作者:排骨冬菇面 | 来源:互联网 | 2023-08-20 14:09
这部分内容是文本生成技术的基础,也是我的科研内容。嘻嘻嘻=-=
在线性回归 & Softmax与分类模型 & 多层感知机中提到,建模的pipeline包括8个步骤,从大方向来看,可以归为2类,第1步(准备数据集)归为一类,called“数据准备”;2-8步归为一类,called“模型”。对于“数据准备”,也许有的结构化数据可以省略这一步,但像文本这样的非结构化数据却是一定要有这一步的,因为神经网络模型要求输入是数值型。
目录
目录
一 文本预处理
二 语言模型(基于统计的模型)
1 语言模型
2 n元语法模型
3 评价
三 循环神经网络基础(基于神经网络的模型)
3.1 问答
四、时序数据batch的构建
一 文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,在送入神经网络模型之前,我们需要构建一个词表Vocab,这个词表的主要功能是实现token到id的映射和id(词的索引)到token(词)的映射。为了构建词表,一般有以下步骤:
step 1:分词、去低频词、去停止词(去停止词是非必选项,根据具体任务而定)
分词是NLP的基础任务,目前有很多工具库可以使用,常见的有Jieba、NLTK、spacy,当然这些工具库能做的事情可不止分词这件事=-=
什么?你问各个工具库的优缺点?该选择哪个?
(待更新……)
step 2:构建Vocab
Vocab其实就是形如{token:id}的字典,构造方式随便~不过为了使用方便,常写一个Vocab类,大体如下:
import collections
class Vocab(object):def __init__(self, tokens, min_freq=0, use_special_tokens=False):# tokens:分词后的文本,形如[[逗号分割的句子1的各个词],[句子2的各个词],[……]]counter = count_corpus(tokens) # : self.token_freqs = list(counter.items())self.idx_to_token = []if use_special_tokens:# padding, begin of sentence, end of sentence, unknownself.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)self.idx_to_token += ['', '', '', '']else:self.unk = 0self.idx_to_token += ['']self.idx_to_token += [token for token, freq in self.token_freqsif freq >= min_freq and token not in self.idx_to_token]self.token_to_idx = dict()for idx, token in enumerate(self.idx_to_token):self.token_to_idx[token] = idx# python特殊函数# 如果一个类表现得像一个list,要获取有多少个元素,就得用 len() 函数。# 要让 len() 函数工作正常,类必须提供一个特殊方法__len__(),它返回元素的个数。def __len__(self):return len(self.idx_to_token) # 字典大小# 这个方法返回与指定键token想关联的值。它的实例对象(假定为p),可以像这样p[key] 取值def __getitem__(self, tokens):# token 2 idif not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):# id 2 tokenif not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]def count_corpus(sentences):tokens = [tk for st in sentences for tk in st]return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
step 3:预训练word Embedding(非必选)
可以用自己的语料训练;也可以下载别人训练好的;当然也可以不训练,直接随机初始化词向量。
二 语言模型(基于统计的模型)
1 语言模型
语言模型用来评估一段文本成句的概率

语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。概率怎么计算呢?根据语料库中的文本计算频率来代替,当然了,还有一些平滑技术……
参数空间为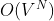 ,V是词表大小,N表示句子长度。
,V是词表大小,N表示句子长度。
当序列⻓度增加时,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。n元语法通过 ⻢尔可夫假设(虽然并不一定成立)简化了语言模型的计算。这里的⻢尔可夫假设是指一个词 的出现只与前面n个词相关,即n阶⻢尔可夫链(Markov chain of order n)。
2 n元语法模型
N元语法是基于n − 1阶⻢尔可夫链的概率语言模型,其中n权衡了计算复杂度和模型准确性。常用bigram和trigram。
n元语法模型的缺点:
- 参数空间大:
- 稀疏:很多参数都是0。根据zipf定律,很多词都是长尾词,在语料库中出现次数很少,频率几乎为0,那么某n个词同时出现的概率就更低了。
- n元语法模型仅能记忆n-1个历史词汇
3 评价
如何评价语言模型的好坏?困惑度!困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在语言模型中,困惑度必须小于词典大 小vocab_size。
三 循环神经网络基础(基于神经网络的模型)
n元语法模型仅能记忆前n-1个历史信息(n一般为2或者3),RNN的记忆能力更胜一筹。顾名思义,RNN是一种神经网络,与多层感知机不同的是,RNN带有隐藏状态,可以记忆历史信息,按时间步循环,故名循环神经网络。如下图所示(引自《动手学深度学习》)
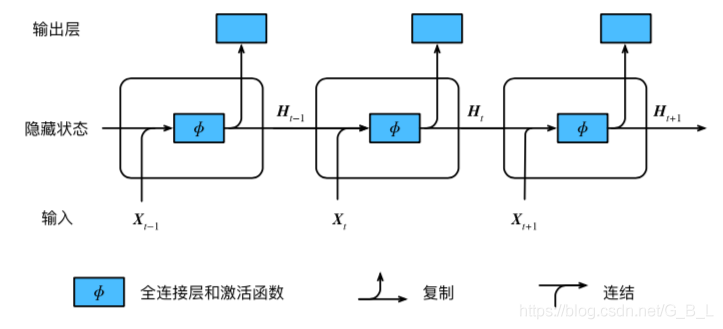
以上模型的优点显而易见,能记忆历史信息。那它有什么缺点呢?
- 循环神经网络中较容易出现梯度衰减或梯度爆炸。应对梯度爆炸的常用方法是梯度裁剪。
3.1 问答
第一,在一些任务场景下,比如机器翻译,不同样本的输入长度和输出长度是不同的,而全连接固定了输入和输出大小。
第二,RNN存在参数共享,不同时间步之间共享参数,可以重复使用一种pattern,这样做减少了参数量,降低了模型的复杂度。

one-to-one:
one-to-many:
many-to-one:情感分类
many-to-many(输入输出长度不一定相同):机器翻译
many-to-many(输入输出长度相同)
- 深度循环神经网络的前向传播是先纵向传播还是先按时间步传播?
四、时序数据batch的构建
文本算是一类时序数据了,在模型训练时,我们往往送给模型一小批量的数据,这一批数据称为一个batch。在时序数据上如何采样得到batch数据?
时序数据采样方式包括随机采样和相邻采样。使用这两种方式的循环神经网络训练在实现上略有不同。

对于一段文本序列,蓝色框出来的是一个样本,样本中含有n个词,表示n个时间步。上图中有4个样本。随机采样就是随机取batch大小个样本组成一个batch。编程上的实现就是先把样本shuffle,然后依次按顺序取batch个样本组成一个个的batch喂进模型。
除对原始序列做随机采样之外,我们还可以令相邻的两个随机小批量在原始序列上的位置相毗邻。这时候,我们就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态, 从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网 络造成了两方面影响:一方面,在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状 态;另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所 有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。 为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将 隐藏状态从计算图中分离出来。






 京公网安备 11010802041100号
京公网安备 11010802041100号