摘要 文本生成图像作为近几年的热门研究领域,其解决的问题是从一句描述性文本生成与之对应的图片。近一周来,我通过阅读了近几年发表于顶会的近10篇论文,做出本文中对该方向的
摘要 文本生成图像作为近几年的热门研究领域,其解决的问题是从一句描述性文本生成与之对应的图片。近一周来,我通过阅读了近几年发表于顶会的近10篇论文,做出本文中对该方向的简要报告。报告中主要阐述了近几年最流行的解决方案——以GAN思想为主干的解决方案。首先我对现有方法进行了简单回顾,之后针对这些方法做出了自己的总结,将各方法中用来提升生成效果的方式归纳为“增加网络深度”、更加充分地利用文本信息及通过增加额外约束三种。继而又提出当前方法存在的不足以及自己对今后如何改进的简单思考。
1.简介 从文本生成图像是近几年的热门研究领域,其主要任务是从一句描述性文本生成一张与文本内容相对应的图片。主流方法有VAE(Variational Auto-Encoder),DRAW(Deep Recurrent Attention Writer)以及GAN等,其中GAN在近几年的研究中成为了最热门的方法,在大部分顶会论文中都用到了GAN的思想来完成图像的生成工作。无论使用何种GAN,都先对自然语言文本进行处理得到文本特征,进而以该文本特征来作为后续图片生成过程的约束。在GAN中生成器Generator根据文本特征生成图片,继而被鉴别器Discriminator鉴定其生成效果,根据鉴别器的鉴定结果生成器再次生成更真实的图片,鉴别器则再次对新图鉴定,以此类推,迭代进行直到网络收敛。
2.现有方法回顾 在2016年以前,VAE和DRAW方法都被用来完成图像生成工作,VAE以一种统计方法进行建模最大化数据的最小可能性来生成图像,而DRAW方法使用了循环神经网络,并利用注意力机制,每一步关注一个生成对象,依次生成一个patch并叠加出最终结果。其中Mansimov, Elman, et al [3] 提出的AlignDRAW在传统DRAW的基础上加入了文本对齐,从而完成了文本到图像的任务。如图1,该模型使用一个双向循环神经网络(BiRNN)作为文本编码器(图1左),将文本信息从正反两个方向编码为一个文本向量特征(text embedding)用于后面DRAW部分的文本对齐,DRAW部分又有两部分构成,Inference和Generative,Inference部分从输入图片和文本特征中逐步生成隐藏信息给Generator,Generator又从隐藏信息和对齐文本特征中每次一个patch地逐步生成图片。
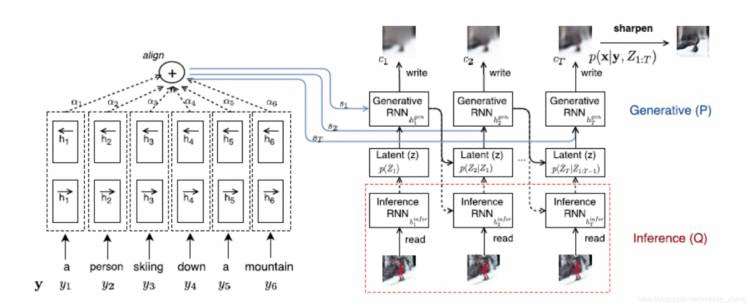
图1. AlignDRAW整体结构图
自Reed et al [1] 2016年提出GAN-INT-CLS以来,大部分的方法都使用了GAN的思想完成从文本到图像的任务。
GAN-INT-CLS网络以GAN为模型主干(如图2),同时在输入中增加文本特征来作为生成器和鉴别器的约束,最终生成64×64的图像。在生成器中,text embedding跟随机噪声融合后一起输入到生成网络中;在鉴别器中,生成图像在下采样之后,跟之前的text embedding在空间复制之后融合,最后鉴别器根据融合特征进行判定。其中GAN-CLS主要加入了Matching-aware discriminator,即在鉴别器中对错误情况进行分类(pair loss),一种是生成的fake图像匹配了正确的文本,另一种是真实图像但匹配了错误文本,利用这种机制使得鉴别器网络不仅能够识别图像是否是生成器生成的(image loss),并且能够鉴别生成图像跟给定文本的匹配关系,从而保证生成图像符合文本描述。GAN-INT主要解决了文本信息的稀疏问题,在给出的文本特征中插值以获得生成图像的多样性。
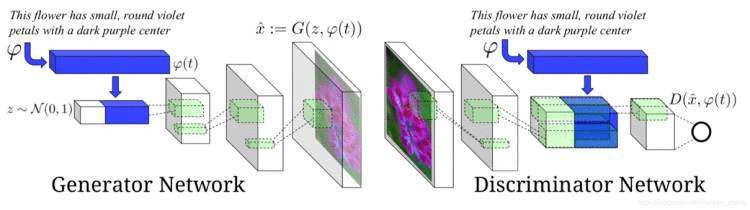
图2. GAN-INT-CLS总体网络结构
