作者:如痴如醉as_961 | 来源:互联网 | 2023-09-08 18:55
在大多数时候,你是没有足够的图像来训练深度神经网络的。本文将教你如何从小样本数据快速学习你的模型。 为什么我们关心小样本学习?1980年,KunihikoFukushima提出了

在大多数时候,你是没有足够的图像来训练深度神经网络的。本文将教你如何从小样本数据快速学习你的模型。
1980年, Kunihiko Fukushima 提出了第一个卷积神经网络。从那时起,由于计算能力的不断提高和机器学习社区的巨大努力,深度学习算法在与计算机视觉相关的任务上从未停止过提高它们的性能。2015年,何凯明和他在微软的团队报告说,他们的模型在对来自 ImageNet 的图像进行分类时表现优于人类。在那时候,有人可能会说,计算机在利用数十亿图像来解决特定任务方面变得比我们更强。欢呼!
然而,如果你不是 Google 或者 Facebook,你就不可能总是能够用这么多的图像来构建一个数据集。当您从事计算机视觉工作时,有时您必须对每个标签只有一个或两个样本的图像进行分类。在这场比赛中,人类仍将被打败。给婴儿看一张大象的照片,从现在起他们永远不会认不出大象。如果你对 Resnet50 做同样的事情,你可能会对结果感到失望。从少数的样本中学习的这个问题,被称为小样本学习(few-shot learning)。
近几年来,小样本学习的问题引起了研究界的广泛关注,并形成了许多优雅的解决方案。目前最流行的解决方案是使用元学习(meta-learning),又称为:learning to learn。如果你想知道它是什么,以及它是如何用于小样本图像分类,请继续阅读。
极少样本的分类任务
首先,我们需要定义N个类别,K张图片(译者注:针对每个类别)的分类任务。假设以下的场景:
1. 一个支持数据集,包含N个分类标签,针对每个标签有K个已分类的图片。
2. 一个查询数据集,包含Q张查询图片。
任务是利用支持数据集中的N*K个图片,将查询数据集中的图片分类为N个类别(译者注:可以理解为训练集有N*K个图片,将测试集在N个类别进行分类)。当K值很小时(通常K<10),我们称这种分类任务为极少样本分类任务(当K=1时,变成单样本分类任务)
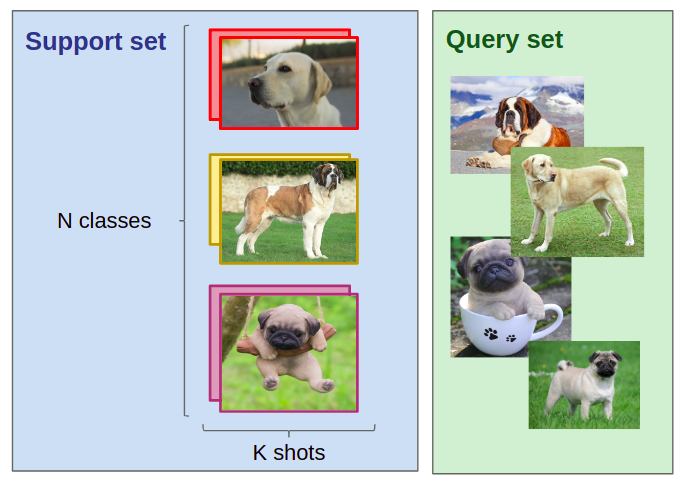
极少样本分类任务的一个例子:在支持集中,给定N=3(3类),每类K=2,即每种类别两张图片,我们希望将查询集中(查询集Q=4,即4张查询图片)的狗标注为拉普拉多狗,圣伯纳德狗或哈巴狗。即使你从未见过任何的哈巴狗、圣伯纳德狗或拉普拉多狗,这项任务对你来说也不困难。但使用AI来解决这个问题,我们需要进行一些元学习。
元学习范例
