GitHub - NVlabs/GCVit: Official PyTorch implementation of Global Context Vision TransformersOfficial PyTorch implementation of Global Context Vision Transformers - GitHub - NVlabs/GCVit: Official PyTorch implementation of Global Context Vision Transformershttps://github.com/NVlabs/GCViT
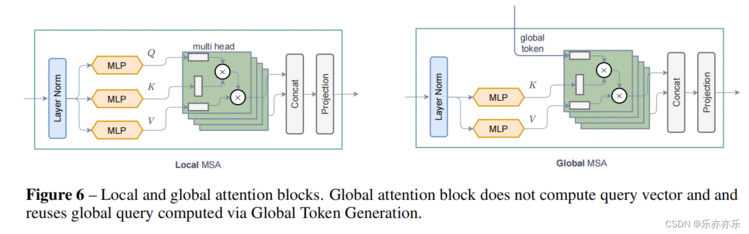
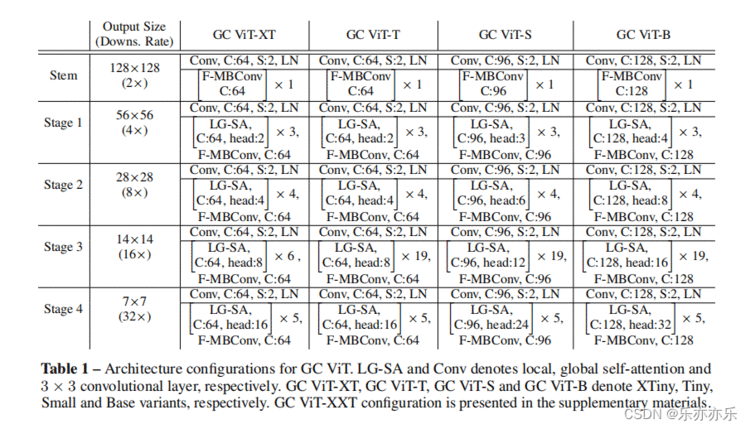
首先输入图像的分辨率为H X W X 3 ,通过应用一个3×3的卷积层和适当的填充来获得重叠(overlapping)的patch。然后将patch投影到C维嵌入空间中。每个GCViT阶段都由交替的局部和全局自注意模块组成,以提取空间特征。两者都在像Swin Transformer 这样的 local windows 中运行,然而,全局自注意访问 Global Toke Generator (GTG)提取的全局特征。GTG是一个类似于cnn的模块,它在每个阶段只从整个图像中提取一次特征。每个阶段后增加一个下采样模块,空间分辨率减少一半。生成的特征通过平均池化和线性层传递,以为下游任务创建嵌入。
 https://arxiv.org/abs/2206.09959
https://arxiv.org/abs/2206.09959 https://github.com/NVlabs/GCViT
https://github.com/NVlabs/GCViT







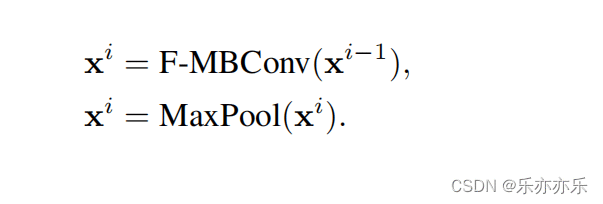









 京公网安备 11010802041100号
京公网安备 11010802041100号