本文转载自【微医大数据团队】
微医是中国移动互联网医疗健康服务平台,由廖杰远及其团队于2010年创建。 通过互联网和人工智能技术,帮助医院、医生、药企、险企等产业链主体实现云化与智能化,为用户提供预约挂号、在线咨询、远程会诊、电子处方、慢病管理、健康消费、全科专科诊疗等线上线下结合的健康医疗服务;截至2017年11月,微医已经与全国30个省份、2400多家医院的信息系统实现连接。平台上线医生数超过26万名,拥有超过1.5亿注册用户,累计服务人次超过7.9亿。(介绍来自百度百科)
一、背景
随着企业的数据量越来越大,数据分析查询响应及时性要求越来越高,如按照传统ETL加工方式,需要考虑各个粒度上的聚合,来提高响应及时性,那么ETL的工作量非常大,对模型设计要求也比较高,也不适合灵活的维度组合查询的需求。在这种背景下,OLAP分析引擎孕育而生。
(注:数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。)
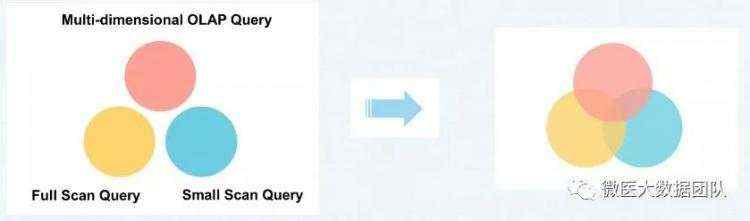
经我们调研分析发现,大数据查询大致可分为如下三类:
全量数据进行扫描的聚合操作
进行OLAP的聚合操作(占比最多)
随机查询操作
而OLAP分析引擎是一种高性能的查询分析引擎,可以同时有效地支持以上三类需求,如下图所示:
二、OLAP方案对比
我们调研了市面上主流的OLAP分析引擎,结论如下:
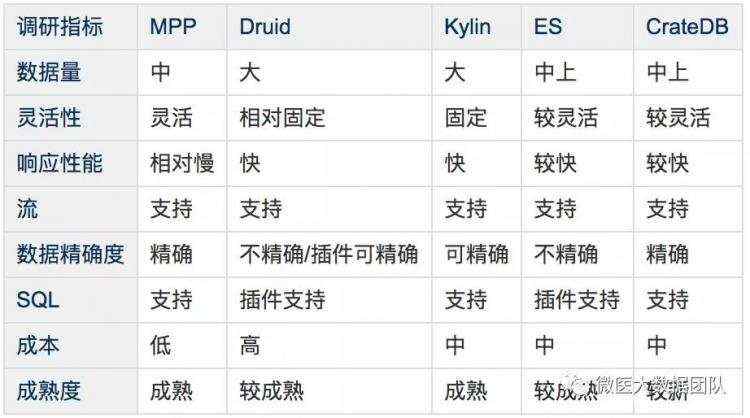
MPP在性能方面表现欠佳且不够稳定,非常销耗服务器硬件资源
Druid涉及到组件比较多,偏重,对精确去重统计支持、SQL支持相对较弱,特别是表关联支持较差
ES 对精确去重统计不支持,SQL支持较弱,不支持表关联操作
CrateDB是基于es封装的SQL数据库,虽然支持精确去重统计,但是相对比较新,参考资料也有限,使用风险较大
而Kylin相对成熟,后续版本支持精确去重统计,数据是预计算,性能表现较稳定,支持数据量大,因此Kylin是我们重点调研产品。
三、KYLIN调研
1.KYLIN介绍
Kylin的核心思想是预计算,利用空间换时间来加速查询模式固定的OLAP分析。
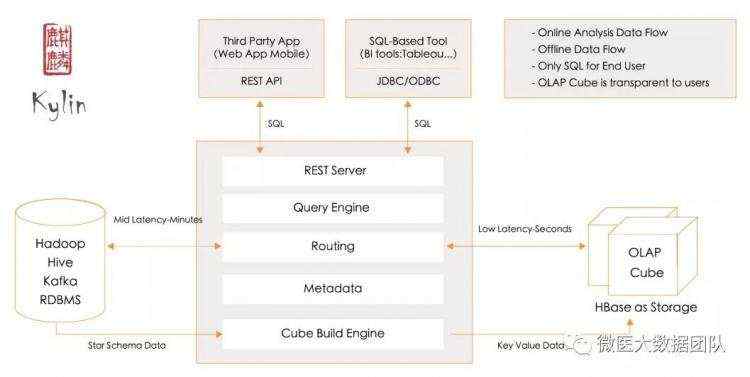
