Virgin Hyperloop One(超级高铁公司)是一家从事超级高铁研究的公司,致力于能让高铁达到飞机的速度并且拥有更低的成本。为了能够制造一个商业的系统,我们需要收集并且分析非常大量的各种不同的数据,包括各种运行测试数据,多种模拟数据,技术设施数据,甚至社会经济数据等等。我们之前绝大部分处理数据的代码都是基于pandas使用python脚本来进行处理。之所以写这篇文档是因为我们想分享我们如何使用Koalas在很少修改代码的情况下来扩展我们的处理能力和节省大量处理时间的。
随着我们的业务不断的增长我们的数据量也在不断的增长。我们的数据处理范围越来越大,复杂程度越来越高,这导致我们基于pandas的python脚本越来越慢,知道慢到不能满足我们的商业需求。所以我们调研了Spark,希望使用Spark能够带来更快的处理时间并且能够提供按需灵活弹性的能力。我们尝试这样做了,但是很快我们发现切换到Spark的过程中,我们必须付出非常多的时间把我们之前的基于pandas的python代码修改成基于PySpark的代码。我们意识到我们需要一套能够不需要修改过多代码就能迁移到Spark上的解决方案。我们非常高兴的发现了这个解决方案:Databricks最近开源的Koalas。
Kolas的Readme中是这样写的:
Koalas项目基于Apache Spark实现了pandas DataFrame API,从而使数据科学家能够更有效率的处理大数据。如果你已经熟悉pandas,那么你不需要付出任何学习成本就能使用Spark
一份代码可以同时在pandas(用于测试,小数据集)和Spark(用于分布式datasets)两个平台上运行。
本文我将介绍Koalas为什么值得你去尝试。只需要修改不到1%的pandas代码,我们就能将我们以前的代码跑在Koalas和Spark上。我们将处理时间提升了10倍,从几小时下降到了几分钟。并且我们具备了水平扩展的能力,这使我们能够处理更多的数据。
在安装Koalas之前,首先我们需要一个能够运行PySpark的Spark集群。然后我们执行以下命令:
pip install koalas
如果使用conda,则执行以下命令:
conda install koalas -c conda-forge
更详细的信息可以查看Koalas的Readme文档。
安装完之后我们执行一个快速测试:
import databricks.koalas as kskdf = ks.DataFrame({'column1':[4.0, 8.0]}, {'column2':[1.0, 2.0]})kdf
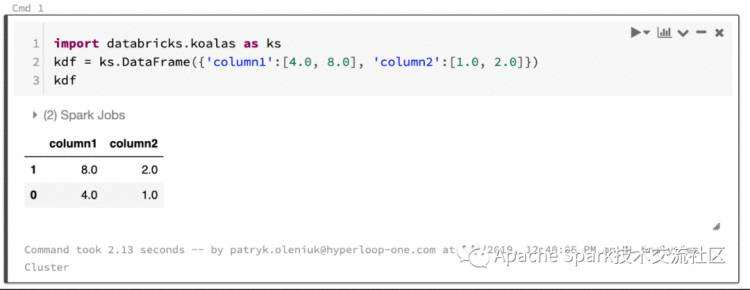
可以看到Koalas渲染出来了pandas风格的interactive tables,这太便利了。
基本操作示例:
首先我们生成了一个含有4列多行的测试数据:
import pandas as pd## generate 1M rows of test datapdf = generate_pd_test_data( 1e6 )pdf.head(3)>>> timestamp pod_id trip_id speed_mph0 7.522523 pod_13 trip_6 79.3400061 22.029855 pod_5 trip_22 65.2021222 21.473178 pod_20 trip_10 669.901507
免责声明:这只是我们随机生成的一些性能测试数据,不是我们真实的数据。完成的测试脚本在这里:https://gist.github.com/patryk-oleniuk/043f97ae9c405cbd13b6977e7e6d6fbc
我们先描述下我们要处理的业务,比如:每个pod-trip的时间是多少。
这需要进行以下操作:
Group by ['pod_id','trip id']
对于每个trip, 计算trip_time,计算逻辑为:last timestamp – first timestamp
计算pod-trip时间分布 (mean, stddev)
(snippet #1)
import pandas as pd# take the grouped.max (last timestamp) and join with grouped.min (first timestamp)gdf = pdf.groupby(['pod_id','trip_id']).agg({'timestamp': ['min','max']})gdf.columns = ['timestamp_first','timestamp_last']gdf['trip_time_sec'] = gdf['timestamp_last'] - gdf['timestamp_first']gdf['trip_time_hours'] = gdf['trip_time_sec'] / 3600.0# calculate the statistics on trip timespd_result = gdf.describe()
(snippet #2)
