一、安装并配置Tesseract
1、下载Tesseract-OCR (网上直接下载即可)

2、双击安装,选择所有人均可使用,避免权限问题
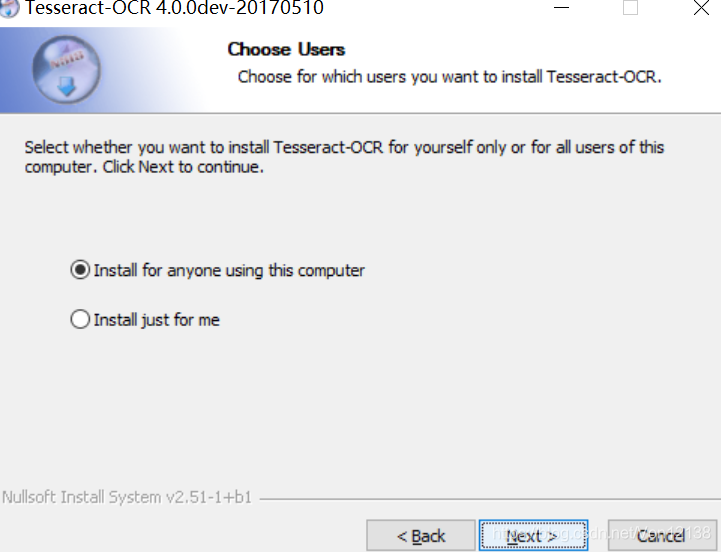
勾选最后一项添加语言包,但是全部勾选需要1.3G,可以点开加号,选择自己所需的语言包即可。
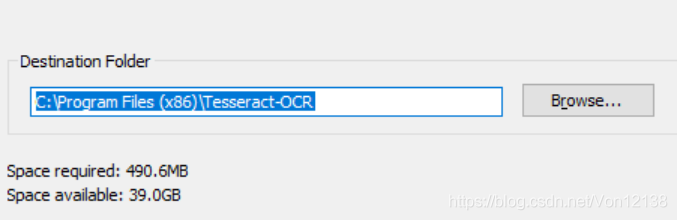
注意:这里最好装在C盘,之前装在F盘报错,无法使用Tesseract
备注:在这里先复制好安装路径,后面还需要将其添加至环境变量中。C:\Program Files (x86)\Tesseract-OCR