1998年,Thrun和Pratt指出,对于一个指定的任务,一个算法“如果随着经验的增长,在该任务上的表现得到改进”,则认为该算法能够学习。与此同时,与此同时,对于一族待解决的多个任务,一个算法“如果随着经验和任务数量的增长,在每个任务上的表现得到改进”,则认为该算法能够学习如何学习,我们将后者称为元学习算法。它不学习如何解决一个特定的问题,但可以成功学习如何解决多个任务。每当它学会解决一个新的任务,它就越有能力解决其他新的任务:它学会如何学习。
如果我们希望解决一项任务T,会在一批训练任务{Ti}上训练元学习算法。算法在被训练解决这些任务的过程中得到的经验将被用于解决最终的任务T。
比如,考虑上个图像中提到的任务T。它的目标是通过使用3x2=6张已标记的同品种狗的图片,来识别(新的)图片是属于拉普拉多狗,圣伯纳德狗或哈巴狗。训练任务{Ti}中的某一项任务Ti可以是通过使用3x2=6的已标记的同品种狗图片中获取信息,将新图片标记为拳师狗、圣伯纳德狗或洛特维勒牧狗。元学习过程就是由一系列这样的每一次针对不同品种的狗的训练任务Ti所组成的。我们希望元学习模型“随着经验和任务数量的增长”得到不断地改进。最终,我们在T任务上评估模型。
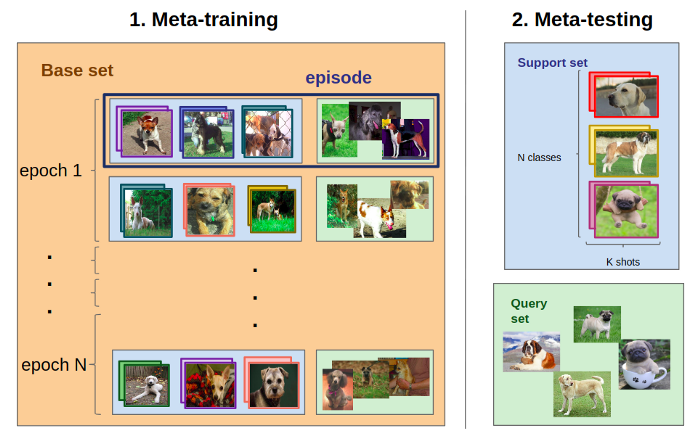
我们评估了拉布拉多犬、圣伯纳德犬和八哥的元学习模型,但我们只是在其他所有品种上进行训练。
现在我们该怎么做?假设你想解决任务T(里面有拉布拉多,圣伯纳德和 八哥),那么你需要一个元训练数据集,里面有很多不同品种的狗。 你可以使用 Stanford Dogs 数据集(http://vision.stanford.edu/aditya86/ImageNetDogs),其中包含从ImageNet中提取的超过20k 只狗。我们将把这个数据集命名为D。注意,这个过程不需要包含任何拉布拉多、圣伯纳德或八哥。
我们从D中采样了一批(如下),每集对应于一个 N-way K-shot 分类任务 Tᵢ 类似T(通常我们使用相同的N和K)。 模型解决了每一集(即标记了每一个查询集的图像)后,它的参数会更新,这通常是通过对查询集的分类不准确造成的损失进行反向跟踪来实现的。
这样,模型就可以跨任务学习准确地解决一个新的、不可见的少镜头分类任务。 标准的学习分类算法学习映射图像→标签,元学习算法通常学习映射支持集→c(.),其中c是映射查询→标签。
元学习算法
既然我们知道了算法元训练的含义,那么还有一个谜团:元学习模型是如何解决一个少镜头分类任务的?当然,解决方案不止一个。在这里,我们将关注最受欢迎的方案。
度量学习
度量学习的基本思想是学习数据点(如图像)之间的距离函数。事实证明,它对于解决少样本分类任务非常有用:度量学习算法不必在支持集(少量的带标签图像)上进行微调,而是通过将查询图像与带标签图像进行比较来对其进行分类。
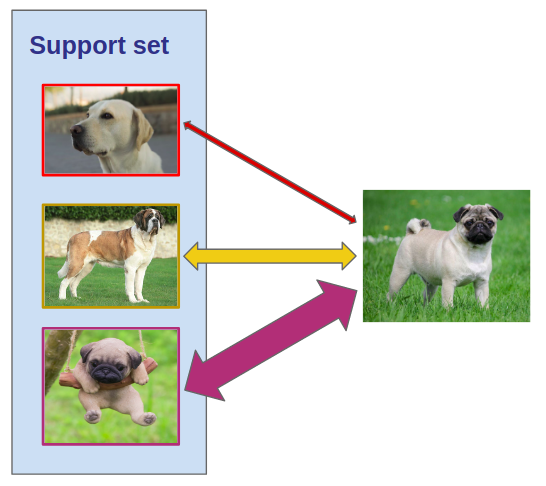