import pyspark as spark# import pandas df to spark (this line is not used for profiling)sdf = spark.createDataFrame(pdf)# sort by timestamp and groupbysdf = sdf.sort(desc('timestamp'))sdf = sdf.groupBy("pod_id", "trip_id").agg(F.max('timestamp').alias('timestamp_last'), F.min('timestamp').alias('timestamp_first'))# add another column trip_time_sec as the difference between first and lastsdf = sdf.withColumn('trip_time_sec', sdf2['timestamp_last'] - sdf2['timestamp_first'])sdf = sdf.withColumn('trip_time_hours', sdf3['trip_time_sec'] / 3600.0)# calculate the statistics on trip timessdf4.select(F.col('timestamp_last'),F.col('timestamp_first'),F.col('trip_time_sec'),F.col('trip_time_hours')).summary().toPandas()
(snippet #3)
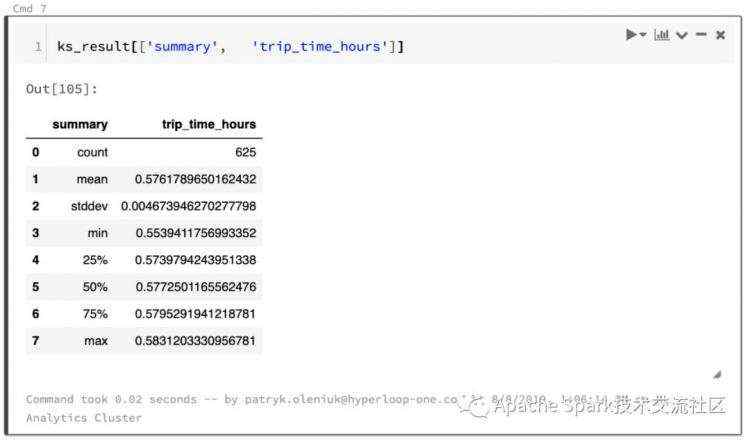
import databricks.koalas as ks# import pandas df to koalas (and so also spark) (this line is not used for profiling)kdf = ks.from_pandas(pdf)# the code below is the same as the pandas versiongdf = kdf.groupby(['pod_id','trip_id']).agg({'timestamp': ['min','max']})gdf.columns = ['timestamp_first','timestamp_last']gdf['trip_time_sec'] = gdf['timestamp_last'] - gdf['timestamp_first']gdf['trip_time_hours'] = gdf['trip_time_sec'] / 3600.0ks_result = gdf.describe().to_pandas()
注意第一段和第三段中的代码基本上一致,可以无缝迁移到Spark上面。对于大多数pandas代码,你只需要将import pandas改为databricks.koalas as pd,对于某些脚本需要微调还有些限制我们下面将会提到。
结果:
All the snippets have been verified to return the same pod-trip-times results. The describe and summary methods for pandas and Spark are slightly different, as explained here but this should not affect performance too much.
上面三段代码经过验证都返回了一致的结果。pandas和spark的describe
和summary
方法不太一样(https://www.kdnuggets.com/2016/01/python-data-science-pandas-spark-dataframe-differences.html)但是这不影响太多性能。
示例的结果
接下来我们用相同的的datafrme来尝试解决负责的计算,从而对比出pandas和Koalas的实现上的不同。
目标:分析每个pod-trip的平均速度:
Group by ['pod_id','trip id']
通过查找下方的速度(时间)表(计算方法连接
https://www.quora.com/How-do-I-find-the-total-distance-covered-from-a-velocity-time-graph 计算出每个pod-trip的总距离。
对group过的df使用timestamp
列排序。
计算timestamps的差值。
将速度和时间戳的差值相乘。-- 这样可以得到在一段时间之内的行驶距离。
对于distance_travelled
进行sum计算 – 这样算出每个pod-trip的距离。
计算 trip time
as timestamp.last – timestamp.first
。
计算 average_speed
as distance_travelled / trip time
。
计算pod-trip时间的分布 (mean, stddev)。
我们使用custom apply function和UDF (user defined functions)来实现上面的计算过程。
(snippet #4)
import pandas as pddef calc_distance_from_speed( gdf ): gdf = gdf.sort_values('timestamp') gdf['time_diff'] = gdf['timestamp'].diff() return pd.DataFrame({ 'distance_miles':[ (gdf['time_diff']*gdf['speed_mph']).sum()], 'travel_time_sec': [ gdf['timestamp'].iloc[-1] - gdf['timestamp'].iloc[0] ]})results = df.groupby(['pod_id','trip_id']).apply( calculate_distance_from_speed)results['distance_km'] = results['distance_miles'] * 1.609results['avg_speed_mph'] = results['distance_miles'] / results['travel_time_sec'] / 60.0results['avg_speed_kph'] = results['avg_speed_mph'] * 1.609results.describe()