下图显示了它的主要组件:
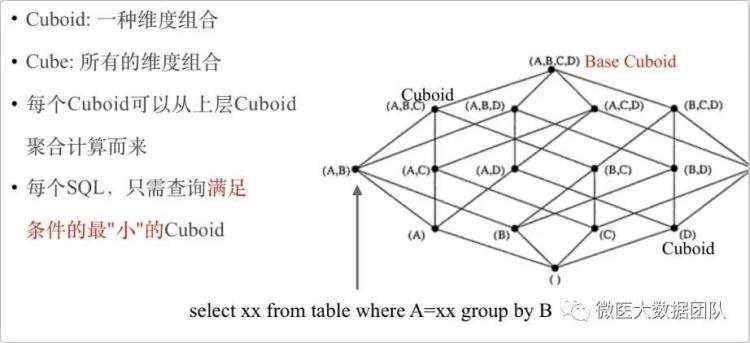
Kylin的理论基础是Cube理论,每一种维度组合称之为Cuboid,所有Cuboid的集合是Cube。其中由所有维度组成的Cuboid称为Base Cuboid,下图中(A,B,C,D)即为Base Cuboid,所有的Cuboid都可以基于Base Cuboid计算出来。在查询时,Kylin会自动选择满足条件的最“小”Cuboid,比如下面的SQL就会对应Cuboid(A,B):
下图是Kylin数据流转的示意图,Kylin自身的组件只有两个:JobServer和QueryServer。
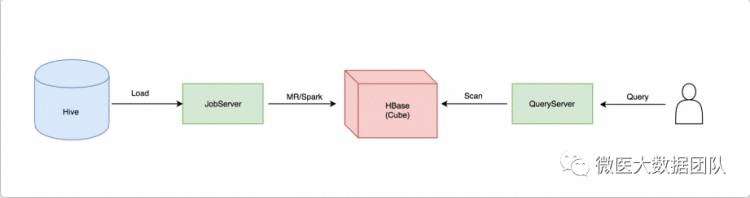
JobServer主要负责将数据源(Hive,Kafka)的数据通过计算引擎(MapReduce,Spark)生成Cube存储到存储引擎(HBase)中;
QueryServer主要负责SQL的解析,逻辑计划的生成和优化,向HBase的多个Region发起请求,并对多个Region的结果进行汇总,生成最终的结果集返回给用户。
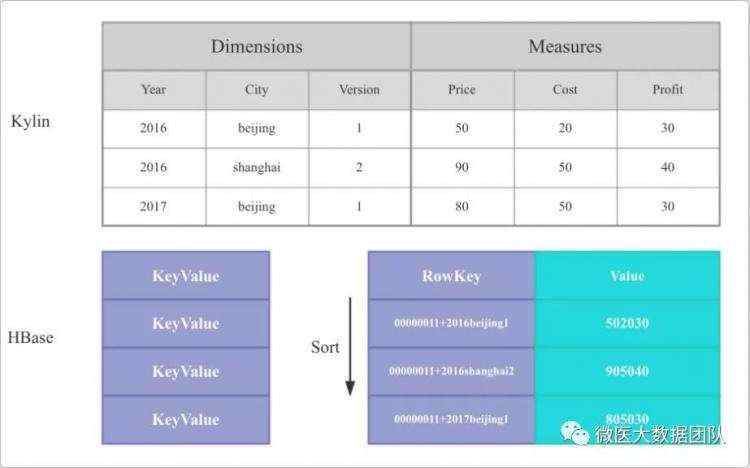
Kylin将表中的列分为维度列和指标列,在数据导入和查询时,相同维度列中的指标会按照对应的聚合函数(Sum, Count, Min, Max, 精确去重,近似去重,百分位数,TOPN)进行聚合。
当存储到HBase时,Cuboid+维度(Cuboid-标识字段;维度-标识具体维度值,通过解析SQL来定位命中哪个Cuboid) 作为HBase的Rowkey, 指标作为HBase的Value。一般会把所有相关指标对应到HBase的一个列簇,每列对应一个指标,但对于较大的去重指标会单独拆分到第2个列簇。
下图显示Kylin中的维度和指标在HBase表中的对应关系:
下图是Kylin Cube和HBase Table的对应关系:
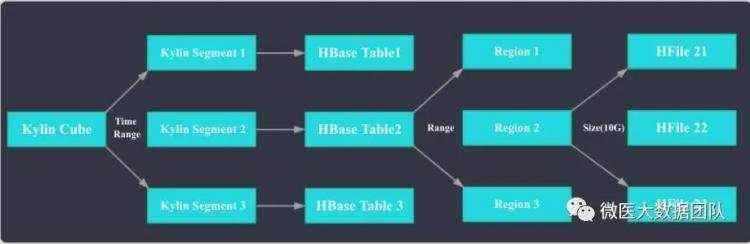
如上图所示,在Kylin中1个Cube可以按照时间拆分为多个Segment,Segment是Kylin中数据导入和刷新的最小单位。Kylin中1个Segment对应HBase中一张Table。 HBase中的Table会按照Range分区拆分为多个Region,每个Region会按照大小拆分为多个HFile。
