作者:北若久 | 来源:互联网 | 2023-02-05 21:58
为什么说MongoDB和HBase不适用于汽车行业的时序数据处理?-近年来,在能源和环保的压力下,新能源汽车成为了未来汽车发展的新方向。为支持其快速发展,我国出台了一系列扶持政策,
近年来,在能源和环保的压力下,新能源汽车成为了未来汽车发展的新方向。为支持其快速发展,我国出台了一系列扶持政策,在《新能源汽车产业发展规划(2021-2035年)》中就有提出,到 2025 年新能源汽车新车销售量要达到汽车新车销售总量的 20% 左右,其市场广阔程度可见一斑。现在火热的自动驾驶技术,也是新能源汽车的一大优势,而自动驾驶又需要各类传感器产生的源源不断的时序数据来辅助判断,所以与时序数据相关的采集、处理和存储等各项需求也显著增长。
一直以来,对于新能源车企来说,在时序数据的存储上,选择的大多都是 MongoDB 或 Apache HBase,这两大数据库技术相对更加成熟,在业务规模尚未扩张之前,因为设备不多、数据量不大,加上查询场景单一,尚且可以满足业务需求。随着业务的加速扩张,写入速度太慢、支撑成本过高等问题也逐渐显现。
以零跑汽车为例,此前他们将时序数据分别存储在 MongoDB 和 HBase 中,前者会将数据全部存储在内存中,过高的存储成本导致只能存储一段时间内的数据,且存储的数据格式需要经过业务组织处理,不仅业务变更不灵活,可以做的业务也非常有限。后者用来存储部分实时信号,需要整套 HDFS 做支撑,使用、运维和人力等成本都很高,需要大数据相关的人才才能保证平稳运行。而且公司的 HBase 环境是私有云环境,而云平台在公有云环境,跨专网业务时常会被网络问题影响。
在合适的时候选择合适的数据库是支持业务发展的关键,但数据库的更换也并不是头脑一热就能拍板决定的,还需要进行数据库产品的缜密观察和调研,才能选中真正适合自身业务发展的“天选数据库”。那对于车企来说,到底什么样的数据库更加适合呢?我们不妨从它所产生的数据本身去做一下分析。
从时序数据本身的特点看车企适用的数据库类型
当下车联网已经成为车企布局未来的一个重要场景,如工业互联网一样其产生的数据分类为时序数据,而时序数据具有如下特点:
- 所有采集的数据都是时序的
- 数据都是结构化的
- 一个采集点的数据源是唯一的
- 数据很少有更新或删除操作
- 数据一般是按到期日期来删除的
- 数据以写操作为主,读操作为辅
- 数据流量平稳,可以较为准确的计算
- 数据都有统计、聚合等实时计算操作
- 数据一定是指定时间段和指定区域查找的
而关系型数据库主要对应的数据特点却与之差别甚广:数据写入上大多数操作都是 DML 操作,插入、更新、删除等;数据读取逻辑一般都比较复杂;在数据存储上,很少有压缩需求,一般也不设置数据生命周期管理。很显然,关系型数据库是不适合用于处理时序数据的。
企业在选择数据库文件系统等产品时,最终目的都是为了以最佳性价比来满足数据写入、数据读取和数据存储这三个核心需求。而时序数据库(Time-Series Database)正是从以上特点出发、以时序数据的三个核心需求为最终结果进行设计和研发的,因此在数据处理上会更加具有针对性。
近年来,随着物联网的快速发展、业务规模和数据量的快速爆发,国内外越来越多的科技企业发现了用传统关系型数据库来存储时序数据的问题,针对时序数据库的选型调研也由此开始。
目前市面上的时序数据库种类繁多,老将如 InfluxDB、Prometheus,后起之秀如 OpenTSDB、TDengine 等,在对自身业务进行时序数据库选型时,除了性能各方面的考量外,大部分企业还会考量其是否具备水平扩展能力。