(snippet #5)
import databricks.koalas as ksfrom pyspark.sql.functions import pandas_udf, PandasUDFTypefrom pyspark.sql.types import *import pyspark.sql.functions as Fschema = StructType([ StructField("pod_id", StringType()), StructField("trip_id", StringType()), StructField("distance_miles", DoubleType()), StructField("travel_time_sec", DoubleType())])@pandas_udf(schema, PandasUDFType.GROUPED_MAP)def calculate_distance_from_speed( gdf ): gdf = gdf.sort_values('timestamp') print(gdf) gdf['time_diff'] = gdf['timestamp'].diff() return pd.DataFrame({ 'pod_id':[gdf['pod_id'].iloc[0]], 'trip_id':[gdf['trip_id'].iloc[0]], 'distance_miles':[ (gdf['time_diff']*gdf['speed_mph']).sum()], 'travel_time_sec': [ gdf['timestamp'].iloc[-1]-gdf['timestamp'].iloc[0] ]})sdf = spark_df.groupby("pod_id","trip_id").apply(calculate_distance_from_speed)sdf = sdf.withColumn('distance_km',F.col('distance_miles') * 1.609)sdf = sdf.withColumn('avg_speed_mph',F.col('distance_miles')/ F.col('travel_time_sec') / 60.0)sdf = sdf.withColumn('avg_speed_kph',F.col('avg_speed_mph') * 1.609)sdf = sdf.orderBy(sdf.pod_id,sdf.trip_id)sdf.summary().toPandas() # summary calculates almost the same results as describe
(snippet #6)
import databricks.koalas as ksdef calc_distance_from_speed_ks( gdf ) -> ks.DataFrame[ str, str, float , float]: gdf = gdf.sort_values('timestamp') gdf['meanspeed'] = (gdf['timestamp'].diff()*gdf['speed_mph']).sum() gdf['triptime'] = (gdf['timestamp'].iloc[-1] - gdf['timestamp'].iloc[0]) return gdf[['pod_id','trip_id','meanspeed','triptime']].iloc[0:1]kdf = ks.from_pandas(df)results = kdf.groupby(['pod_id','trip_id']).apply( calculate_distance_from_speed_ks)# due to current limitations of the package, groupby.apply() returns c0 .. c3 column namesresults.columns = ['pod_id', 'trip_id', 'distance_miles', 'travel_time_sec']# spark groupby does not set the groupby cols as index and does not sort themresults = results.set_index(['pod_id','trip_id']).sort_index()results['distance_km'] = results['distance_miles'] * 1.609results['avg_speed_mph'] = results['distance_miles'] / results['travel_time_sec'] / 60.0results['avg_speed_kph'] = results['avg_speed_mph'] * 1.609results.describe()
Koalas是基于PySpark的pandas_udf
的来实现的,这就是为什么在定义function的时候需要定义类型提示。这个包的作者介绍了新的类型提示,ks.DataFrame
和ks.Series
。但是当前的实现有些笨重并且需要进行相应的修改才能达到相同的数据结果(改变列名,groupby key不返回)。不过上面这些行为都在文档中进行了适当的说明。
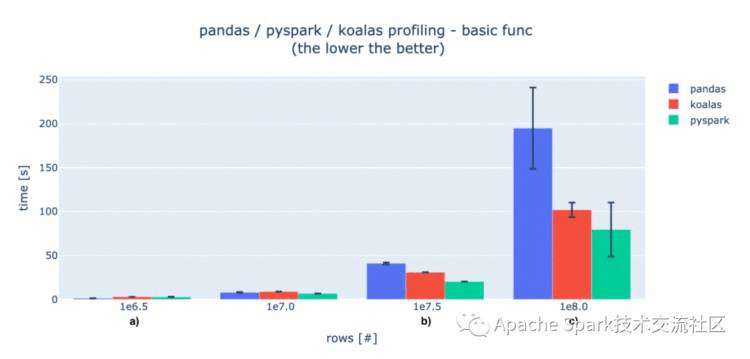
为了评估Koalas的性能,我们对不同的数据量进行了测试。
这个性能测试在Databricks的平台上进行,使用了如下的配置:
1个Spark driver节点 (也用来跑pandas脚本): 8 CPU cores, 61GB RAM.