2.维度优化
通过上面介绍我们了解到Kylin的主要思想是用空间换时间,一个Cube是所有维度的组合,如果有N个维度,就有2的N次方的组合,这个数据膨胀速度非常可怕(指数级增长)。但是我们实际常用的查询往往就那么几种维度,很多维度组合的预计算是没有必要的,因此Kylin在实际使用过程中的维度优化是非常有必要的。
目前Kylin可以使用的维度优化手段有以下几种:
聚集组(通过减少维度来减少维度组合)
用来控制哪些cuboid需要计算,没有查询必要的维度可以去除
衍生维度(只拿维度中最细的粒度来减少维度组合)
维表中可以由主键推导出值的列可以作为衍⽣维度。比如医生id推导出医生职称,姓名等;宽表模型需要转换成按标准星型模型设计,id对应的信息放维度表;维度表的N个维度组合成的cuboid个数会从2的N次方降为2
强制维度(固定维度来减少维度组合)
所有cuboid必须包含的维度,不会计算不包含强制维度的cuboid,比如日期维度;
层次维度(只拿维度中最细的粒度来减少维度组合)
具有一定层次关系的维度,像年,月,日;国家,省份,城市这类具有层次关系的维度。
联合维度 (通过合并维度来降低维度组合)
将几个维度视为一个维度。
a 可以将确定在查询时一定会同时使用的几个维度设为一个联合维度。
b 可以将基数很小的几个维度设为一个联合维度。
c 可以将查询时很少使用的几个维度设为一个联合维度。
Extended Column:特殊查询场景下优化
在OLAP分析场景中,经常存在对某个id进行过滤,但查询结果要展示为name的情况,比如user_id和user_name。这类问题通常有三种解决方式:
a. 将ID和Name都设置为维度,查询语句类似select name, count(*) from table where id = 1 group by id,name。这种方式的问题是会导致维度增多,导致预计算结果膨胀;
b. 将id和name都设置为维度,并且将两者设置为联合。这种方式的好处是保持维度组合数不会增加,但限制了维度的其它优化,比如ID不能再被设置为强制维度或者层次维度;
