原文链接:https:arxiv.orgpdf2105.12041.pdf一 背景和意义TextSummarization(文本摘要)Summarizationà为给定的输入文档生
原文链接:https://arxiv.org/pdf/2105.12041.pdf
一 背景和意义
Text Summarization(文本摘要)
Summarizationà为给定的输入文档生成流畅而简洁的摘要,用户通过阅读摘要获取文章的主要内容。
摘要问题的特点:输出的文本要比输入的文本少很多,但却包含着非常多的有效信息。
抽取式就是使用算法从源文档中提取现成的句子作为摘要句组成摘要。
生成式是生成一个序列,通过源文档序列生成摘要序列。
目前,生成式摘要很多都是利用基于深度学习中的seq2seq模型,或者是在以bert为代表的预训练模型
此外,由于现实中往往缺少标注好的摘要数据,所以有很多工作聚焦在无监督的方式,使用自编码器等做无监督的生成式摘要。
比较抽取式和生成式摘要,抽取式有时可能无法简洁凝练地概括原文的内容;而生成式虽然灵活,但是容易产生事实性错误,也就是生成出一些与原文相违背的内容。
评测文本生成的方法:BLEU,ROUGE等。他们基本上都是从基本语义单元的匹配上去评测候选摘要和标准摘要之间的相似性。所以在句法语义方面存在问题,评测质量甚至比不上人工。
因此,如何设计一个合适的评测方法,也是目前文本摘要任务的一个研究方向。
Seq2Seq面临挑战
在生成式摘要中,Seq2Seq模型是一种常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。
· 复杂的摘要场景,如长文档或多文档摘要(MDS),给 Seq2Seq 模型带来了巨大的挑战。
MDS:利用计算机将同一主题下或者不同主题下的多篇文档描述的主要内容通过信息压缩技术提炼成一个文档的自然语言处理技术。
· 因为Seq2Seq 模型在主要依赖于长序列的内容选择和组织方面存在困难。
——如何在复杂的文本输入中利用深层语义结构是进一步提升摘要性能的关键。
· 与序列相比,图(Graph)可以将相关不相交的上下文统一表示为节点,并将它们的关系表示为边,来聚合相关的不相交上下文
——有利于全局结构学习&远程关系建模
本文主要内容
工作一:提出了联合语义图(Unified Semantic Graph)
为了更好的建模长距离关系和全局结构→→建议应用短语级联合语义图来促进内容选择和组织
该图聚合了在上下文中分布的共指短语,以便更好地建模长文档摘要和 MDS 中的长距离关系和全局结构。
· 适用于借助共指解析的信息聚合,这种解析极大地压缩了输入并有利于内容选择。
· 短语之间的关系在组织显著内容方面起着重要作用
工作二:提出了一种基于图的编码器-解码器模型
基于联合语义图,作者进一步提出了一种基于图的编码器解码器模型。通过利用图结构来改进 Seq2Seq 架构的文档表示和摘要生成过程。
Graph Encode:
· 显式建模短语之间的关系以及基于语义图,捕获全局结构,从而有效地编码长序列
· 此外,在图编码过程中还应用了几种图增强方法,挖掘潜在的语义关系
Graph Decode:
· 利用图传播注意力结合图结构来指导摘要生成过程。这可以帮助选择显著内容,并将它们组织成连贯的摘要。
工作三:实验
实验结果表明,模型对长文档摘要和 MDS 的自动和人工评估优于几个强大的baseline,并验证了基于图形的模型的有效性。
二 研究方法
联合语义图——图定义
联合语义图是定义为 G = (V, E) 的异构图。节点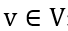 表示短语,边
表示短语,边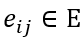 表示短语间的依赖解析关系。
表示短语间的依赖解析关系。
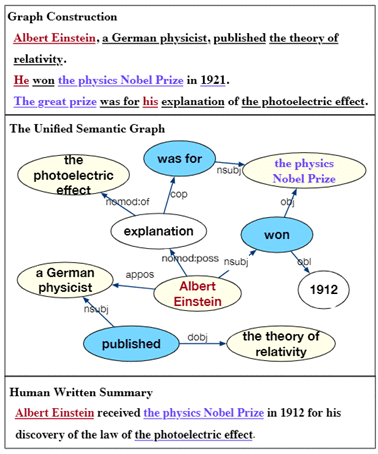
· V 中的每个节点都代表一个,从共同指称短语合并而来的概念。例如,在图中,节点“Albert Einstein”是从“Albert Einstein”和“he”“his”合并而来的,它们通过共指解析表示同一个人。