15个Spark worker 节点: 4CPU cores, 30.5GB RAM (一共: 60CPUs / 457.5GB内存 ).
每次测试重复10次。
当数据很少的时候,初始化的时间和数据传输的时间相对于计算时间要长的多。所以pandas速度快一点(标记a)。当有大量数据的时候,pandas的数据处理时间要多于使用Spark的方案(标记b),我们可以观察到Koalas比PySpark有一些性能损耗,但是随着数据量的增长这个差距在减小(标记c)。
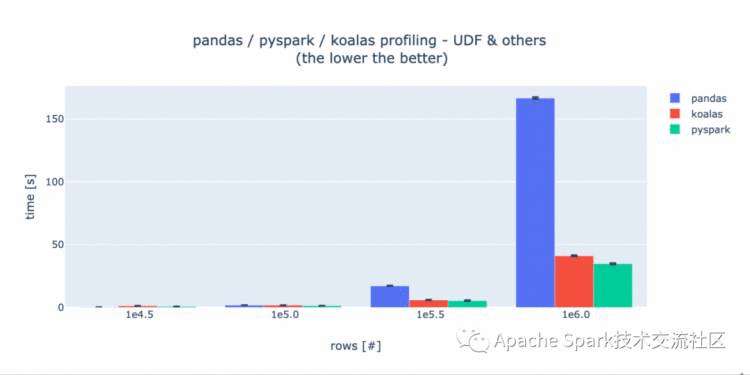
在UDF的评测中,PySpark和Koalas文档当中描述了使用UDF会带来性能的大幅下降,所以我们将测试数据的行数减少了100倍。在每个测试用例中,Koalas和PySpark具有相同的性能,这暗示着他们使用了相同的底层实现。在实验过程中,我们发现使用PySpark windows功能性能会得到提升,但是Koalas没有此实现,所以我们仅测试UDF。
如果你想使你的pandas代码能够具有处理更大数据量和水平扩展的能力,那么Koalas将是一个正确的选择。当快速切换到Koalas上后你可以通过调整你的Spark集群的规模来处理更大的数据量并且显而易见的缩短处理时间。而且性能和PySpark差不多(根据集群规模和数据量的规模,有5%到50%的损失)。
另一方面,Koalas API相对于原生的Spark有一些损耗。如果你对性能非常敏感,你可以考虑使用Scala来实现你的处理逻辑。
当你刚开始接触Koalas的时候,你需要知道“为什么这个没有实现?!” 当前Koalas的包仍然在开发过程中,并且有些pandas API没有实现,但是大多数目前没有的功能会在接下来的几个月中实现(比如说groupby.diff()
或者kdf.rename()
)
根据我作为这个项目的contributor的经验,有些功能使用Spark API实现起来过于复杂或者有较大性能损耗。比如:DataFrame.values
需要在单一节点的内存中处理整个数据集,所以这是不太合适甚至是不太可能的。取而代之如果你需要在driver中检索结果,你可以调用DataFrame.to_pandas()
或者DataFrame.to_numpy()
另外一个重要的事情是Koalas的执行链和pandas是不同的:当在dataframe上面执行一些操作,会将操作放入一个队列当中,只有需要results的时候才会真正执行完毕。比如:当调用kdf.head()
或者kdf.to_pandas()
操作的时候才会被真正执行。这可能会对一些没有使用过Spark的人造成困扰,因为pandas是按照一行一行来具体执行的。
Koalas帮助我们快速的讲pandas代码迁移到Spark上。如果你在尝试扩展你的pandas代码,你可以尝试使用Koalas。如果你遇到某些问题或者需要更多的功能,你可以提issue https://github.com/databricks/koalas/issues 给社区,我们将保障Koalas的活跃度并不断的改进。另外的,欢迎来一起贡献代码。
Koalas github: https://github.com/databricks/koalas
Koalas documentation: https://koalas.readthedocs.io
文章中的代码: https://gist.github.com/patryk-oleniuk/043f97ae9c405cbd13b6977e7e6d6fbc .
原文链接:https://databricks.com/blog/2019/08/22/guest-blog-how-virgin-hyperloop-one-reduced-processing-time-from-hours-to-minutes-with-koalas.html







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有