学习笔记来源:Python文本挖掘视频教程
补充文献:
从离散到分布,盘点常见的文本表示方法
文本向量化(理论篇)
所谓文档信息的向量化,就是将信息数值化,从而便于进行建模分析
自然语言处理面临的文本数据往往是非结构化杂乱无章的文本数据,而机器学习算法处理的数据往往是固定长度的输入和输出。因而机器学习并不能直接处理原始的文本数据。必须把文本数据转换成数字,比如向量。
因此
文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。文本表示是自然语言处理的开始环节。
文本表示按照细粒度划分,一般可分为字级别、词语级别和句子级别的文本表示。
文本表示分为离散表示和分布式表示。离散表示的代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。分布式表示也叫做词嵌入(word> embedding),经典模型是word2vec,还包括后来的Glove、ELMO、GPT和最近很火的BERT。
(引自:https://blog.csdn.net/nc514819873/article/details/89444948)
也就是
常见的文本表示模型有One-hot、词袋模型(BOW)、TF-IDF、N-Gram和Word2Vec
One-Hot几乎是最早的用于提取文本特征的方法,将文本直接简化为一系列词的集合,不考虑其语法和词序关系,每个词都是独立的。
特征提取方法: one-hot 和 TF-IDF
例1
可以用one-hot编码的方式将句子向量化
对类别数据做one_hot_encoding编码处理
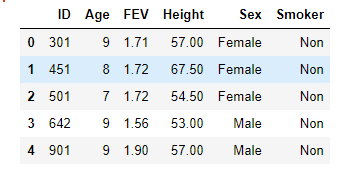
处理后
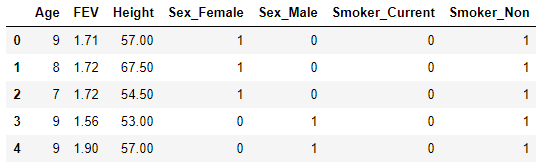
例2

在One-Hot 表示法的基础上,对词表中的每一个词在该文本出现的频次进行记录,以表示当前词在该文本的重要程度。
词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型的三部曲:分词(tokenizing),统计修订词特征值(counting)与标准化(normalizing)。
词袋模型中词和文本的关系就相当于文本是一个袋子,词只是直接装在袋子里
显然,词袋模型是比较简单的模型,对文本中的信息有较多丢失,但已经可以解决很多实际问题,词袋模型的提出最初是为了解决文档分类问题,目前主要应用在NLP、IR、CV等领域
优点:
缺点:
词袋模型的gensim实现
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
基本概念
语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
稀疏向量(Sparse> Vector):通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的tuple。
模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。(引自:https://www.cnblogs.com/iloveai/p/gensim_tutorial.html)
建立字典
Dictionary类用于建立word<->id映射关系&#xff0c;把所有单词取一个set&#xff08;&#xff09;&#xff0c;并对set中每个单词分配一个ld号的map
Dictionary类属性
from gensim. corpora import Dictionary
texts&#61;[[&#39; human&#39;,&#39; interface&#39;,&#39; computer&#39;]]
dct&#61;Dictionary(texts)# fit dictionary dct. num nnz

向字典中增加词条
dct.add_documents([["cat","say","meow"],["dog"]])
dct.token2id
id 号增加了3、4、5、6

转换为BOW稀疏向量
稀疏向量&#xff08;Sparse> Vector&#xff09;&#xff1a;通常&#xff0c;我们可以略去向量中多余的0元素。此时&#xff0c;向量中的每一个元素是一个(key, value)的tuple。
转换为BOW格式&#xff1a;list of&#xff08;token_id&#xff0c;token_count&#xff09;
dct.doc2bow&#xff08;document&#xff1a;用于转换的词条listallow update&#61;False&#xff1a;是否直接更新所用字典return missing&#61;False&#xff1a;是否返回新出现的&#xff08;不在字典中的&#xff09;词
&#xff09;
例如
现在已有的字典词包括

若return_missing&#61;false&#xff0c;则输出的稀疏向量为

表明在文档中id为3&#xff0c;6的词汇各出现了1次&#xff0c;其他词汇则没有出现
若return_missing&#61;True&#xff0c;返回新出现的&#xff08;不在字典中的&#xff09;词

转换为BOW长向量
按照输入1ist的顺序列出所出现的各词条ID
doc2idx(document&#xff1a;用于转换的词条listunknown_word_index&#61;-1&#xff1a;为不在字典中的词条准备的代码
)
字典中没有这个词就返回 -1

