点击上方DLNLP ,选择星标 ,每天给你送干货!
文 | JayLou娄杰
来自 | 高能AI
试图让美国“再次伟大”的特朗普20日(今日)结束任期了。风靡NLP社区的预训练语言模型能否找到一种方式、让其再次强大呢?
本文JayJay就介绍一种让预训练模型再次强大的方式——虚拟对抗训练 (V irtual A dversarial T raining,VAT )。通过本文,希望传递给大家一个idea:在相同的预训练时间下,对BERT采取虚拟对抗训练,则效果会更好!
众所周知,泛化性 和鲁棒性 都是设计机器学习方法的关键要求。对抗训练在CV领域已经有着广泛的研究和应用,但一些研究表明:对抗训练虽然可以增强鲁棒性,但会损害泛化性 [1] 。
在NLP中,BERT等大型预训练语言模型在下游任务中有良好的泛化性能;通过对抗训练是否可以进一步增加泛化能力呢?不恰当的对抗训练方式是不是会损害BERT呢?BERT是不是也经受不住“对抗攻击”呢?
带着这些疑问,我们介绍一篇来自微软 在ACL20的paper《Adversarial Training for Large Neural Language Models 》,这篇论文首次全面对「对抗预训练 」进行了全面研究,建立了一种统一的、适配于语言模型的对抗训练框架——ALUM (A dversarial training for large neural L angU age M odels)。
具体地,这篇paper的主要精华有:
提出对抗训练框架ALUM ,可同时应用到预训练和微调两个阶段。
全面分析了对抗训练在从头预训练 、持续预训练 、任务微调 下的表现。
对抗训练框架ALUM 超过了一众预训练模型的指标,同时提升鲁棒性和泛化性 。
论文下载地址 :https://arxiv.org/pdf/2004.08994
论文开源地址 :https://github.com/namisan/mt-dnn
本文的组织结构为:
1、NLP中的对抗训练怎么做? 不同于CV的对抗训练是在像素级别,由于文本输入是离散,NLP通常是在embedding空间添加扰动。
对抗训练的目标损失函数是一个Min-Max公式:
Min-Max公式分为两个部分:
2、ALUM的关键:虚拟对抗训练 ALUM既能应用在预训练阶段,也能应用在微调阶段。ALUM采取(划重点)虚拟对抗训练 进行,不是上述传统的对抗训练。
那什么是虚拟对抗训练(VAT)呢 ?
VAT不需要标签信息,可应用于无监督学习,其梯度上升的方向是能使输出分布偏离现状的方向,而传统对抗训练找的是使模型预测最大偏离label的方向。因此,VAT不使用真实label,而是虚拟label 。其实虚拟label就是当前模型的预测结果,是Soft的logit。
ALUM的目标函数是:
ALUM既包含有监督损失,也包括VAT损失(红框部分)。
ALUM为什么要使用VAT呢?
VAT不使用真实label,表明其更适合在标签嘈杂的情况下使用,而且比传统的对抗训练更具优势 。特别是:预训练进行MLM任务的时候,使用被MASK的单词作为自我监督的标签,而其他相似词汇作为预测标签也没错,而且这种做法会更加Soft。可见:VAT会更加适合MLM预训练这种嘈杂的任务。
在上述ALUM的目标函数中,对于预训练阶段,
