优化版后的网络架构图:

参考文献:
https://arxiv.org/pdf/1808.08762.pdf
实现代码(自己修改了一部分,性能更高):
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 22 12:02:08 2018@author: Lenovo
"""import pandas as pd
from keras.layers import Subtract,Dense,Reshape,BatchNormalization,Lambda,Flatten,Dot,MaxPooling2D,AveragePooling2D,AveragePooling1D,Concatenate,MaxPooling1D,Conv2D,Conv1D,Embedding,CuDNNLSTM,Input,Activation,Multiply,Bidirectional,Dropout
from keras.models import Model,Sequential
from keras.optimizers import SGD,Adam
from keras.callbacks import ModelCheckpoint,EarlyStopping
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
import numpy as np
from data_process import get_data
from keras.utils import plot_model
import matplotlib.pyplot as plt
import keras.backend as K
import tensorflow as tfdef adbsub(x):x1,x2 = xreturn tf.abs(tf.subtract(x1,x2))def calc_01(x):x_1,x_2 = xreturn K.cast(K.equal(x_1,x_2),dtype='float32')def stack_dot_01(x):x_1,x_2 = xreturn K.stack(x,axis=-1)category = ["unrelated","agreed","disagreed"]
#train_x_1,train_x_2,label,vsize,test_x_1,test_x_2,test,train_jiao,test_jiao = get_data()x_1_input = Input(shape=([50]))
x_2_input = Input(shape=([50]))
x_jiao_in = Input(shape=([1]))embedder = Embedding(input_dim=vsize+1, output_dim=300)
x_1_in = embedder(x_1_input)
x_2_in = embedder(x_2_input)
#x_1 = Conv1D(32,3,strides=1,padding='same',activation='relu')(x_1)
#x_2 = Conv1D(32,3,strides=1,padding='same',activation='relu')(x_2)
##x_1 = BatchNormalization()(x_1)
##x_2 = BatchNormalization()(x_2)
###做这个池化 有可能会导致信息失真
#x_1 = MaxPooling1D(pool_size=3,strides=2)(x_1)
#x_2 = MaxPooling1D(pool_size=3,strides=2)(x_2)
#
bilstm_1 = Bidirectional(CuDNNLSTM(units=150,return_sequences=True,return_state=True))
lstm11 = bilstm_1(x_1_in)
x_1_b_m_1 = MaxPooling1D()(lstm11[0])
lstm12 = bilstm_1(x_2_in)
x_2_b_m_1 = MaxPooling1D()(lstm12[0])
#
bilstm_2 = Bidirectional(CuDNNLSTM(units=150,return_sequences=True,return_state=True))
lstm21 = bilstm_2(Multiply()([x_1_in,lstm11[0]]))
x_1_b_m_2 = MaxPooling1D()(lstm11[0])
lstm22 = bilstm_2(Multiply()([x_2_in,lstm12[0]]))
x_2_b_m_2 = MaxPooling1D()(lstm12[0])#
bilstm_3 = Bidirectional(CuDNNLSTM(units=150,return_sequences=True,return_state=True))
lstm31 = bilstm_3(Multiply()([x_1_in,lstm21[0]]))
x_1_b_m_3 = MaxPooling1D()(lstm31[0])
lstm32 = bilstm_3(Multiply()([x_2_in,lstm22[0]]))
x_2_b_m_3 = MaxPooling1D()(lstm32[0])x_Concatenate = Concatenate()([x_1_b_m_1,x_2_b_m_1])
x_Subtract = Lambda(adbsub)([x_1_b_m_2,x_2_b_m_2])
x_Multiply = Multiply()([x_1_b_m_3,x_2_b_m_3])
x_m_1 = Concatenate()([x_Concatenate,x_Subtract,x_Multiply])#x_m_2 = Concatenate()([x_2_b_m_1,x_2_b_m_2,x_2_b_m_3])#x_1 = BatchNormalization()(x_1)
#x_2 = BatchNormalization()(x_2)
##
#bilistm_merge = Multiply()([x_1,x_2])
#b_out = Bidirectional(CuDNNLSTM(units=128))(bilistm_merge)
#b_jiao = Bidirectional(CuDNNLSTM(units=128))(bilistm_merge)
#b_out = BatchNormalization()(b_out)
#
#bilstm_2 = Bidirectional(CuDNNLSTM(units=50))
#x_1 = bilstm_2(x_1)
#x_2 = bilstm_2(x_2)
#x_1 = BatchNormalization()(x_1)
#x_2 = BatchNormalization()(x_2)
#
#x_2c = Concatenate(axis=-1)([x_1,x_2])
#x_2c = BatchNormalization()(x_2c)
##
#x_2c = Reshape((2,100,1))(x_2c)
#x_2c = Conv2D(2,kernel_size=(2,3),strides=(1,1),padding='same',activation='relu')(x_2c)