根据短语类型, 节点可以分为三种类型: 名词短语(N)、动词短语(V)、其他短语(O)。
· 联合语义图中的元路径传达了各种语义关系。比如说,元路径 O-N 表示修饰关系,名词短语之间的元路径 N-N 表示同位关系或附加关系。
meta-path是连接两个实体的一条特定的路径
此外,两跳元路径可以表示图中更复杂的语义关系。 例如,名词-动词-名词结构, [Albert Einstein]-[won]-[the Physics Nobel Prize] 表示 SVO(主语-动词-宾语)关系。 因此,对一些两跳元路径进行建模也至关重要。
联合语义图——图定义
简单来说,首先将tokens合并到短语中,然后将共同指代的短语合并到节点中,从而从句子中提取短语及其关系。
具体上,首先利用CoreNLP 获取输入序列的共指链和每个句子的依存树。基于依存树,将形成完整语义单元的连续tokens合并为一个短语。然后,将来自不同位置的相同短语和相同共指链中的短语合并,形成语义图中的节点。
(coreNLP是斯坦福大学开发的一套关于自然语言处理的工具,使用简单功能强大,有命名实体识别、词性标注、词语词干化、语句语法树构造还有指代关系等功能。)
基于图的摘要生成模型——图编码器&图解码器
下面是作者的基于图的生成式摘要模型,主要由图编码器和图解码器组成。
编码阶段:
· 采用一个文档或一组文档的串联,作为文本输入,通过文本编码器对其进行编码,获得一系列的本地token表示
· 图编码器进一步将联合语义图作为图输入,并利用图中的显式语义关系获得全局图表示。而且还基于几种图增强方法,挖掘文本输入中的隐含语义关系。
解码阶段:
· 图解码器利用图结构通过图传播注意力来指导摘要生成,这有助于突出内容的选择和组织,生成更多信息和连贯的摘要。
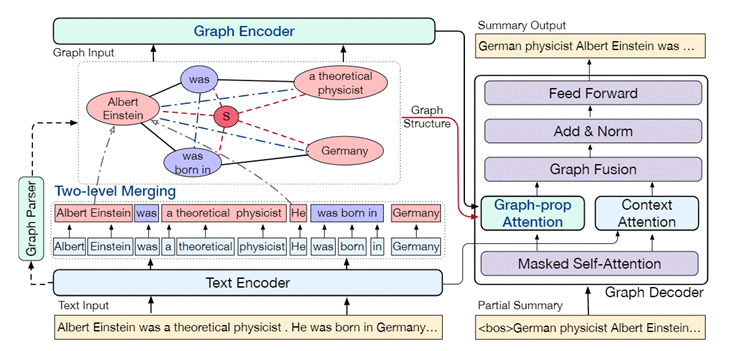
基于图形的摘要生成模型
图节点表示是通过在两步合并中合并token表示来初始化的。图编码器对增强的图结构进行建模。解码器同时处理token和节点表示,并通过图传播注意利用图结构。
基于图的摘要生成模型——文本编码器
按顺序表示局部特征à预训练的语言模型 RoBERTa
RoBERTa改进自BERT
BERTà多层Transformer结构的堆叠 BERT利用MLM进行预训练并且采用深层的双向Transformer组件(单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。
基于图的摘要生成模型——图编码器
通过文本编码器获得token表示之后,进一步对图结构进行建模来获得节点表示。作者基于token表示和图构造中的token-to-node对齐信息来初始化图中的节点表示。
初始化后:应用图编码层对显式语义关系特征进行建模,应用几种图增强方法来学习图传达的隐式内容。
节点初始化
两步合并:token合并和短语合并
· token合并:将本地token特征压缩并生成为更高级别的短语表示。
· 短语合并:在广泛的上下文中聚合共同指代的短语,捕获长距离和跨文档关系。
这两个合并步骤是通过平均池化来实现的。
图编码层

个人理解,图编码层参考了Graph2Seq的节点嵌入表示部分。
图增强
作者为了挖掘隐式信息,采取了几种图增强方法
首先,为了解决原始有向边不足以学习后向信息的问题,在图中添加反向边和自环边
· Supernode
作者为了加强图建模的鲁棒性并学习更好的全局表示,添加了一个特殊的超级节点,与图中的每个其他节点连接以增加连通性。
· Shortcut Edges
以前的工作表明,CNN在建模多hop关系方面还较弱。然而,长度为 2 的元路径表示丰富的语义结构,因此需要进一步建模节点之间的两跳关系。 所以作者在每个节点及其二阶邻居之间添加了快捷边。
基于图的摘要生成模型——图编码器