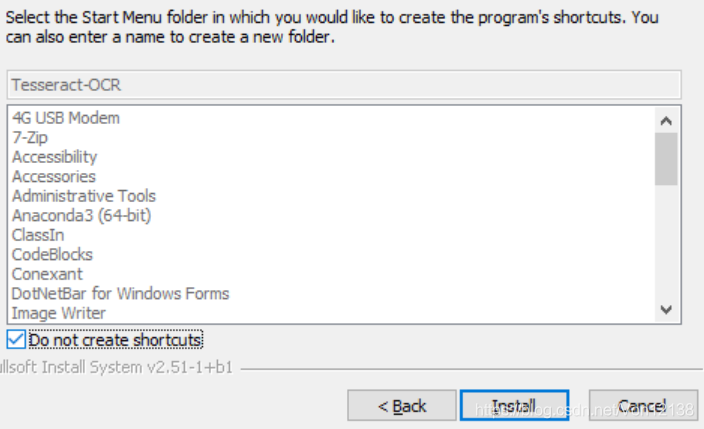
这一步是创建快捷方式,在这里勾选不创建
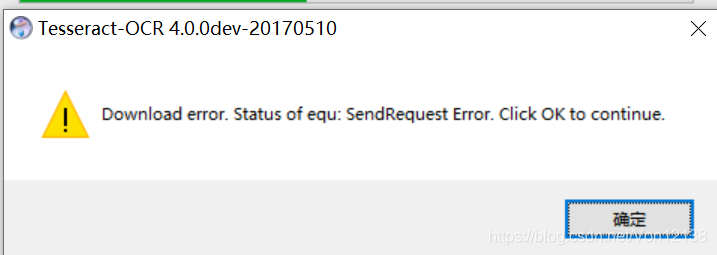
安装过程中,如果出现错误,点击确定即可,并不影响后续使用。
安装完成后,需要将刚才的安装路径添加至环境变量中。在此电脑上右键,选择属性,选择高级系统设置

在高级中选择环境变量
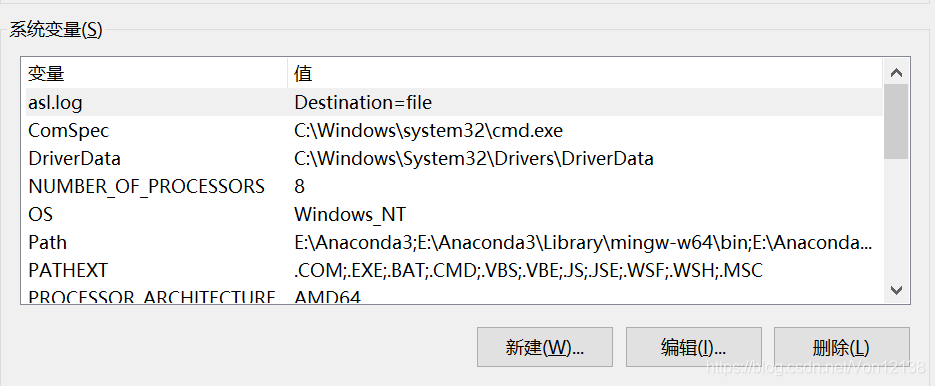
分别在用户变量和系统变量中修改path
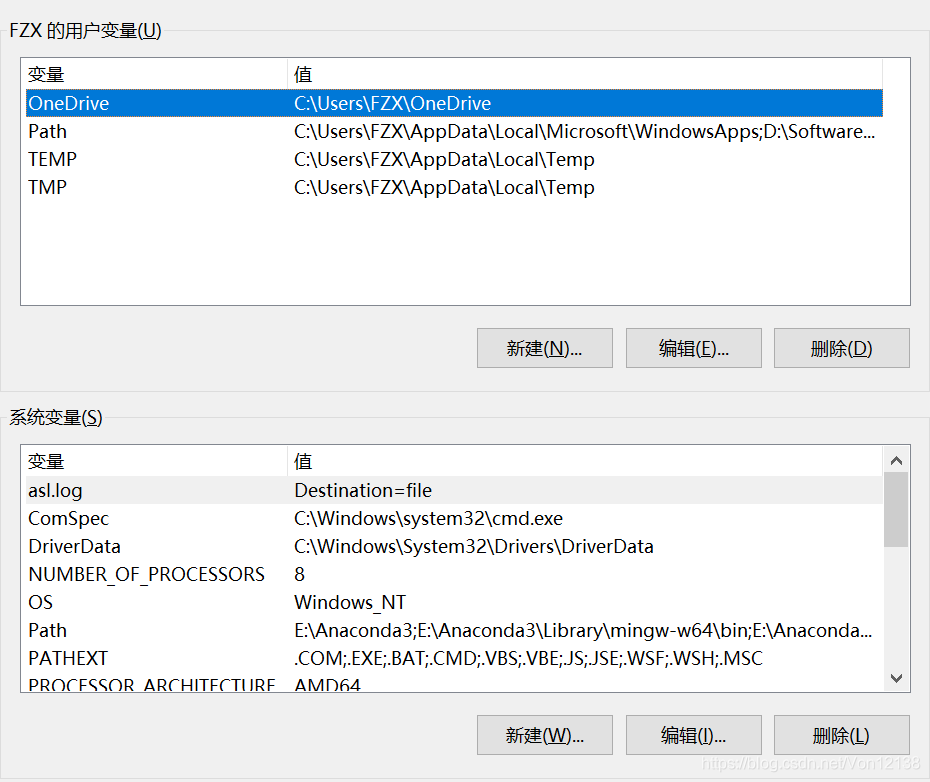
双击Path,点击新建,然后将刚才复制的安装路径复制进来

点击确定后,在系统变量中双击Path,添加,点击确定。
