作者:a171759015_753 | 来源:互联网 | 2023-10-11 13:23
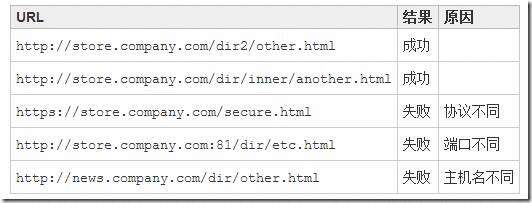
目标页面上有100个url,爬虫会顺着这些url进去爬取内容,有时会返回二十几条内容,有时三十几条,每次都不一样,这是什么原因造成的?
程序结构如下:
1
2
3
4
5
6
7
8
9
| start_urls = [domain_url]
def parse(self, response):
for link in links:
yield Request(link,callback=self.parse2)
def parse2(self,response):
sel =Selector(response)
print sel |
当然,我也设置了DOWNLOAD_DELAY、DOWNLOAD_TIMEOUT、retrymiddleware、UserAgentMiddleware用来改善爬取效果。
但效果不好,怎么去做?谢!
![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号