token和节点表示有利于不同方面的摘要生成。token表示善于捕捉局部特征,而图形表示提供全局和生成特征。所以,为了利用这两种表示,作者应用一堆基于 Transformer 的图解码层作为解码器。它处理这两种表示并将它们融合,用来生成摘要。注意,解码器是同时处理token和节点表示的。
令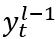 表示第 (l − 1) 个图解码层的输出中的第 t 个摘要 token表示。
表示第 (l − 1) 个图解码层的输出中的第 t 个摘要 token表示。
对于图注意力,作者应用了multi-head attention,其中作为q,节点表示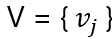 作为k 和 v的:
作为k 和 v的:

其中,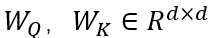 是参数权重,
是参数权重,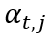 表示节点 j 到的显著分数。
表示节点 j 到的显著分数。
作者将全局图向量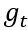 计算为节点值的加权和:
计算为节点值的加权和: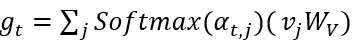 。其中,
。其中,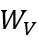 是可学习的参数。
是可学习的参数。
另一边,计算和token表示之间的multi-head attention,用和前面求全局图向量一样方法求上下文文本向量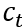 。
。
然后,使用一个前馈神经网络(图融合层)融合连接两个特征: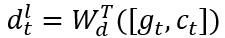
其中,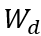 是线性变换参数,
是线性变换参数,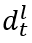 是token和图的混合表示。
是token和图的混合表示。
在经过 layer-norm 层和前馈层之后,第 l 个图解码层的输出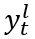 用作下一层的输入,也用于在最后一层生成第 t 个token。
用作下一层的输入,也用于在最后一层生成第 t 个token。
基于图的摘要生成模型——图传播注意力
作者发现前面的对图应用multi-head attention时,图解码器只线性地关注节点表示,忽略了图结构。
因此作者提出利用图传播注意力,利用图结构来指导摘要生成过程。通过进一步利用语义结构,解码器可以更有效地选择和组织显著内容。
图传播注意力包括两个步骤:显著分数预测和分数传播。
第一步,线性预测每个节点的显著分数。
应用公式(1)求出multi-head attention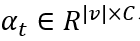 作为显著分数,其中 |v| 是图中节点的数量,C 是注意力头的数量。
作为显著分数,其中 |v| 是图中节点的数量,C 是注意力头的数量。
第二步,通过分数传播使显著分数结构化。
因为在每个摘要解码步骤中,只有部分内容是显著的。 所以,对于每个节点只在图中传播其显著分数 p 次,最多聚合 p-hop 关系。令 表示预测的初始显著分数,第 p 次传播后的显著分数为:
表示预测的初始显著分数,第 p 次传播后的显著分数为:
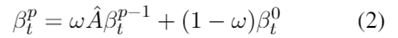
其中,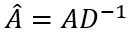 是图的度归一化的邻接矩阵,
是图的度归一化的邻接矩阵,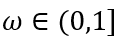 是显著分数的传播概率,ω是向邻居节点传播的概率,1 – ω是从初始值重新开始的概率 。把