继GAN-INT-CLS之后,Reed et al 又在后续工作中给出了Generative Adversarial What-Where Network(GAWWN)[2],该文通过在网络中增加bounding box 和keypoint限定,从而使生成图像精度提高,得到了128×128的图像。
StackGAN[4]在此基础上更进一步,使用了两个GAN来分步生成图像。因为单纯在网络中增加up sampling并不能提升生成图片的质量,所以Zhang et al 提出了这样一个分两阶段的GAN网络,第一阶段用于生成低精度(64×64)的图像,该阶段主要关注图像的背景,颜色及轮廓等基本信息;在第二阶段中将第一阶段的输出作为输入同时再次使用text embedding,从而获得了第一阶段丢失的细节信息,进而生成了256×256的更精细图片。同时在该方法中还加入了CA(Conditioning Augmentation)模块来对文本特征加入一些实用的随机噪声,从而使得生成图像具有更多的可变性。在其后续工作中提出的StackGAN++[5] 更进一步,将GAN扩充成一个树状的结构,采用了多个生成器和多个鉴别器并行训练,得到不同精度的图像(64×64,128×128,256×256),低精度生成器输出的隐层信息一方面用来生成低精度图,另一方面作为更高精度生成器的输入。在训练过程中各个生成器和鉴别器共享同一个text embedding 保证了逐步提取更加精细的文本信息。同时该方法不仅可以完成限定性的生成任务(conditional generative tasks),同时也扩展到了非限定性生成任务(unconditional generative tasks)。
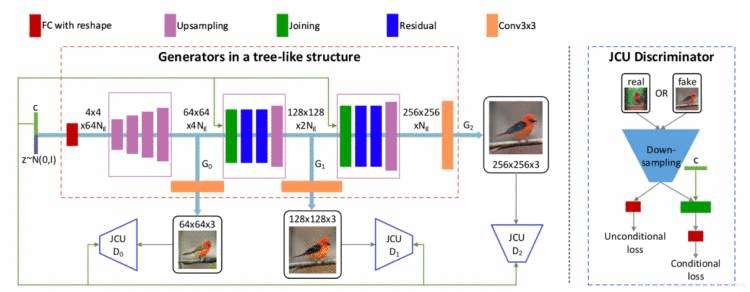
图3. StackGAN++总体框架
之后,Xu et al又在StackGAN++基础上提出AttnGAN [6],相比StackGAN++该方法增加了注意力机制,不仅提取文本的sentence feature 作为全局约束,同时也将attention精确到word级别提取了word embedding作为局部约束送入网络,生成器与鉴别器每次针对word embedding部分精准优化,从而使得生成图像更能突出文本中的细节。此外,该文中还提出了一种DAMSM (Deep Attentional Multimodal Similarity Model)机制,该机制改进了训练过程中计算loss 的方式,不仅考虑鉴别器的source loss(即普通GAN的loss),同时更加关注训练过程中对word embedding的生成效果,在生成高精度图像后提取该图片的局部特征(local image features)跟word embedding进行对照进而获得DAMSM loss使得模型训练更加关注文本细节的生成情况,从而使得生成效果得到了提升。
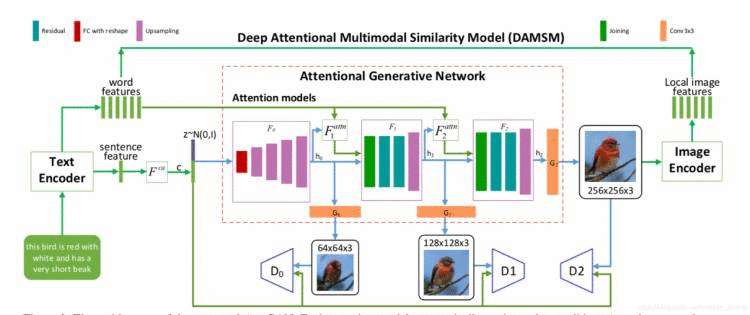
图4. AttnGAN总体框架
Dash et al [7] 提出的TAC-GAN借鉴了AC-GAN的思想,不仅考虑了文本约束,同时增加了class label作为约束,在鉴别器中鉴别结果不止有原来的鉴定生成图片或真实图片,同时也鉴定其类别信息,通过增加类别约束提升了生成效果。
Johnson et al [8]则不在text embedding的维度进行约束,而是更深入到文本语义,提出了通过scene graph来建模文本中各对象及其关系,在获得scene graph的基础上对语义中的每个对象得到其bounding box和mask进而得到一个关于文本语义的scene layout,然后以此scene layout作为输入加入到后续的GAN网络中生成图片。该方法改善了之前各种方法难以生成复杂场景的问题,使得生成图像更能反映文本语义。
