特征:数据中抽取出来的结果预测有用的信息
特征的个数就是数据的观测维度。
特征工程时使用专业北京知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
特征工程一般暴扣特征清洗(采样,清洗一场样本),特征处理和特征选择
特征按照不同的数据类型分类,有不同的特征处理方法
----数值型
用连续数值表示当前维度特征,通常会对数值型特征进行数学上的处理,主要的做法是归一化和离散化
归一化也称幅度调整
特征与特征之间应该是平等的,区别应该体现在特征内部,
例如:房屋价格和房屋面积的幅度是不同的,价格一般在万级别,而面积应该在百级别,那么明明平等的两个特征,输入到相同的模型中后由于本身的幅值不同而导致产生的效果不同,这是不合理的
那么对于这种情况,应该把数值归一化:

离散化:
第一种:等步长,
例如:年龄段,每隔十岁一个等级,0-10,10-20,20-30,,,,,
第二种:等频
例如:min -> 25% -> 75% -> max
京东上选商品时候的价格区间,这个是按照那个区间物品密集就在那个密集细分下,
例如:手机可能在1500-3500这个之间会多点 而在5000以上相对比会少点
所以价位应该设置为0-25%,25-30%,30-35%,35%-50%,,,,
两种方法对比:
等频的离散方法很准确,但是需要每次对数据分布从新计算一遍,因为昨天用户在淘宝上买东西的价位分布和今天不一定相同,因此昨天做的等频的切分点可能并不适用,而线上最需要避免的就是不固定,需要现场计算,所以昨天训练出的模型今天不一定能使用
等频不固定,但很准确,等步长是固定的,非常简单,因此两者在工业上都有应用
----类别型
类别型数据本身没有大小关系,需要将他们编码为数字,但是他们之间不能有预先设定的大小关系,因此既要做到公平,又要区分他们,那么直接开辟多个空间,
One-Hot 编码/哑变量
One-Hot 编码所做的就是及那个类别数据平行地展开,也就是说,经过One-Hot编码后,这个特征的空间膨胀,
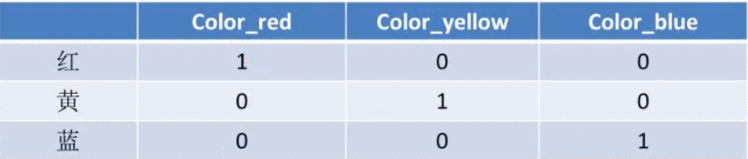
例如:一个特征为颜色,这是红黄蓝绿这个用数字怎么表示呢???
用One-Hot编码:
红 1000
黄 0100
蓝 0010
绿 0001
----时间型
时间型特征既可以做连续值,又可以看作离散值
连续值:
持续时间(网页游览时长)
间隔时间(上一次购买/点击离现在的时间间隔)
离散值
一天种那个时间端
一周中的星期几
一年中那个月
工作日/周末
----统计型
加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少
分位线:商品属于售出商品价位的分位线处
次序性:商品处于热门商品第几位
比例类:电商中商品的好中差比例








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 