是显著分数的传播概率,ω是向邻居节点传播的概率,1 – ω是从初始值重新开始的概率 。把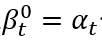 代入公式(2),图传播过程也可以表述为:
代入公式(2),图传播过程也可以表述为:
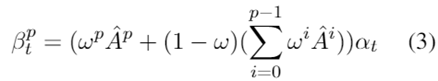
在显著分数传播的 p 步之后,利用节点值的加权和计算图向量:
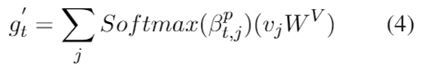
然后融合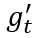 和的输出来生成第 t 个摘要token,如前所述。
和的输出来生成第 t 个摘要token,如前所述。
三 实验
自动评价
数据集:SDS 数据集BIGPATENT和 MDS 数据集WikiSUM
评价指标:ROUGE-1、ROUGE-2、ROUGE-L、BERTScore
与所有基线相比,BASS 在所有四个指标上都取得了很大的改进。
为了分析联合语义图如何有益于摘要学习,作者对图结构进行了消融研究。

在通过完全连接所有节点,去除短语之间的显式关系后,R-1 指标较明显的下降了,这表明短语间的关系可以提高生成摘要的信息量。
进一步去除短语合并后,所有指标的性能都下降,这表明长距离关系有利于摘要的信息性。
作者还通过消融研究验证了图编码器中的图增强方法和图解码器中的图传播注意力的有效性。然后,没有间隙传播注意力的实验结果说明,联合语义图的结构也有利于解码。总体而言,模型的性能在去除捷径边缘时下降最多,这表明丰富的潜在信息有利于总结最后,删除所有与图形相关的组件,所有指标的性能都会急剧下降。
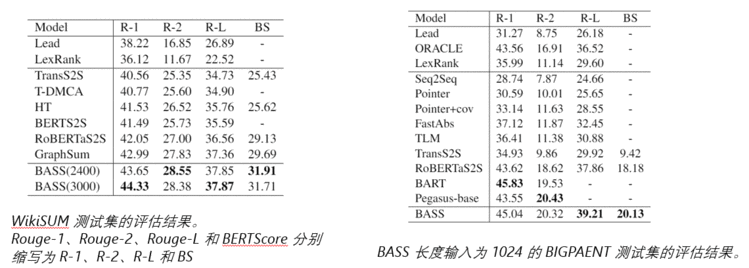
· 长度比较
HT 的性能在输入长度大于 800 后保持稳定。
GraphSum 在 2400 处取得了最好的性能,当输入长度达到 3000 时其性能开始下降。BASS 的R-1在 3000 处显著增加。
· 生成性分析
与GraphSum、HT 相比,BASS 生成更多生成摘要,并且比 RoBERTaS2S 更弱。
RoBERTaS2S 通常会生成与上下文无关的内容
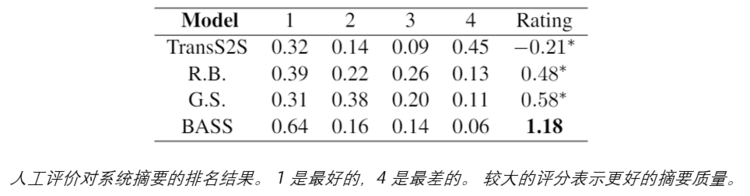
人工评价
由于专利数据集 BIGPATENT 包含大量术语并且需要注释者的专业背景知识,我们选择 WikiSUM 作为评估数据集。
邀请 2 位注释者独立评估不同模型的摘要。注释者通过考虑以下标准对摘要进行排名来评估摘要的整体质量:
(1)信息性:摘要是否传达了输入的重要和忠实事实?
(2)流畅性:摘要是否流畅、语法、连贯?
(3) 简洁性:摘要是否简洁,没有描述太多细节?
四 总结
在本文中,作者建议利用联合语义图来提高用于长文档摘要和 MDS 的神经生成模型的性能。
进一步提出了一个基于图的编码器-解码器模型,利用图结构来改进文档表示和摘要生成过程。
长文档摘要和 MDS 的实验表明,作者的模型优于几个强大的基线,这证明了基于图的模型的有效性以及统一语义图对长输入生成摘要的优越性。
尽管基于神经网络的摘要系统已经取得了显著成就,但它们仍然不能真正理解语言和语义。所以,作者认为,将语言结构作为先验知识纳入深度神经网络,是帮助总结系统的一种直接有效的方法。
收获与感悟:
首先,通过这篇文章,我对文本摘要任务有了进一步的认识,了解了他们的输入、输出、评价方法和被普遍关注的问题(比如,长序列文本摘要生成、语义语法分析、生成摘要的可读性等)
第二,我初步了解了graph2seq等模型,学习了PageRank、ROUGE等概念。
第三,我进一步认识到Graph在一些图结构问题上的优势和应用。
第四,通过对本文的BASS模型的学习,对于Encode和Decode模块的改进方法也有了更多的认识。
最后,对于本文的BASS模型,个人学习到了对联合语义图去冗余、长度大于 2 的元路径处理、图增强等方面的改进思想。






 京公网安备 11010802041100号
京公网安备 11010802041100号