基本思路&#xff1a;
首先是将原始文档进行分词并清理&#xff0c;拼接为同一个df&#xff0c;汇总并转换为文档-词条矩阵格式&#xff0c;去除低频词
CountVectorizer类&#xff0c;通过这一类中的功能&#xff0c;可以很容易地实现文本的词频统计与向量化。。
它主要是把新的文本转化为特征矩阵&#xff0c;只不过这些特征是已经确定过的。而这个特征序列是前面的fit_transfome()输入的语料库确定的特征。
class sklearn.feature_extraction.text.CountVectorizer(input&#61;’content’, encoding&#61;’utf-8’, decode_error&#61;’strict’, strip_accents&#61;None, lowercase&#61;True, preprocessor&#61;None, tokenizer&#61;None, stop_words&#61;None, token_pattern&#61;’(?u)\b\w\w&#43;\b’, ngram_range&#61;(1, 1), analyzer&#61;’word’, max_df&#61;1.0, min_df&#61;1, max_features&#61;None, vocabulary&#61;None, binary&#61;False, dtype&#61;
比较重要的参数&#xff1a;
①min_df / max_df
词频绝对值/比例的阈值&#xff0c;在此范围之外的将被剔除。小数格式说明提供的是百分比&#xff0c;如0.05指的就是5%的阈值。其详细含义如下
max_df&#xff1a;浮点数&#xff0c;取值范围[0.0,1.0]或整数&#xff0c;默认值为1.0,当构建词汇表时&#xff0c;词语文档频率高于max_df&#xff0c;则被过滤。当为整数时&#xff0c;词语文档频次高于max_df时&#xff0c;则被过滤。当vocabulary不是None时&#xff0c;该参数不起作用
min_df&#xff1a;浮点数&#xff0c;取值范围[0.0,1.0]或整数&#xff0c;默认为1&#xff0c;该参数除了指下限其他都同max_df
比如
min_df &#61; 10&#xff0c;指的是至少有10个文档包含这个词条&#xff0c;才会保留
max_df&#61; 30&#xff0c;指的是如果超过30个文档包含这个词条&#xff0c;将会被提剔除
②max_features
整数或None&#xff0c;默认为None。根据term frequence排序后的vocabulary的前max_features个词作为vocabulary。如果参数vocabulary不是None&#xff0c;则该参数不起作用
其他参数&#xff1a;https://zhuanlan.zhihu.com/p/59413389
CountVectorizer.fit_transform(raw_documents)
对文档进行学习&#xff08;处理&#xff09;&#xff0c;返回term-document matrix
等价于先调用fit函数&#xff0c;然后再调用transform函数&#xff0c;但是效率更高
from sklearn.feature_extraction.text import CountVectorizer
countvec &#61; CountVectorizer()
x&#61;countvec.fit_transform([&#39;郭靖 和 哀牢山 三十六 剑 。&#39;, &#39;黄蓉 和 郭靖 郭靖&#39;]) # 一次搞定
type(x)
x.todense() # 将稀疏矩阵直接转换为标准格式矩阵
countvec.get_feature_names() # 词汇列表&#xff0c;实际上就是获取每个列对应的词条
countvec.vocabulary_ # 词条字典

countvec &#61; CountVectorizer(min_df &#61; 2)
在两个以上文档中出现的才保留 或者 如果最小词频小于2将会被剔除

将1000条评论数据向量化
import pandas as pd
import numpy as np
import osos.chdir(r&#39;C:\Users\Administrator\Desktop&#39;)
df &#61; pd.read_excel(&#39;评论.xlsx&#39;)
df.head()

# 加载停用词
stop_words &#61; []
with open(r"C:\\Users\\Administrator\\Desktop\\chineseStopWords.txt", &#39;r&#39;) as f:lines &#61; f.readlines()for line in lines:stop_words.append(line.strip())
stop_words[:10]

# 分词并去除停用词和短词
import jieba def my_cut(text): return [w for w in jieba.cut(text) if w not in stop_words and len(w)>1]rawchap &#61; [ " ".join(my_cut(w)) for w in df[&#39;评论&#39;]]
rawchap

from sklearn.feature_extraction.text import CountVectorizer
countvec &#61; CountVectorizer(min_df &#61; 5) # 如果最小词频小于5将会被剔除res &#61; countvec.fit_transform(rawchap)
res.todense()

countvec.get_feature_names()

