-password PING
如果Ping不通,说明Server确实Hang住了;如果Ping得通,说明Server没Hang住,而是应用自身Hang住了,应该检查应用(可能是jsp页面编译时间过长、远程JNDI lookup查找时间过长、应用程序死锁)。
(2)查看线程
查看工作线程:Listener、Socket Reader、Execute是否存在,并正常工作;是否Execute线程都处在忙碌状态。可通过附件1如何产生线程堆栈的方法打印线程快照进行分析每个线程在忙些啥。
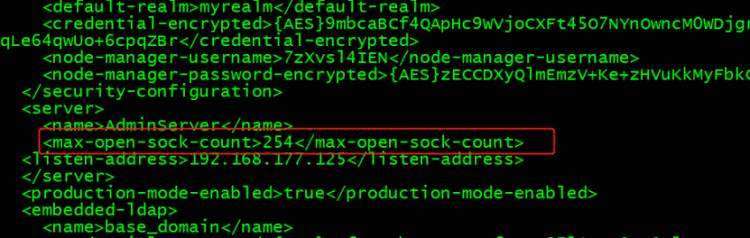
若1:查看到hang时仍然有空闲的执行线程,则需要确定Socket Reader 线程都在正常工作;适当提高 Socket Reader 线程数;集群环境下需要更多的Socket Reader 线程来接受请求。在配置文件新增如下:
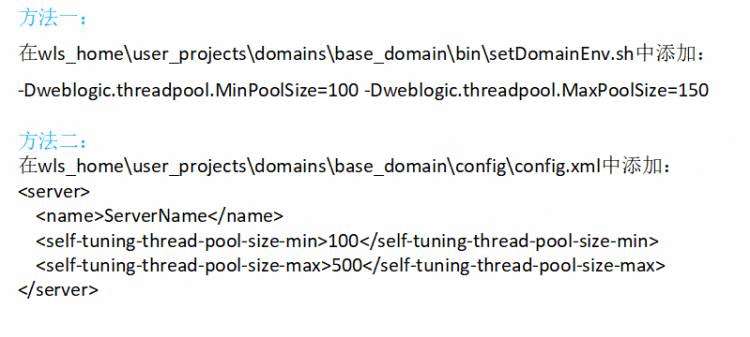
若2:查看到hang时没有空闲的执行线程,则需要增加更多的线程数量,操作如下:
2.2 系统内存不足
(1) 典型的现象是在hang住时抛出OutOfMemoryError错误,此情况可能是堆内存不足、栈内存不足、永久代内存不足或者本地内存直接溢出。设置如下:
堆内存:-Xmx8g -Xms8g
栈内存:-Xss1m
永久代:-XX:PermSize=512m -XX:MaxPermSize=1024m
本地内存:-XX:MaxDirectMemorySize=10g
(2) 通过top或vmstat观察到操作系统内存和swap区的使用量接近100%,Swap区太小可能导致编译jsp时报“Not enough space”的错。

(3) 检查是否存在内存泄漏,典型的就是数据库连接没有正常关闭,可通过管理控制台查看连接池是否存在连接泄露。
(4)检查应用程序session中是否存放大的数据。
2.3 垃圾回收占用太多时间
2.3.1 基础知识
众所周知的,jvm在执行垃圾回收(FullGC)时是要暂停整个应用的,但是由于FullGC时间过长,就会出现服务hang的现象。
2.3.2 诊断步骤
可通过jstat命令打印gc信息进行分析。
jstat -gc pid
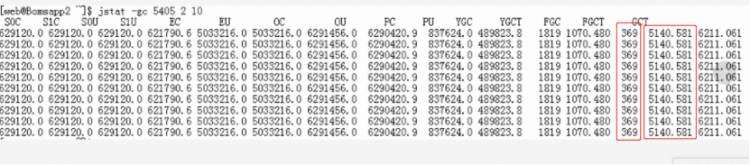
通过上图可以看到FullGC的次数和时间。进一步分析可能是由于资源不足导致的,紧接着按照2.2系统内存不足,确定是否为堆内存太小导致的,那么添加内存。
2.4 系统文件描述符数目不足
2.4.1 基础知识
当服务hang住时,Log中有“too many open files”的错误,表示达到了系统对一个进程能同时打开的文件数的限制。
2.4.1 诊断步骤
ulimit –a –H 可以查看当前限制
ulimit –n number可以来更改当前环境的设置,建议至少设到4096
可以通过/etc/security/limits.conf soft,hard 来动态更改进程的文件描述符的限制
2.5 系统高CPU
2.5.1 基础知识
CPU作为系统的计算和控制核心,是信息处理、程序运行的最终执行单元。
2.5.2 诊断步骤
(1)如果是用户请求量较大情况下,高CPU属于正常现象。
(2)排除用户量访问较大的可能情况,采用top命令找到占用CPU很多的进程,如果是非weblogic进程,应该考虑将其移到另外的server上运行,如果是运行weblogic的java进程,通过做thread dump,参照附件1如何产生线程堆栈来确认是那段代码导致了这么高的CPU使用(也有可能是os/jvm本身不正常,例如长时间的FullGC执行占用了较高的CPU) 。具体操作如下:
查看CPU使用较高的进程pid:top
查看进程中的前10个较高线程tid:top -Hp tid
通过对pid进行十六进制转换得到nid:printf “%x\n” tid
将得到的十六进制nid放到产生的线程dump中查看该线程在忙些啥.
