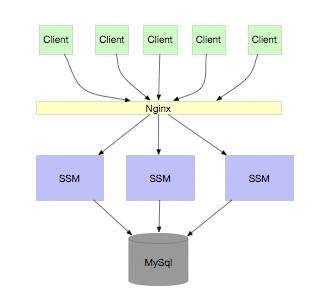
案例小故事某公司的技术架构体系目前还是以集群扩展体系为主,集群扩展体系架构如图9-1所示。在这种体系结构中,可以看到应用都是单块结构,但是单块结构的应用具有扩展性,通过部署在多个T
案例小故事
某公司的技术架构体系目前还是以集群扩展体系为主,集群扩展体系架构如图9-1所示。在这种体系结构中,可以看到应用都是单块结构,但是单块结构的应用具有扩展性,通过部署在多个Tomcat上实现应用的集群,所有的应用都访问同一个数据库(这个库可以假设为Oracle数据库),数据库间采用DataGuard来实现主从同步,读库只具有读取功能,为后台数据统计功能提供数据查询和统计服务。目前业务请求的并发量每分钟有几十笔交易,看起来这套架构还是能够支撑目前的业务发展的。
突然有一天客户在做活动的时候,监控中心出现各种告警,在每分钟500TPS的时候很多请求超时,监控显示目前的服务器不能支撑这么大的并发量,于是快速增加服务器部署应用上线,发现根本没用,加了和没加一样,加几台都一样,运维和DBA发现此时的数据库压力非常大,好不容易熬过这段时间后,团队成员痛定思痛,一致认为目前的架构体系已经不能支持业务的发展,微服务开始快速推进。
其中微服务的数据去中心化核心要点是:每个微服务有自己私有的数据库持久化业务数据。每个微服务只能访问自己的数据库,而不能访问其他服务的数据库。某些业务场景下,需要在一个事务中更新多个数据库。这种情况也不能直接访问其他微服务的数据库,而是对微服务进行操作。数据的去中心化进一步降低了微服务之间的耦合度。

