, cglib
动态代理基于子类实现。spring默认使用的是JDK动态代理,如果没有接口,spring会自动的使用cglib动态代理。
14、设计模式你了解吗?用到过哪些设计模式?
单例、工厂、代理、装饰者等,可以结合项目中的实际应用讲解一下。
15、mybatis访问mapper是怎么走的?
mybatis运行时要先通过resources把核心配置文件也就是mybatis.xml文件加载进来,然后通过xmlConfigBulider来解析,解析完成后把结果放入configuration中,并把它作为参数传入到build()方法中,并返回一个defaultSQLSessionFactory。我们再调用openSession()方法,来获取SqlSession,在构建SqlSession的同时还需要transaction和executor用于后续执行操作。
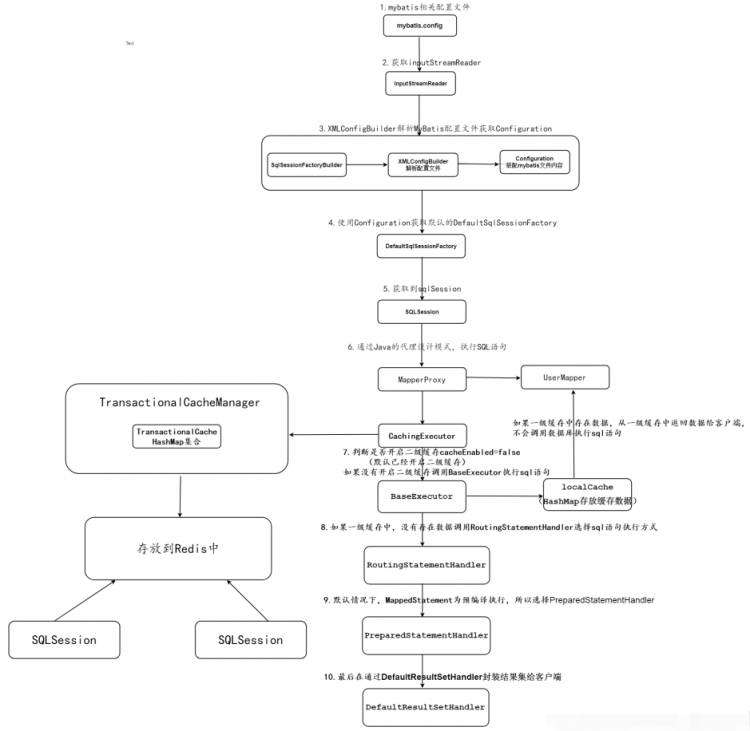 16、代码中用到事务了吗?用的是注解事务还是编程事务?
16、代码中用到事务了吗?用的是注解事务还是编程事务?
一般用的是注解来实现的,具体实现见昨天的面试题讲解。
17、项目上线了吗?
传统项目由于无法直接看到,可以准备一些截图,面试时带上,实际做PPT演示;
互联网项目在手机上准备好面试时直接拿出来讲解也都不错。
这里就告诉我们一个点,提前做好面试的准备。我要讲什么,怎么讲。
考虑好几个点:是什么、为什么、怎么做、收获。









 京公网安备 11010802041100号
京公网安备 11010802041100号