2.6 线程死锁
2.6.1 基础知识
(1)线程状态
1、 新建状态(New): 新创建了一个线程对象。
2、 就绪状态(Runnable): 线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3、运行状态(Running): 就绪状态的线程获取了CPU,执行程序代码。
4、阻塞状态(Blocked): 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占
用,则JVM会把该线程放入锁池中。
其他阻塞:运行的线程执行sleep()或join()方法。,或者发出了I/O请 求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5、死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
在故障处理中最关注的就是Running、Blocked
(2)weblogic线程状态的一般信息
1、活动执行线程:池中的活动执行线程数。(可在config.xml下进行配置)
2、空闲执行线程:池中的空闲线程数。此计数不包含待机线程数和阻塞线程数。该计数表示新工作到达时准备好采用该工作的线程数
3、队列长度:优先级队列中的暂挂请求数。这是内部系统请求和用户请求的总数。
4、暂挂用户请求数:优先级队列中的暂挂用户请求数。优先级队列包含来自内部子系统和用户的请求。这只是所有用户请求的计数。
5、完成的请求:优先级队列中完成的请求数。
6、独占线程数:请求现在所保留的线程。这些线程将在配置的超时过后被声明为粘滞或在超时结束前返回给池。自优化机制将在必要时进行回填。
7、备用线程数:备用池中的线程数。处理当前工作负载所不需要的线程将被指定为备用线程并会添加到备用池中。需要更多线程时将激活这些线程。
8、吞吐量:每秒平均完成的请求数(具体为最近几秒尚不清楚)
在故障处理中最关注的就是:是否有独占线程(STUCK)
2.6.2 诊断步骤
对于原因不明的hang或是响应慢,最根本的方法就是根据附件1如何产生线程堆栈获取thread dump信息,为了反映线程状态的动态变化,需要接连多次做thread dump,每次间隔10-20s。
对于thread dump信息,主要关注的是线程的状态和其执行堆栈,线程的状态一般为三类
Runnable(R):当前可以运行的线程
Waiting on monitor(CW):线程主动wait
Waiting for monitor entry(MW):线程等锁
一般关注的都是第一和第三种状态的线程
CPU很忙则关注runnable的线程
CPU闲则关注waiting for monitor entry的线程
一种典型的死锁是由于在server端应用(比如servlet)中请求由同一weblogic实例serve的资源,造成资源争用,相互等待,解决办法就是将该servlet放到另外的执行队列里去执行,排查方法可以使用我的另一篇文章(排查CPU占用率高、线程间死锁的脚本)。
2.7 JDBC死锁
2.7.1 基础知识
Weblogic连接池里存放的都是已经建立好的、到特定数据库的物理连接,当应用程序请求访问数据库时,可以直接使用这些连接访问数据库。如果连接池中的连接数已经达到最大值,就会让该请求排队等待,其他请求释放连接时,会让等待队列中的请求使用新释放的连接。如果数据库出现故障不响应的情况,weblogic连接池里面的连接全部被用完处于连接状态,此时就会发生连接池过载(overload)或者hang死。
2.7.2 故障诊断
(1)查看连接池是否有等待连接的请求队列数量、查看连接池状态是否过载
附件1:如何产生线程堆栈1、ctrl + break (windows)
2、kill -3 pid 2>&1
3、beasvc -dump -svcname: (windows wls10.3.5版本以上可用)
4、wlsvc -dump -svcname: (windows wls10.3.6~12.1.1可用)
5、使用wlst工具:
setDomainEnv.sh/cmd
wlst.sh/cmd
connect()
threadDump()
6、weblogic管理控制台:
base_domain—> 环境—> 服务器—>servername—>监视 —>线程---->转储线程堆栈
7、使用 java VisualVM 工具
8、jstack pid or jstack -l pid >thread_pid.dump
9、jrcmd pid print_threads (jRocket)
10、jcmd pid Thread.print ( jdk7 java Mission Control )




 京公网安备 11010802041100号
京公网安备 11010802041100号