图9-1
最终经过服务化改进后,架构变成了如图9-2所示的样子。

图9-2
问题随后就来了:
(1)以前团队一共就10个人,只负责一二个项目,现在突然增加到平均每人维护二三个项目,上线还是采用由运维手工打war包,如果有修改的配置文件,则运维人员需要一台一台地进行修改,不仅容易上线出错,而且每次上线都会搞到半夜。
(2)根据上面提到的数据去中心化原则,数据库拆分出来了,一个服务一个数据库实例,但是对后台统计系统来说就是“噩梦”,数据库拆分出来了,统计工作、报表工作该怎么办呢?这部分工作还做不做呢?有人说可以分开统计,一个库一个库进行统计,可是这样的工作量将是巨大的。
(3)机房的双活问题,对于金融公司来说双活还是很关键的一项技术指标。应用双活其实比较容易实现,但对于数据库来说却是一个技术问题了,对于Oracle数据库来说,用Oracle官方提供的OGG(Oracle GoldenGate)进行数据同步,根据论坛上面的资料可以看出,OGG的“坑”非常多,而且也容易丢数据,更重要的是贵。采用Oracle的logminer进行同步,同步的数据不是实时的,会有一定延时。而且在定时读取方面还需要自己进行开发,采用Oracle的DataGuard也只能做主从同步,不能做主主双活。调研过后,最终还是决定自己独立开发。
从单块系统到微服务是逐步演进的过程,如果前期没有调研,没有一个整体规划,后期在实现微服务的时候会发现需要做的事情只会越来越多,尤其是对于快速发展的创业型公司来说。针对以上问题,我们如何解决?上面说的第一个问题可以通过合理实施DevOps来解决,而第三个双活问题在本书相应章节中也有详细介绍,本章将给出合理方案深入讨论如何解决第二个问题,即如何在微服务场景下进行数据统计和抽取。
在企业中,需要将不同服务所属的数据库数据抽取到数据仓库,以便能够对平台进行查询和统计,而优秀的数据仓库离不开良好的数据体系的支撑与维护,数据体系建设是一系列长期的、迭代的过程。
什么是数据仓库
第一次接触数据仓库的读者对这个概念会比较陌生,可能会有这样的疑问,什么是数据仓库?为什么要建立数据仓库呢?下面从数据仓库的定义、特点及数仓(数据仓库简称)与操作型数据库的区别三个方面了解数据仓库。
1.数据仓库的定义
最早数据仓库这个概念是由被称为“数据仓库之父”的Bill Inmon提出的,并且在其出版的Building the Data Warehouse一书中给出了数据仓库的详细定义。Inmon在Building the Data Warehouse中定义数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合,用来支持管理人员的决策。
2.数据仓库的特点
1)面向主题
数据仓库采用面向主题的方式组织数据。数据仓库主要是为公司决策者提供数据依据,决策者更关注整体数据反映的情况。以面向主题的方式组织数据可以将各分散子应用或子系统的数据按照主题组织在一起,让决策者可以从更高层面分析数据,挖掘数据背后蕴藏的商业价值,指导决策者做出正确的判断。
2)集成性
数据仓库中集成了各分散数据源的数据。对多个来源、多种类型的数据进行统一加工、汇总、整理,去除数据中的“杂质”,规范字段格式,保证数据仓库中的数据具有全局一致性。
3)相对稳定
操作型数据库中的数据是实时更新的,数据仓库中的数据相对稳定,不会频繁地执行修改、删除操作。在数据仓库中以查询操作为主,数据经过加工进入数据仓库之后一般不会发生改变,会被长期保存或根据业务需求保存很长一段时间后被删除。
4)反映历史变化
数据仓库的主要任务是对大量历史数据进行统计分析,决策者根据历史数据分析结果预测未来发展趋势。
3.数据仓库与操作型数据库对比
下面从几个重要的方面对比数据仓库与操作型数据库的区别,如表9-1所示。
对 比 项 |
操作型数据库 |
数 据 仓 库 |
面向用户 |
开发工程师、数据库工程师等 |
公司管理层、数据分析师等 |
功能 |
提供增、删、改、查基本操作 |
分析决策 |
设计目标 |
面向应用 |
面向主题 |
数据存储时间 |
几个月,一般不存储历史数据 |
历史数据,几年甚至更长时间 |
存储的数据量 |
MB、GB级别 |
GB、TB、PB级别 |
满足第三范式 |
必须满足 |
不需要必须满足 |
事务支持 |
必须支持 |
一般不需要支持 |
响应时间 |
毫秒级 |
秒级、分钟级甚至小时级 |
表9-1
操作型数据库面向的用户是开发工程师、DBA等一线工程师,主要功能是使用一些商用或开源的关系型数据库(如Oracle、SQL Server、MySQL等)进行事务处理,通常把这种事务处理过程称为联机事务处理OLTP(On-LineTransaction Processing)。OLTP数据库的设计目标是面向应用设计,核心工作是对单条数据进行高效地增、删、改、查操作。通常在数据库中存储的数据是几个月内的数据,不会存储几年的历史数据,存储的数据量一般在GB级别。数据库中表的设计需要满足第三范式的要求,尽量减少数据冗余存储。操作型数据库对于单次请求的响应时间要求非常严格,通常是毫秒级延迟,太高的延迟会影响用户的正常使用。
数据仓库(简称数仓)面向的用户是公司管理人员、数据分析师等与分析决策相关的人员,主要功能是为分析决策提供依据。通常把使用数据仓库进行分析的过程称为联机分析处理OLAP(On-LineAnalytical Processing)。在实际工作中,一般不会使用传统的操作型数据库构建数据仓库,因为关系型数据库的核心是对单条数据的事务操作,OLAP的核心是对大量的数据进行统计分析,不需要支持事务,对单条数据统计也没有任何实际意义,所以一般会使用商用的分析型数据库(如Teradata、Oracle Exadata、BD2等)或开源的大数据项目(如Hadoop、Hive等)构建企业级数据仓库。数据仓库的设计目标是面向主题设计,通常在数据仓库中会存储几年甚至十几年的历史数据,存储的数据量一般在GB甚至PB级别,数据分析人员在日常工作中需要频繁地对大量的历史数据进行统计分析。数据仓库中的表设计不需要满足第三范式,对常用的操作也不需要支持事务。对于数据仓库中的查询请求的响应时间的要求不是很高,因为更多的是对大量历史数据的统计分析请求,所以响应时间一般是秒级或分钟级,有时由于数据量非常巨大,硬件资源有限,响应时间有可能会是小时级。
数据仓库架构
在设计数据仓库之前,需要做大量的准备工作。首先,要调研数据的产生来源、数据格式、数据类型等信息,详细掌握数据源信息。其次,还要与合作的数据应用部门或团队沟通,详细了解业务需求,在数据仓库的设计过程中需要根据具体的业务需求创建主题。
前期准备工作完成之后,开始进入数据仓库设计环节。数据仓库通常采用分层设计,一般会分为临时数据存储层ODS(OperationData Store,简称ODS)、数据仓库层DW(Data Warehouse,简称DW)、数据集市层DM(Data Mart,简称DM)三层。
各分层的详细描述如下。
ODS层:暂时存储从各种数据源导入的原始数据。ODS层存储的数据通常是没有经过加工或只进行了简单的加工,相对比较粗糙的数据。它的主要作用是为后续DW层提供集合好的数据源。
DW层:持久化存储从ODS层经过仔细加工之后的数据。DW层存储的数据具有一致性、准确性的特点,并且存储的是没有杂质的明细数据。通常为提高DW层的查询性能,在明细数据的基础上,根据业务需求进行预聚合操作,生成汇总数据。
DM层:数据集市层也可以称为应用层,DM层主要是各个应用部门或业务团队在DW层基础之上,进行二次加工计算,建立针对部门或业务线的数据集市,这样的数据集市可能会有多个。
数据仓库的架构如图9-3所示。