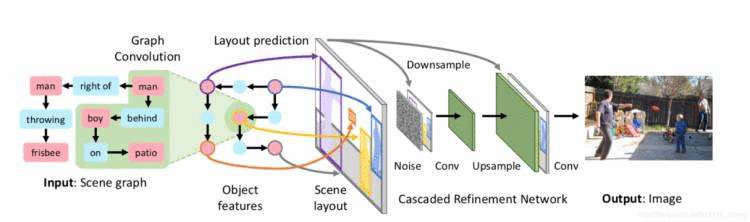
图5. 利用scene graph生成图像的总体框架
Hong, Seunghoon, et al [9]提出了HDGAN借鉴StackGAN系列的思想,但是只使用了一个统一的生成器(single-stream Generator)同时带有多个级联鉴别器的网络模型,实现了端到端方式的图像生成,并且无需class label等额外的约束信息。Hong, Seunghoon, et al [10] 提出的”Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis.” 中将文本生成图像过程分为两步,首先从文本到语义框架(text to semantic layout)然后再生成图像,在从文本到语义框架过程中,又分为两步,先从文本中通过LSTM网络获得各个对象实例的bounding box然后利用BiLSTM在每个实例对象的bounding box中预测对象实例的语义mask然后将bounding box和mask结合成为semantic layout作为后续GAN的输入。
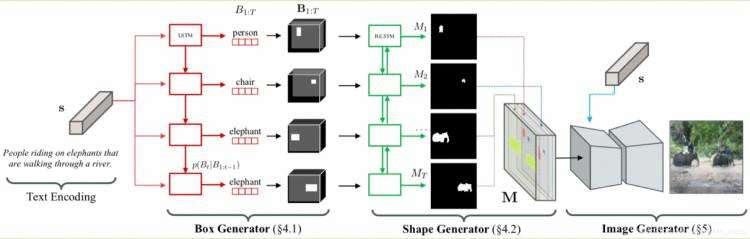
图6. “Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis.”中semantic layout的生成过程
3.现有方法总结 对比自2016年到2018年顶会中各主流文本到图像生成的方法可以看出,GAN的思想几乎被所有方法用到,表明GAN在图像的生成中的确有着明显的优势。再深入到各个方法分析,我个人将各种方法对生成质量优化的方式分为三种:第一通过“增加网络深度”;第二通过更加充分地利用文本信息;第三通过增加额外约束。
对于“增加网路深度”,从最初的GAN-INT-CLS[1]和GAWWN[2]仅使用一个GAN,到StackGAN系列([4,5,6])及HDGAN[9]用到两个甚至多个GAN进行训练,如果我们把焦点放在网络整体过程上,可以说从一个GAN到多个GAN的过程正是将网络加深的过程,从低精度到高精度这样一个金字塔结构,文本特征和图像特征在网络中走过了更多的“层”,这种方式使得网络能够提取更多文本信息,避免单个GAN遗失信息的问题,从而可以得到更好的生成效果。
而针对更充分的利用文本信息,在早期的各个方法中([1],[2],[4])更多的只是将注意力放在对生成图像部分的网络进行调整,而对于文本的关注则只是关注其总体特征,利用已有的文本处理模型将文本处理成text embedding(sentence embedding),可以说其粒度还是相对较粗的,能够关注到的细节不够多。而在AlignDRAW[3]及后续工作([5],[6])中则进一步将文本信息挖掘到更细粒度的word级别,通过更细粒度的约束来提升生成效果;最后,在最近使用的scene graph[8]及semantic layout[10]中则更进一步,不仅考虑细粒度的文本特征,同时还对文本语义进行更深入的挖掘,做到了对文本中实例及其关系的建模,从而将这些语义信息反映到一个layout中间层上,使得模型能够处理更加复杂的场景。
对于通过增加额外约束的方式,几乎所有方法中都有涉及。其中最为明显的是各个方法都使用了额外的loss来优化,例如在GAN-INT-CLS[1]和GAWWN[2]中提到的两种loss(image loss, pair loss)被大多数后来的方法所借鉴;在StackGAN系列中生成器的训练中加入了KL正则项(DKL(N (μ(‘t), ⌃(‘t)) || N (0, I)));而在TAC-GAN[7]中则是加入了class loss;在Image Generation from Scene Graphs [8]中则更是综合考虑了六种loss(Box loss, Mask loss, Pixel loss, Image adversarial loss, Object adversarial loss, Auxiliarly classifier loss)。