c. 将ID设置为维度,Name设置为特殊的Measure,类型为Extended Column。这种方式既能保证过滤id且查询name的需求,同时也不影响id维度的进一步优化。
所以此类需求我们推荐使用 Extended Column。
四、结论
如果有了OLAP分析引擎,我们就可以利用它来优化大数据平台架构,提供统一的查询服务入口。如下图所示:
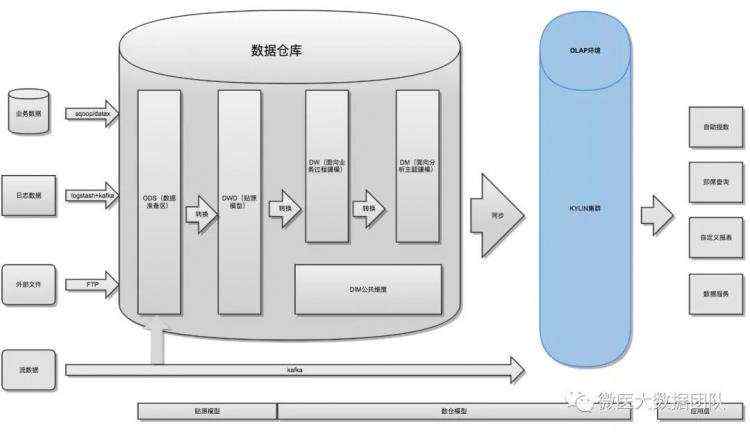
结合数仓建模,中间聚合过程可以依靠OLAP引擎完成,简化ETL流程。
对于不同的业务需求,可以在同一个模型上建立不同的cube,cube面向业务需求。
维度优化对cube构建性能、以及查询性能很关键,对建模人员提出一定要求;可以规范化建模原则。
比较适合聚合查询,随机查询有点勉强,但是也支持。
支持流处理,但是支持的格式固定,规范,脏数据处理能力不强,以及构建时间较长,很难满足准实时需求。
支持的数据源有限,但是可以通过其他方式解决。
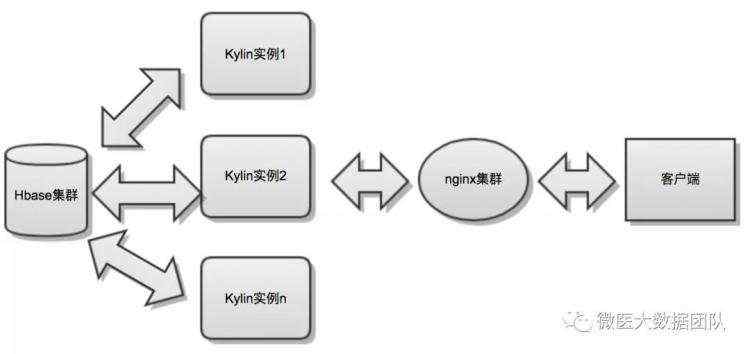
生产环境推荐部署方式
如下图所示,Kylin实例集群部署,实现负载均衡;hbase从hadoop集群隔离,单独部署一个小集群,提高稳定性:
数仓建模的思考
指标等数据统计,可以基于KYLIN统计数据输出,如下图所示:
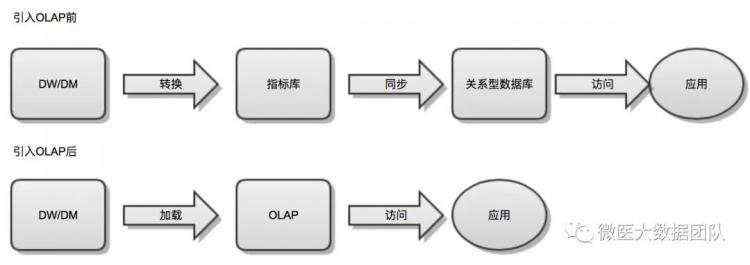
从上面数据流程上很明显看出,整体开发流程简化了,提高开发效率;
参考:
http://kylin.apache.org/docs
https://blog.bcmeng.com/post/apache-kylin-vs-baidu-palo.html
https://blog.bcmeng.com/post/kylin-dimension.html#extended-column
"Apache and Apache Kylin are either registered trademarks or trademarks of The Apache Software Foundation in the US and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks."





 京公网安备 11010802041100号
京公网安备 11010802041100号