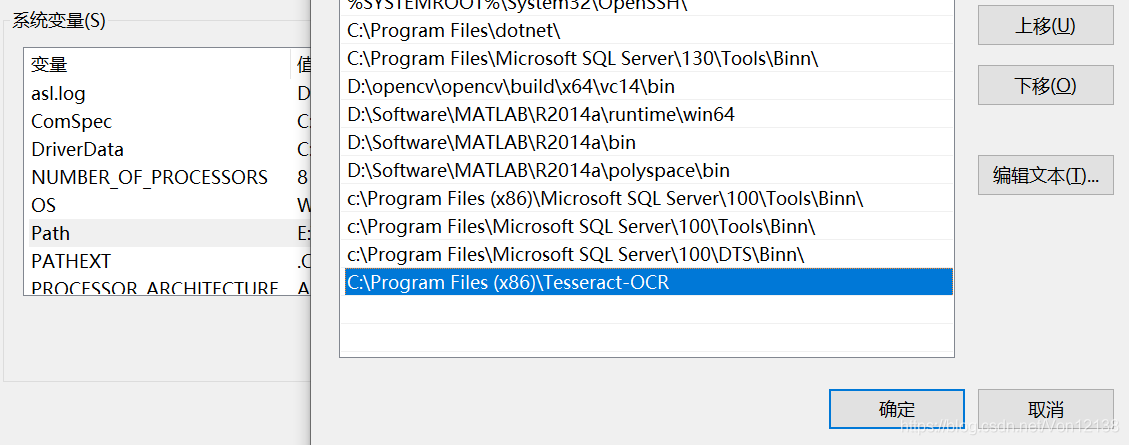
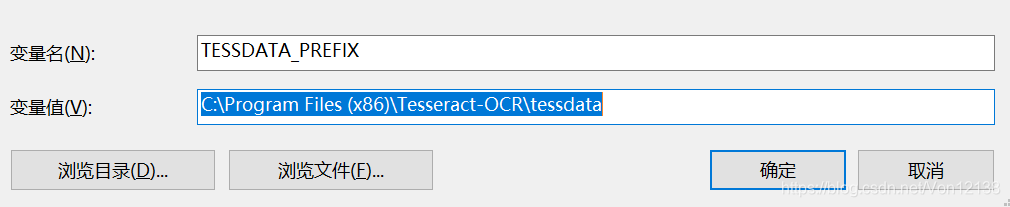
然后在系统变量中,点击新建,新建一个变量名为:TESSDATA_PREFIX
值为:刚才的路径加上 \tessdata
此时,Tesseract 环境配置完成。如何测试是否可以使用?
Win+R 在cmd中输入:tesseract -v 可以查看版本信息
出现以下结果证明已经可以正常使用:

补充:输入:
tesseract --list-langs 来查看本地 Tesseract-ORC 支持语言库
二、使用Tesseract 进行文字识别