将查询图像(在右侧)与支持集的每个图像进行比较,它的标签取决于与其最接近的图像。当然,你不能逐个像素地比较图像,你要做的是在相关的特征空间中比较图像。为了清楚起见,让我们详细说明度量学习算法是如何解决少样本分类任务的(上面定义为带标签样本的支持集,以及我们要分类的查询图像集):
-
我们从支持集和查询集的所有图像中提取特征(通常使用卷积神经网络)。现在,我们在少样本分类任务中必须考虑的每个图像都由一个一维向量表示。
-
每个查询图像根据其与支持集图像的距离进行分类。对于距离函数和分类策略,可以有许多可能的设计选择。例如,欧氏距离和k-最近邻分类。
-
在元训练期间,在每一场景(episode)结束时,对由查询集的分类错误产生的损失值(通常是交叉熵损失)进行反向传播,从而更新CNN的参数。
每年都会提出几种度量学习算法来解决少样本图像分类问题,这其中的两个原因是:
-
他们凭经验可以做得很好;
-
唯一的限制就是你的想象力。有很多方法可以提取特性,甚至还有更多方法可以比较这些特性。我们现在将介绍一些现有的解决方案。
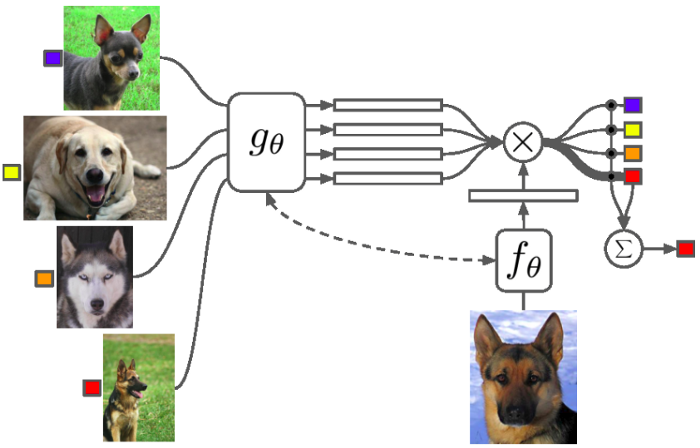
匹配网络算法。对于支持集图像(左)和查询图像(底部),特征提取器是不同的。使用余弦相似性,将查询的嵌入特征与支持集中的每个图像进行比较。然后用softmax进行分类。上图来自Oriol等。
匹配网络(见上文)是第一个使用元学习的度量学习算法。在这个方法中,我们不会以同样的方式提取支持图像和查询图像的特征。来自 Google DeepMind 的Oriol Vinyals和他的团队有一个想法,即在特征提取过程中使用LSTM网络使所有图像交互。他们称之为完全上下文嵌入,因为你允许网络找到最合适的嵌入,这不仅知道要嵌入的图像,还知道支持集中的所有其他图像。这使得他们的模型比所有的图像都通过一个简单的CNN时表现得更好,但它也需要更多的时间和更大的GPU。
在最近的工作中,我们不会将查询图像与支持集中的每个图像进行比较。多伦多大学的研究人员提出了原型网络。在他们的度量学习算法中,从图像中提取特征后,我们为每个类计算一个原型。为此,他们使用类中每个图像嵌入的平均值。(但是你可以想出成千上万的方法来计算这些嵌入。为了反向传播,函数只需要是可微的。)一旦计算出原型,就可以计算查询图像到原型的欧式距离,从而对查询图像进行分类(见下图)。
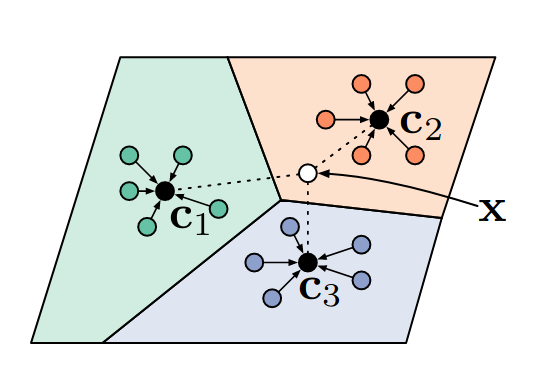
在原型网络中,我们将查询X标记为与其最接近的原型的标签。
尽管简单,但原型网络仍然可以产生最好的结果。更复杂的度量学习架构后来被开发出来,比如用神经网络来表示距离函数(而不是欧几里得距离)。这略微提高了准确性,但我相信到目前为止,原型理念在少样本图像分类的度量学习算法领域是最有价值的想法(如果你不同意,请留下评论)。
模型无关的元学习