ALUM的扰动计算过程,与PGD方法类似,具体可参考文献[2] 。其具体计算流程如下图,繁杂数学公式并不影响我们理解ALUM的核心观点,所以感兴趣的同学可参见原论文。
理论上,迭代次数K值越大,估计越好,但训练时间越长。论文折中,取
3、ALUM表现如何? 3.1 泛化性比较 :
论文采取3种设置在GLUE等数据集上进行了验证:
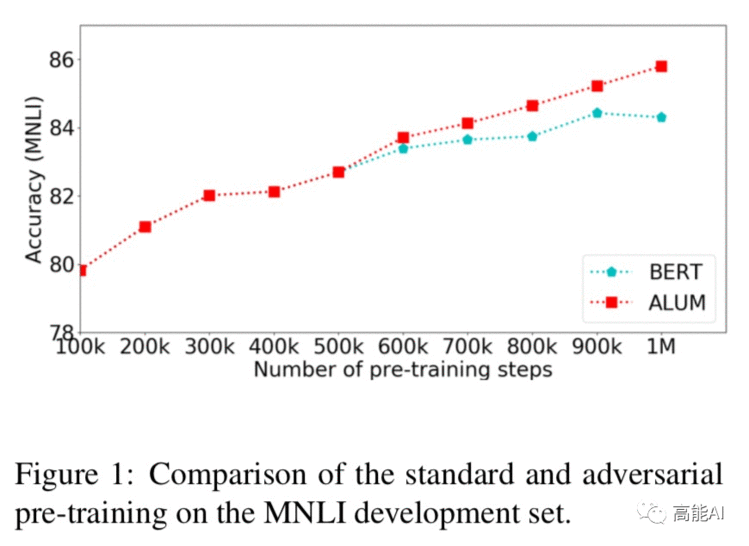
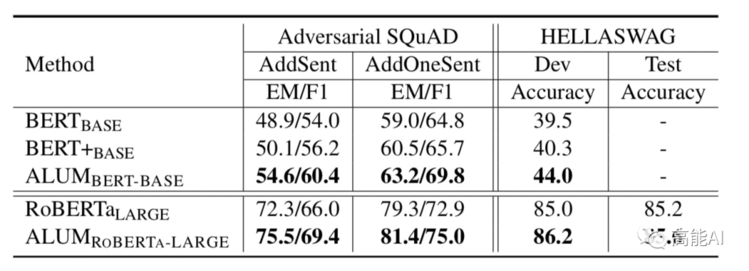
如上图给出了ALUM与BERT的对比,ALUM在500k步以后进行VAT,加入VAT后虽然总体训练时间是BERT的1.5倍,但指标提升明显。
上图也给出3种不同预训练方式下的指标对比,可以看出:
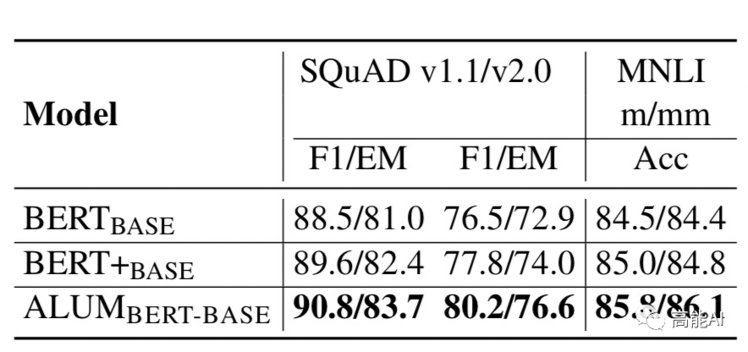
ALUM相较于原生BERT,指标提升均在2%左右!
由
ALUM 和
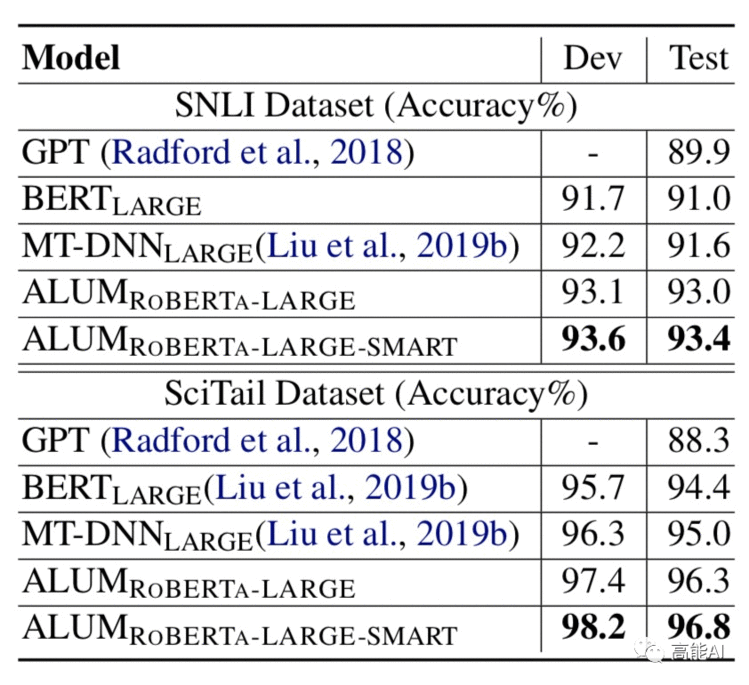
同样,论文也在预训练充分的RoBERTa模型上进行了对比,ALUM同样取得最佳效果!
3.2 鲁棒性比较 :
论文也在对抗数据集上,将ALUM与其他预训练模型进行了对比,ALUM取得最佳效果,显著提升鲁棒性 。
3.3 预训练和微调阶段都进行对抗训练 :
论文也在 预训练和微调阶段都进行对抗训练的情况进行对比(如上图),发现继续在微调阶段进行VAT,指标还会继续提升 。
总结 本文介绍了一种针对预训练语言模型进行对抗训练的方法——ALUM,主要结论如下:
虽然之前的工作表明:对抗训练不同时兼具提升鲁棒性和泛化性,但ALUM可以调和这一冲突,这主要归咎于预训练阶段进行了对抗训练。此外,之前工作是在有监督条件下进行的对抗训练,这表明对未标记数据的虚拟对抗性训练是更为work,更能调和泛化性与鲁棒性之间的明显冲突。
当然,本文介绍的ALUM仍然有进一步提升空间,例如继续加速对抗训练、应用到更广泛的领域等。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方 “深度学习自然语言处理 ”,进入公众号主页。
(2)点击右上角的小点点 ,在弹出页面点击“设为星标 ”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向 ,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
参考资料 [1]
The curious case of adversarially robust models: More data can help, double descend, or hurt generalization: https://openreview.net/forum?id=1dUk8vfKbhP
[2]
【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现: https://zhuanlan.zhihu.com/p/91269728
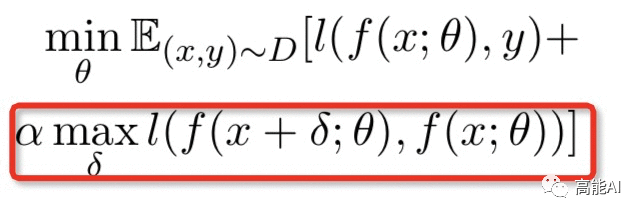

 。
。




![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号