1. 概述
和搜索引擎一样,推荐系统是为了帮助人们更快速的获得对自己有用的信息。
和搜索引擎不同,推荐系统是人们被动的获取,由系统根据用户行为或其他的信息推荐给用户的,儿搜索引擎是用户主动输入关键字获取的。
从某种意义上说,搜索引擎和推荐系统是互相补充的。
而推荐算法的本质是通过一定的方式将用户和物品联系起来,从而有效的给用户推荐本身感兴趣或需要但是没有发现的物品。
个性化推荐系统的应用场景:电子商务(据说Amazon 35%的销售额来自推荐系统)、电影和视频网站、个性化音乐网络电台、社交网络、个性化阅读、基于位置的服务、个性化邮件、个性化广告(上下文广告、搜索广告、个性化展示广告)。
一个推荐系统的评判标准:用户满意度、预测准确度、覆盖率、多样性、新颖性、惊喜度、信任度、实时性、健壮性、商业目标。
2. 主要推荐系统算法
基于邻域的方法、隐语义模型、基于图的随机游走算法。在这些方法中,最著名、在业界得到最广泛应用的算法是基于邻域的方法。
基于邻域的方法主要包括:基于用户的协同过滤算法(给用户推荐和他兴趣相似的其他用户喜欢的物品)和基于物品的协同过滤算法(给用户推荐和该用户喜欢的物品属性类似的其他物品)
下面主要说明一下第一种算法
基于用户的协同过滤算法
该算法的主要步骤:1、找到与该用户兴趣相似的用户集;2、找到这个集合中的用户喜欢的但是没有听说过的物品推荐给目标用户。
第一步:计算用户的兴趣相似度
可以通过以下公式计算:
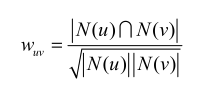
其中u,v表示两个用户,N(u)表示用户u曾经有过正反馈的物品集合;N(v)表示用户v曾经有过正反馈的物品集合。
算法的Python实现如下:
def User_Similarity(train):W=dict()for u in train.keys():for v in train.keys():if u == v: continue; W[u][v] = len(train[u],train[v])W[u][v] /= math.sqrt(len(train[u]) * len(train[v]) * 1.0)
可以发现该代码的时间复杂度是O(n*n),并且大多数用户的兴趣相似度可能位0,即|N(u)∩N(v)| = 0,所以该代码还是可以优化的。
我们可以先计算出|N(u)∩N(v)| ≠ 0的用户对(u,v)然后除以余弦相似度。这里可以使用倒排,将数据排列成物品到用户的倒排表,物品后链接的是与对该物品感兴趣的用户链表,然后循环统计每个物品用户链表的用户相似度即可。
算法的Python代码如下:
#!/usr/bin/env python
# coding=utf-8
def UserSimilarity(train):#建立倒排表item_users = dict()for u,items in train.items():for i in item.keys():if i not in item_users:items_users[i] = set()item_users[i].add(u)#item_users即为物品到用户的倒排表#计算用户之间的相关度C = dict()#任意用户之间的相关度N = dict()#用户正反馈物品的数目for i ,users in item_users:for u in users:N[u] += 1for v in users:if u == v:continue:C[u][v] += 1#最后计算结果矩阵W = dict()for u ,related_users in C.items():for v,cuv in related_users:W[u][v] = cuv / math.sqrt(N[u]* N[v]*1.0)
return W
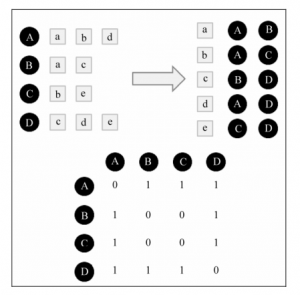
物品-用户倒排表
第二步:推荐和他相似的K个用户喜欢的物品
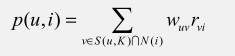
其中:p(u,i)用户u对物品i的兴趣度;
S(u,K)包含和用户u兴趣最相近的K的用户;
Wuv用户u和用户v的兴趣相似度;
Rvi用户v对物品i的兴趣度;
算法的Python代码实现:
def Recommend(user,train,W):rank = dict()interacted_items = train[user]for v , wuv in sort(W[u].items,key = itemgetter(1),reverse = True)[0:k]:for i ,rvi in train[v].items:if i in interacted_items:continuerank[i] += wuv * rvireturn rank



 京公网安备 11010802041100号
京公网安备 11010802041100号