图9-3
数据仓库建模方法
在数据仓库建模领域有两种主流的建模方法,一种是Inmon提出的依托于OLTP数据库,采用自上而下的建模方法,先对企业级数据仓库进行总体设计,在数据仓库基础之上,根据业务部门的不同需求构建数据集市。另一种是Kimball提出的维度建模,采用自下而上的建模方法,先构建数据集市,然后将多个数据集市整合成一个数据仓库。
目前,这两种建模方法在学术界和工业界都得到了广泛认可,并且在生产环境中已经被大规模应用。这两种建模方法没有好坏之分,用户可以根据公司目前所处阶段、业务复杂度、公司规模等条件选择合适的建模方法。当公司处于早期阶段,公司规模较小,业务发展速度非常快,有可能需要经常调整业务方向。针对这种情况,可以选择使用Kimball的维度建模法,快速地搭建数据仓库,及时响应业务需求。当公司处于稳定阶段,公司属于大中型规模,业务发展稳定,并且已经有了一定的数据积累。针对这种情况,可以选择Inmon的建模方法,从上到下系统地规划设计,这种方法的开发周期比较长,但是一旦搭建成功,后期维护将非常方便。
数据抽取、转换和加载
在构建数据仓库的过程中,需要将各分散数据源中的数据整合在一起,不同数据源的数据格式、字段描述、存储方式等信息各不相同,有些数据中还存在大量的脏数据。数据仓库要求必须是干净的、规范的、一致性的数据才可以被加载到数据仓库中。所以原始数据源的数据要经过抽取、清洗转换之后才会被加载到数据仓库中,这个数据被加工处理的过程称为ETL。
ETL是抽取(Extract)、转换(Transformation)、加载(Load)的简称,目的是将企业中分散、不规范、不一致的数据整合到一起,为后续的统计分析工作提供准确的数据支撑。
ETL不只发生在数据加载进数据仓库之前,在数据仓库各层之间也会涉及ETL。ETL在数据仓库中起着非常重要的作用,决定了最终分析结果的准确性。在构建数据仓库的过程中,ETL会耗费大量的时间,有些公司会专门设置ETL工程师的岗位专门从事ETL工作。
数据统计
数据从业务系统经过ETL进入数据仓库,为后续的数据统计工作提供基础数据。数据工程师基于数据仓库进行数据处理和统计分析工作,最终的统计结果会被导入BI系统为决策者提供数据依据。整个数据处理和统计流程如图9-4所示。