1、将需要测试的图片保存为test.jpg ,然后新建一个test.txt文件
(这样测试图片中的文字就会直接读写到文本文件中)
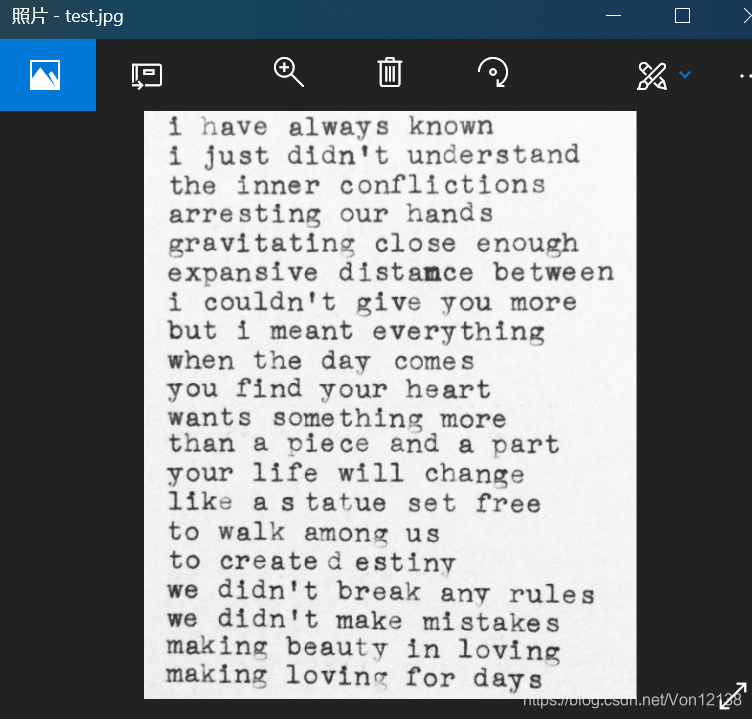
在cmd中先进入桌面,使用 cd desktop , 然后输入: tesseract+空格+路径+空格+文本文件名,回车
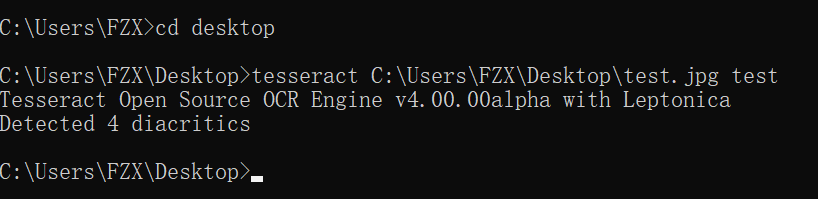
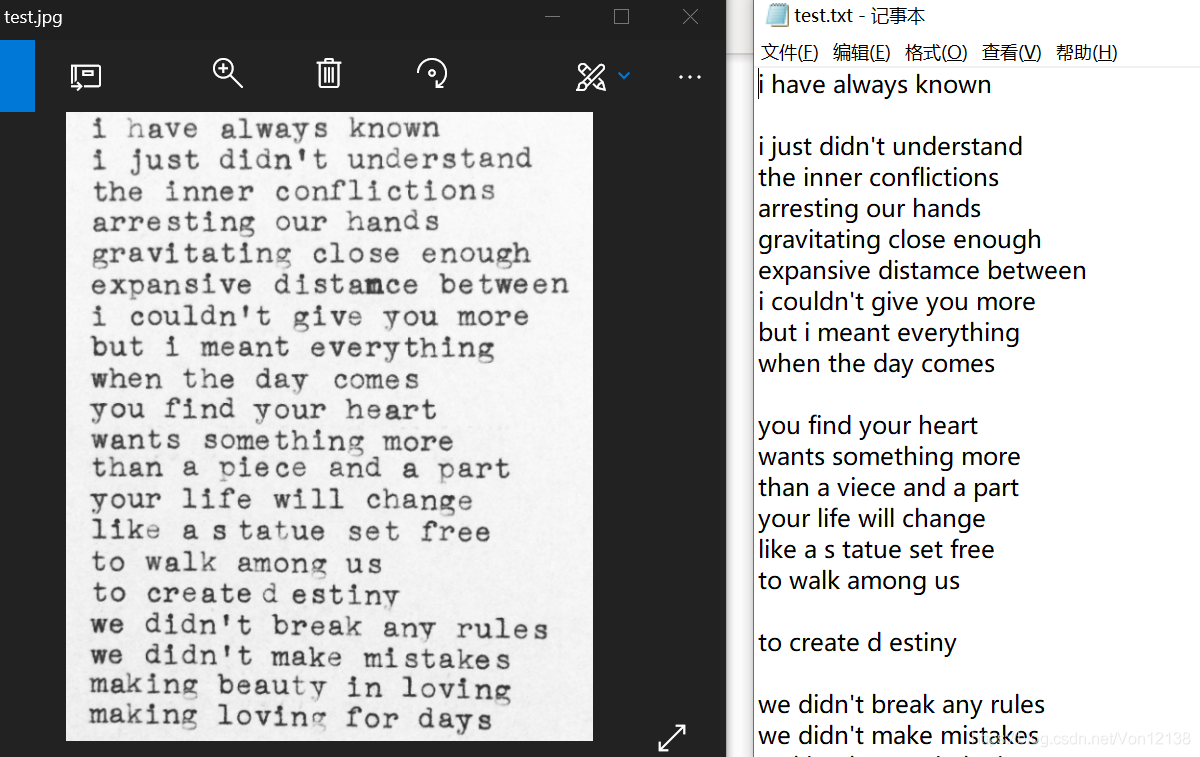
然后可以在文本文件中看到所识别的文字信息,如下图所示:






 京公网安备 11010802041100号
京公网安备 11010802041100号