词袋模型完全无法利用语序信息
比如&#xff1a;我帮你vs你帮我P(我帮你) &#61; P(我) * P(帮) * P(你)
Bi-gram&#xff1a;进一步保留顺序信息&#xff0c;两个两个词条一起看&#xff0c;可以保留更多的文本有效信息
P(我帮你) &#61; P(我) * P(帮|我) * P(你|帮){“我帮”&#xff1a;1&#xff0c;“帮你”&#xff1a;2“你帮”&#xff1a;3“帮我“&#xff1a;4}我帮你>[1&#xff0c;1&#xff0c;0&#xff0c;0]
你帮我>[0&#xff0c;0&#xff0c;1&#xff0c;1]
以此类推
从Bi-gram到N-gram&#xff0c;考虑更多的前后词
可以直接扩展至trigram、4-gram直至N-gram
N-gram模型就是基于马尔科夫假设&#xff0c;下一个词的出现仅依赖前面的一个或n个词
当N&#61;1时称为unigram&#xff0c;N&#61;2称为bigram&#xff0c;N&#61;3称为trigram&#xff0c;假设下一个词的出现依赖它前面的一个词&#xff0c;即 bigram&#xff0c;假设下一个词的出现依赖它前面的两个词&#xff0c;即 trigram&#xff0c;以此类推。
优点&#xff1a;
考虑了词的顺序&#xff0c;信息量更充分
长度达到5之后&#xff0c;效果有明显提升
缺点&#xff1a;
词表迅速膨胀&#xff0c;数据出现大量的稀疏化问题
每增加一个词&#xff0c;模型参数增加40万倍

离散表示方式面临无法衡量词向量之间的关系的问题&#xff0c;比如无法区分近义词&#xff08;老公、丈夫、当家的…&#xff09;&#xff0c;每一个词都是用不同的向量表示&#xff0c;各种度量&#xff08;与或非、距离&#xff09;都不合适&#xff0c;只能靠人工字典进行补充。并且 词表维度随着语料库增长膨胀
从大量的文本中反复发现相关联的上下文信息
引用&#xff1a;NLP模型笔记 — 分布式表示
离散表示

分布式表示

引用&#xff1a;http://www.pinlue.com/article/2019/07/2022/189350673206.html
分布式表示的概念(由很多元素组合的表示&#xff0c;这些元素之间可以设置成可分离的&#xff0c;相互独立的)是表示学习最重要的工具之一。分布式表示非常强大&#xff0c;因为他们能够用具有k个值的n个特征去描述k^n个不同的概念。
将分布式表示用于NLP
分布式表示
词之间存在相似关系
包含更多信息
事先决定用多少维度的向量来表示这个词条
所有的词都在同一个高维空间中构成不同的向量
所有训练方法都是在训练语言模型的同时&#xff0c;顺便得到词向量的
总之&#xff0c;分布式表示实际上就是指用特征来表示&#xff0c;利用上下文信息&#xff0c;或者更具体一点&#xff0c;与一个词前后相邻的若干个词&#xff0c;来提取出这个词的特征向量。
只要数据量足够&#xff0c;分布式表示方法挖掘信息的能力更强大
词文档的共现矩阵主要用于发现主题(topic)&#xff0c;用于主题模型
考虑上下文位置信息
·I like deep learning.
·I like NLP.
·I enjoy modeling.

确定取词长度&#xff0c;取词长度为1的结果
窗囗长度越长&#xff0c;则信息量越丰富&#xff0c;但数据量也越大
共现矩阵的行/列数值自然就表示出各个词汇的相似度&#xff0c;从而可以用作分析向量
共现矩阵存在的问题
也就是面临稀疏性问题、向量维数随着词典大小线性增长
解决办法&#xff1a;SVD、PCA降维&#xff0c;但是计算量大
例如

NNLM是从语言模型出发(即计算概率角度)&#xff0c;构建神经网络针对目标函数对模型进行最优化&#xff0c;训练的起点是使用神经网络去搭建语言模型实现词的预测任务&#xff0c;并且在优化过程后模型的副产品就是词向量。&#xff08;引自&#xff1a;https://blog.csdn.net/maqunfi/article/details/84455434&#xff09;
使用非对称的前向窗函数&#xff0c;窗长度为n-1滑动窗囗遍历整个语料库求和&#xff0c;计算量正比于语料库大小
整个网络由输入层、投射层、隐含层、输出层构成
输入&#xff1a;&#xff08;N-1&#xff09;个前向词&#xff0c;one-hot方式表示&#xff0c;只有对应的位置为1
输入层是&#xff08;N-1&#xff09;*M维向量
计算量仍然比较大