图9-4
数据统计分析的过程是基于数据仓库中进行的,公司决策者使用的BI系统与数据仓库是两套系统,那么就会涉及统计结果在两个系统之间的传输问题。解决这个问题有三种常用方法。
(1)将统计结果保存到TXT、CSV等数据文件中,然后使用关系型数据库的数据导入工具将数据文件导入BI系统可以访问的关系型数据库表中。
(2)将统计结果保存到数据仓库应用层的数据表中,搭建中间数据服务系统,该系统通过JDBC/ODBC访问应用层数据表中的数据,BI系统通过中间数据服务系统获取相关数据。
(3)如果数据仓库是基于Hadoop/Hive构建的,那么可以将统计结果保存到HDFS的指定目录中,通过Sqoop等工具将存储在HDFS中的结果数据导入BI系统的关系型数据库表中。
数据仓库工具Hive
Hive是一款基于Hadoop的数据仓库解决方案。Hive最初是由Facebook开发的,后来贡献给Apache软件基金会,将其命名为Apache Hive并作为一个独立开源项目。Hive不是一个关系型数据库,不提供数据存储服务,真正的数据存储在Hadoop的分布式文件系统HDFS中。Hive主要负责元数据管理,把研发工程师或数据分析师熟悉的SQL语句转换为Hadoop的分布式处理程序MapReduce,然后将MapReduce程序调度到Hadoop中运行,对存储在HDFS上的大规模数据进行分析处理。
虽然Hive不是一个关系型数据库,但是Hive支持类似关系型数据库中的数据库、表、视图等概念。对于熟悉数据库的用户来说学习成本非常低,可以像操作关系型数据一样使用Hive。Hive提供了一种类SQL的查询语言HiveSQL,它的语法与MySQL的语法非常相似,熟悉MySQL的用户可以非常快速地掌握HiveSQL。
HiveSQL内置了很多常用的运算符和函数,能够满足日常的大部分工作需求。对于HiveSQL中没有提供的函数或用户需要处理的一些个性化需求,可以通过用户自定义函数UDF或用户自定义聚合函数UDAF进行扩展实现。
Hive的架构如图9-5所示。

图9-5
Hive允许用户通过三种方式访问Hive,分别如下:
(1)通过命令行接口(CLI)交互式地访问Hive,这种方式简单方便。
(2)为了方便用户使用不同编程语言开发的程序访问Hive,Hive提供了跨语言Thrift服务,在程序中通过JDBC或ODBC直接访问Hive。
(3)Hive提供了可视化操作工具HWI,用户可以更加直观地通过试图界面访问Hive。
ETL作业调度
ETL过程会调度大量的作业,在项目初期业务比较简单的阶段,一种比较经典的调度方式是通过Linux系统的crontab调度作业脚本执行调度的,在Linux系统中,用户可以通过编辑crontab文件设置需要定时执行的作业。crontab文件中的一行就是一个待执行的作业,Linux系统通过后台服务进程crond定期检查crontab文件中是否有要执行的任务,从而实现定时自动执行某个任务。
例9-3每天凌晨1点15分执行数据抽取脚本sqoop_import_consumer_address_df.sh,作业执行过程中产生的日志输出到sqoop_import_consumer_address_df.log日志文件中。
使用crontab定时执行作业的优点是操作简单,适合在简单地业务场景下使用。缺点也很明显,在复杂的业务场景下通常需要调度大量的作业,有些作业需要并行执行,有些作业需要前后依赖执行,需要编写大量的脚本控制各个作业的执行流程,需要工程师投入大量的精力维护这些脚本,作业的监控管理也非常不方便。
在复杂的业务场景下,通常会选择使用操作更加灵活、功能更加强大、方便监控管理的开源调度系统或公司内部自研的调度系统进行自动化调度。这种调度方式不但可以周期性地并行执行各种作业,还可以设置复杂的作业之间的依赖关系。工程师可以对作业整个运行流程进行监管,当作业运行失败时会立即向管理员发送报警信息,如果配置了重试机制,那么调度器针对失败的作业还会重新调度执行。常用的开源工作流调度系统有Apache Oozie、Azkaban等。

本文节选自《高可用可伸缩微服务架构:基于Dubbo、Spring Cloud和Service Mesh》一书,程超,梁桂钊,秦金卫,方志斌,张逸等著,电子工业出版社出版,点击阅读原文,可直接购买此书。
往期推荐:









 京公网安备 11010802041100号
京公网安备 11010802041100号