(转载,引用请注明出处,谢谢)
reference:
[1] Reed, Scott E., et al. “Generative adversarial text to image synthesis.” International Conference on Machine Learning(2016): 1060-1069.
[2] Reed, Scott E., et al. “Learning What and Where to Draw.” Neural Information Processing Systems(2016): 217-225.
[3] Mansimov, Elman, et al. “Generating Images from Captions with Attention.” International Conference on Learning Representations(2016).
[4] Zhang, Han, Tao Xu, and Hongsheng Li. “StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks.” International Conference on Computer Vision(2017): 5908-5916.
[5] Zhang, Han, et al. “StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks.” IEEE Transactions on Pattern Analysis and Machine Intelligence(2018): 1-1.
[6] Xu, Tao, et al. “AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks.” Computer Vision and Pattern Recognition(2018): 1316-1324.
[7] Dash, Ayushman, et al. “TAC-GAN – Text Conditioned Auxiliary Classifier Generative Adversarial Network..” arXiv: Computer Vision and Pattern Recognition(2017).
[8] Johnson, Justin, Agrim Gupta, and Li Feifei. “Image Generation from Scene Graphs.” Computer Vision and Pattern Recognition(2018): 1219-1228.
[9] Zhang, Zizhao, Yuanpu Xie, and Lin Yang. “Photographic Text-to-Image Synthesis with a Hierarchically-Nested Adversarial Network.” Computer Vision and Pattern Recognition(2018): 6199-6208.
[10] Hong, Seunghoon, et al. “Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis.” Computer Vision and Pattern Recognition(2018): 7986-7994.








 京公网安备 11010802041100号
京公网安备 11010802041100号