在性能层面,TDengine 曾做过几家时序数据库的对比——TDengine 与 InfluxDB、OpenTSDB、Cassandra、MySQL、ClickHouse 等数据库的对比测试报告,聚焦工业互联网的和利时也从使用者的角度做过一些对比——从四种时序数据库选型中脱颖而出,TDengine 在工控领域边缘侧的应用,大家可做参考。而在水平扩展能力方面, TDengine 早在 2020 年就实现了单机和集群版的双开源,同时凭借着性能上的硬核表现,深受着车联网、物联网、工业互联网等企业客户的青睐。
下面我们以 TDengine Database 为例,看看时序数据库针对车联网场景下庞大的时序数据的写入、查询、存储是如何实现的。
基于TDengine,你可以怎么设计架构和表
作为时序数据库引擎,TDengine Database 不需要基于 Hadoop 生态搭建,也不需要拼装 Kafka、Redis、HBase 等诸多组件,它将数据处理中的缓存、消息队列、数据库、流式计算等功能都统一在了一起,这样轻量级的设计不仅让它的安装包很小、对集群资源消耗很少,同时也在一定程度上降低了研发、运维成本,因为需要集成的开源组件少,因而系统可以更加健壮,也更容易保证数据的一致性。可以试验一下,如果你要搭建一套车队管理系统,你只需要写一个 Java 应用,再加上 TDengine 完全能够实现。
从时序数据的特点出发,TDengine 没有选择流行的 KV 存储,而是使用了结构化存储。同时,基于物联网场景里,每个数据采集点的数据源是唯一的、数据是时序的,且用户关心的往往是一个时间段的数据而非某个特殊时间点等特点出发,TDengine Database 要求对每个采集设备单独建表。也就是如果有 1000 万个设备,就需要建 1000 万张表。
这就是 TDengine Database 的核心创新点之一——“一个设备一张表”,以此保证每个采集点的数据在存储介质上以块为单位进行连续存储,减少随机读的同时成数量级提升查询速度,还可以通过无锁、追加的方式写入,提升写入速度。

篇幅有限,关于 TDengine 的更多设计特点,大家如果有兴趣可以移步官网查阅了解更多,在这里就不多做赘述了。
下面我们来看一下两种数据库下的架构图,从中我们也可以得出一个结论,选择 TDengine Database 明显会更加轻量。
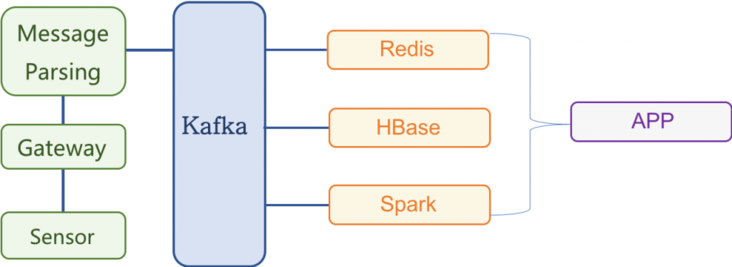
- 基于 TDengine 的解决方案,架构图如下——
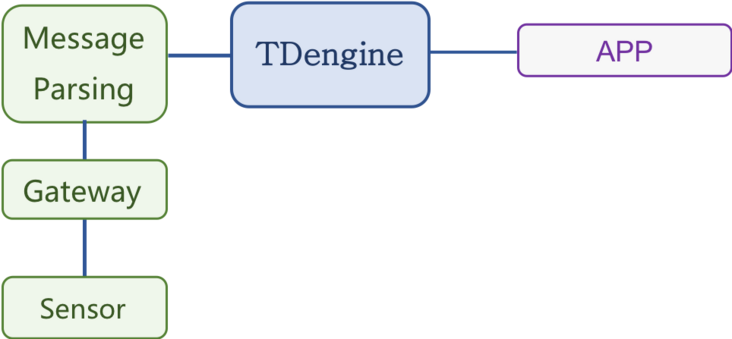
在表数据的搭建上,通常车企在采集数据时包含的通常都是“采集时间(时间戳)、车辆标志(字符串)、经度(双精度浮点)、维度(双精度浮点)、海拔(浮点)、方向(浮点)、速度(浮点)、车牌号(字符串)、车辆型号(字符串)、车辆vid(字符串)”这 10 类字段。
不同于其他时序数据库,TDengine 会为每辆车单独创建一张数据表,数据字段为采集时间、车辆标志、经度、纬度、海拔、方向、速度等与时间序列相关的采集数据;标签字段为车牌号、车辆型号等车辆本身固定的描述信息。这里面有一个小技巧,浮点数据压缩比相对整型数据压缩比很差,经度纬度通常精确到小数点后 7 位,因此我们可以将经度纬度增大 1E7 倍转为长整型存储,将海拔、方向、速度增大 1E2 倍转为整型存储。
超级表创建语句:create table vehicle(ts timestamp, longitude bigint, latitude bigint, altitude int, direction int, velocity int) tags(card int, model binary(10));