一个文本&#xff0c;由N个词语组成&#xff0c;现在呢&#xff1a;想根据 前N个词语 来预测 第N个词语 是啥&#xff1f;

首先了解什么是什么是Word2Vec
这里参考word2vec概述
这篇文章是这样解释的&#xff1a;
Word2Vec&#xff0c;顾名思义&#xff0c;就是把一个 word 变成一个 vector。其实&#xff0c;早在 Word2Vec出来之前&#xff0c;就已经有很多人思考这个问题了。而用的最多的方法大概是 TF-IDF 这类基于频率的方法。不过这类方法有什么问题呢&#xff1f;一个很明显的缺陷是&#xff0c;这些方法得到的向量是没有语义的&#xff0c;比如说&#xff0c;对于「苹果」、「香蕉」、「可乐」这三个词来说&#xff0c;「苹果」和「香蕉」表示的向量应该比「可乐」更加相似&#xff0c;这种相似有很多衡量方法&#xff08;比如「欧式距离」或「余弦相似性」&#xff09;&#xff0c;但用频率的方法是很难体现这种相似性的。而Word2Vec 就是为了解决这种问题诞生的。
因此&#xff0c;对于Word2Vec其实是语言模型中的一种&#xff0c;它是从大量文本预料中以无监督方式学习语义知识的模型&#xff0c;被广泛地应用于自然语言处理中。&#xff08;深入浅出Word2Vec原理解析&#xff09;
其基本思想
Word2Vec 主要就是利用上下文信息&#xff0c;或者更具体一点&#xff0c;与一个词前后相邻的若干个词&#xff0c;来提取出这个词的特征向量。
改为用上下文的词汇来同时预测中间词&#xff0c;滑动时使用双向上下文窗口

输入层&#xff1a;仍然直接使用词袋BOW方式表示
投射层&#xff1a;
对向量直接求和&#xff08;平均&#xff09;&#xff0c;以降低向量维度
实质上是去掉了投射层
隐含层&#xff1a;直接去除
本质上只是一个线性分类器
短语料不适合用word2vec来分析&#xff08;比如购物评论、微博这种&#xff0c;需要大语料才能有较好的作用&#xff09;


为了利用这种上下文信息&#xff0c;Word2Vec 采用了两种具体的实现方法&#xff0c;分别是 CBOW 和Skip-grams。这两种方法本质上是一样的&#xff0c;**都是利用句子中相邻的词&#xff0c;训练一个神经网络。**它们各有优劣&#xff0c;因此各自实现的 Word2Vec> 的效果也各有千秋。
引自&#xff1a;word2vec概述

其网络的基本结构大概是这个样子



结果向量太大&#xff0c;数十万维度&#xff1a;在几十万个词条中预测哪一个会出现&#xff0c;所以考虑使用Huffman Tree来编码输出层的词典。哈夫曼树&#xff0c;又称最优二叉树&#xff0c;是一类带权路径长度最短的树&#xff0c;将结果输出转化为树形结构&#xff0c;改用分层softmax&#xff0c;在每一个分叉时&#xff0c;将问题转换为二分类预测&#xff0c;每次预测都会有概率结果提供&#xff0c;将概率连乘&#xff0c;就构成了似然函数
Word2Vec原理之层次Softmax算法
图片来自&#xff1a;https://blog.csdn.net/qq_36775458/article/details/100672324
下图是以词w为”足球“为例&#xff1a;

输出层变成一颗树形二叉树&#xff0c;其实&#xff0c;输出层有V-1个节点
图片来自&#xff1a;机器学习详解系列&#xff08;二十五&#xff09;&#xff1a;Word2Vec


一个正样本&#xff0c;V-1个负样本&#xff0c;显然负样本比例太高&#xff0c;考虑对负样本做抽样&#xff0c;基于词出现的频率进行加权采样&#xff0c;一般取词频的0.75次方用于加权&#xff0c;以便够让低频词多一些出场机会
Word2Vec仍然存在的问题
只是利用了每个局部上下文窗囗信息进行训练&#xff0c;没有利用包含在全局矩阵中的统计信息
·GloVe&#xff08;Global Vectors for Word Representation&#xff09;&#xff0c;用全局信息去编码词向量&#xff0c;但是应用还不多
对多义词无法很好的表示和处理&#xff0c;因为使用了唯一的词向量
至此







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有