#x_2c = BatchNormalization()(x_2c)
#x_2c = Conv2D(2,kernel_size=(2,3),strides=(1,1),padding='same',activation='relu')(x_2c)
#x_2c = BatchNormalization()(x_2c)
#
#x_2c = AveragePooling2D((2,2),(1,1))(x_2c)
#x_2c = Flatten()(x_2c)
#x_2c = Dense(256,activation='relu')(x_2c)
#print(x_2c.shape)
#x_1 = Reshape((1,100))(x_1)
#x_2 = Reshape((100,1))(x_2)
#x_01 = Lambda(calc_01)([x_1,x_2])
#x_dot = Multiply()([x_1,x_2])
#
#x_dot = Reshape((200,200,1))(x_dot)
#x_01 = Reshape((200,200,1))(x_01)
#
#x = Lambda(stack_dot_01)([x_dot,x_01])
#print(x.shape)
#x = Conv2D(16,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
#x = Conv2D(16,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
##x = BatchNormalization()(x)
#x = MaxPooling2D((2,2),(2,2))(x)
##
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
##x = BatchNormalization()(x)
#x = MaxPooling2D((2,2),(2,2))(x)
##
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
##x = BatchNormalization()(x)
##x = AveragePooling2D((2,2),(2,2))(x)
##x = Conv2D(64,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
##x = Conv2D(64,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
##x = BatchNormalization()(x)
#x = MaxPooling2D((2,2),(2,2))(x)
##
#
x = Flatten()(x_m_1)
x = Dropout(0.5)(x)
##x = BatchNormalization()(x)
##x = Multiply()([x_1,x_2])
##x = Activation('relu')(x)
x = Dense(256,activation='relu')(x)
#x_jiao_in_1 = Dense(5)(x_jiao_in)
#x_jiao_in_1 = Dense(1)(x_jiao_in)
x = Concatenate(axis=1)([x,x_jiao_in])#x = BatchNormalization()(x)
#x = Concatenate(axis=-1)([x,b_out])
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
#x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(x)
#x = MaxPooling2D((2,2),(2,2))(x)
#x = Reshape((3,256,1))(x)
#x = Conv2D(3,kernel_size=(3,256),strides=(1,1),padding='valid',activation='relu')(x)
##x = BatchNormalization()(x)
#x = Conv2D(3,kernel_size=(3,256),strides=(1,1),padding='same',activation='softmax')(x)
##x = BatchNormalization()(x)
#out = Reshape(([3]))(x)
#x = Flatten()(x)#x = Dropout(0.2)(x)print('朴实无华网络__很猛')
#x = Concatenate(axis=-1)([x_1,x_2])
#x = Flatten()(x)x = Dropout(0.2)(x)out = Dense(3,activation='softmax')(x)model = Model([x_1_input,x_2_input,x_jiao_in],[out])model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['acc'])
model.summary()
plot_model(model,'model.png')
mcp = ModelCheckpoint('wsdm_duoronghe_jiyuci_best.h5',save_best_only=True,monitor='val_acc',verbose=1)
es = EarlyStopping(patience=5,monitor='loss',verbose=1)
cl = [mcp,es]
history = model.fit(x=[train_x_1,train_x_2,train_jiao],y=label,class_weight={0:1,1:5,2:10},batch_size=256,epochs=100,verbose=1,callbacks=cl,validation_split=0.1,shuffle=True)x=history.epoch
y=history.history['acc']
plt.plot(x,y,label="acc")y=history.history['loss']
plt.plot(x,y,label="loss")y=history.history['val_acc']
plt.plot(x,y,label="val_acc")y=history.history['val_loss']
plt.plot(x,y,label="val_loss")result = model.predict(x=[test_x_1,test_x_2])a= np.argmax(result,axis=1)result = pd.DataFrame()
result['Id']=test.id.values
result['Category']=[category[i] for i in a]result.to_csv('submit.csv',index_label=None)
总体架构图:

sentence embedding架构图:

训练呈现:








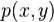


 京公网安备 11010802041100号
京公网安备 11010802041100号