此前有研发人员使用 C 语言编写了一个车辆模拟数据生成程序,对 TDengine 进行测试,以 10 万张数据表,每张写入 1 个月的数据(数据间隔 1 分钟,计 44000 条数据)为测试数据。编译之后,将测试程序和数据库在同一台 2 核 8G 的台式机上运行,写入时间共计为 3946 秒,相当于 4400000000条/3946 秒=111.5 万条/秒,折算成点数为 111.5*5=557 万点/秒。
在这里要注意的是,该程序是单线程运行的,如将其修改成多线程,速度还会有更大提升,但是仅就目前的性能来看,对于车联网的场景也已经足够。
从蔚来、零跑、理想三家车企,看时序数据库的应用效果
聚焦在实际业务中,时序数据库之于车联网的匹配度之高,我们从 TDengine 的三个车企客户案例中也可见一斑。
对于蔚来汽车来说,随着业务的发展,截止 2021 年底其已经在全国各地布局了换电站 777 座,超充桩 3404 根,目充桩 3461 根,为用户安装家充桩 96,000+ 根。为了对设备进行更高效的管理,他们需要将设备采集数据上报至云端进行存储,并提供实时数据查询、历史数据查询等业务服务,实现设备监控和分析。
但一直作为蔚来汽车数据存储的 MySQL + HBase 模型却越来越难以为继,随着换电站和超充站等设备在全国的快速布局,设备数量持续增长,积累的数据量越来越多,长时间跨度数据查询效率出现瓶颈,再加上查询场景不断丰富,HBase 已经无法满足当前业务需要。他们决定从 OpenTSDB 和 TDengine 中进行选择,在进行各种对比测试后决定将 HBase 替换为 TDengine。
从最终的改造结果上来看可以说是非常成功了。在查询速度上,从使用 HBase 查询单设备 24 小时数据的秒级返回升级到使用 TDengine 查询相同数据的毫秒级返回;在存储空间上,每天增量数据占用的存储空间相当于原来使用 HBase 时的 50%;在成本对比上,迁移后集群计算资源成本相比使用 HBase 节省超过 60%。
无独有偶,零跑汽车面临着和蔚来汽车一样的困境,他们此前在数据存储上的选择是 MongoDB 和 HBase,随着业务规模的扩大,数据库性能越来越难以满足数据处理需求,成本也随之提升。从降本增效的角度考虑,零跑决定在 C11 新车型上试用 TDengine。
零跑科技在做数据库选型调研时只有两点诉求:性能强、成本低。而最终的事实证明,TDengine 确实没有辜负他们的期待。在查询上,TDengine 的列式存储可以直接以 SQL 计算,不用再像 MongoDB 一样,在查询前还需要根据业务加工出需求数据。同时 TDengine 的高压缩算法也助力零跑科技提升 10-20 倍的压缩性能,既节省了存储空间也解决了存储成本高的问题。
和前两面两家公司不同,理想汽车是从 TiDB 迁移到 TDengine 的。整体来看,TiDB 更适合 TP 或者轻 AP 场景。从理想汽车的角度而言,其写入性价比较低,一次性大批量写入场景也不太适合,且对业务有入侵性,底层库表要按照月份来建表,还要针对每个采集点打上标签。
在迁移到 TDengine 之后,理想汽车的机器使用成本显著降低,聚合类查询速度显著提成,引入了 firstEP 机制的弹性扩缩容在一定程度上保障了性能的强劲,同时 TTL 和标签机制也实现了对业务的透明。
就如零跑汽车的项目对接人所感叹的一样,做汽车这样一种产品,数据量之大难以想象,如果没有一款能够实现高效存储的数据库,服务器成本会非常的高。
但现在他们都找到了破解困境的有效方法。从理论到实践,时序数据库无疑都是车联网的“天选数据库”。
想了解更多 TDengine Database 的具体细节,欢迎大家在GitHub上查看相关源代码。








 京公网安备 11010802041100号
京公网安备 11010802041100号