我们将以模型无关的元学习(MAML)结束这篇综述,MAML是目前最优雅和最有潜力的元学习算法之一。它基本上是最纯粹的元学习形式,通过神经网络进行两级反向传播。
该算法的核心思想是训练一个神经网络,使其能够仅用少量样本就能快速适应新的分类任务。下图将展示MAML如何在元训练的一个场景(即,从数据集D中采样得到的少样本分类任务Tᵢ)中工作的。假设你有一个用?参数化的神经网络M:
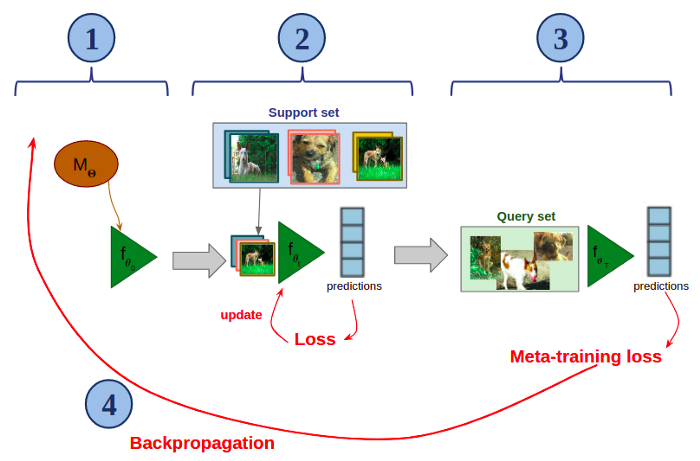
用?参数化的MAML模型的元训练步骤:
-
创建M的副本(此处命名为f),并用?对其进行初始化(在图中,?₀=?)。
-
快速微调支持集上的f(只有少量梯度下降)。
-
在查询集上应用微调过的f。
-
在整个过程中,对分类错误造成的损失进行反向传播,并更新?。
然后,在下一场景中,我们创建一个更新后模型M的副本,我们在新的少样本分类任务上运行该过程,依此类推。
在元训练期间,MAML学习初始化参数,这些参数允许模型快速有效地适应新的少样本任务,其中这个任务有着新的、未知的类别。
公平地说,MAML目前在流行的少样本图像分类基准测试中的效果不如度量学习算法。由于训练分为两个层次,模型的训练难度很大,因此超参数搜索更为复杂。此外,元的反向传播意味着需要计算梯度的梯度,因此你必须使用近似值来在标准GPU上进行训练。出于这些原因,你可能更愿意在家里或工作中为你的项目使用度量学习算法。
但是,模型无关的元学习之所以如此令人兴奋,是因为它的模型是不可知的。这意味着它几乎可以应用于任何神经网络,适用于任何任务。掌握MAML意味着只需少量样本就能够训练任何神经网络以快速适应新的任务。MAML的作者Chelsea Finn和Sergey Levine将其应用于有监督的少样本分类,监督回归和强化学习。但是通过想象和努力研究,你可以用它把任何一个神经网络转换成少样本有效的神经网络!
这就是这次在元学习这个令人兴奋的世界里的旅行。少样本学习最近引起了计算机视觉研究的广泛关注,因此该领域的发展非常迅速(如果你在2020年阅读这篇文章,我建议你寻找更新的信息来源)。谁知道未来几年,神经网络会变得有多好,是否能一眼就学习到视觉概念?
via https://blog.sicara.com/meta-learning-for-few-shot-computer-vision-1a2655ac0f3a
点击【图像样本不够用?元学习帮你解决】即可访问相关内容和参考文献!
今日资源推荐:资料 | Python学习材料(基础+进阶+考试+答案)
包含以下内容:
点击链接获取:https://ai.yanxishe.com/page/resourceDetail/535
雷锋网雷锋网雷锋网(公众号:雷锋网)
。








 京公网安备 11010802041100号
京公网安备 11010802041100号