作者:香香画室_769 | 来源:互联网 | 2023-08-14 11:35
目录一、数据统计量描述1、集中度描述1.1均值1.2众数1.3中位数2、离散度描述2.1极差2.2方差2.3标准差2.4变异系数2.5贝塞尔校正二、数据处理工具1、EXCEL函数2
目录 一、数据统计量描述 1、集中度描述 2、离散度描述 2.1 极差 2.2 方差 2.3 标准差 2.4 变异系数 2.5 贝塞尔校正 二、数据处理工具 1、EXCEL 函数 2、EXCEL描述统计 3、SQL 4、R语言 5、Python
一、数据统计量描述 1、集中度描述 1.1 均值 1)描述
1.2 众数 一组数据中出现次数最多的数字,可能不止一个,可能没有。适用于当数据具有明显集中趋势的情况。
1.3 中位数 一组数据从小到大排列,位于中间的数据,其中偶数个数的数据为中间两个数据的算术平均,缺点是数据不敏感。
2、离散度描述 2.1 极差 最大值-最小值,反应一组数据的范围大小,极差越大越分散。
2.2 方差 1)描述
2.3 标准差 1)描述
2.4 变异系数 1)变异系数 = 标准偏差/平均数。
2.5 贝塞尔校正 在类似正态分布中,样本围绕在均值附近,抽取到边缘值的概率较小,样本值会偏向集中,因此计算出来的样本方差会较小,如果以此来估计整体方差时,需要进行适当放大,即除数修正为N-1。
二、数据处理工具 根据总体样本的大小进行处理的工具有多种,一般数据量级较少时采用EXCEL即可满足需求,数量级较大时(百万级别以上)一般采用SQL、R、python进行处理,须知方法只是作为满足需求的处理工具,一切以满足需要的便捷性出发,无需拘泥于工具本身。
1、EXCEL 函数 1.1、说明
2、EXCEL描述统计 1)功能开启
功能开启:文件 -》选项 -》加载项 -》转到 -》分析工具库
3、SQL 3.1、说明
4、R语言 4.1、说明
< - c ( 1 , 2 , 3 , 4 &#xff0c;4 , 5 ) #中位数mean ( array) #众数< - unique ( array) < - tabulate ( match ( array, mode) ) [ index &#61;&#61; max ( index) ] #中位数median ( array) #极差max ( array) - min ( array) #方差var ( array) #标准差sd ( array) #变异系数sd ( array) / mean ( array)
5、Python 5.1、说明
numpy库说明&#xff1a;
Scipy是世界上著名的Python开源科学计算库&#xff0c;建立在Numpy之上。它增加的功能包括数值积分、最优化、统计和一些专用函数。 SciPy函数库在NumPy库的基础上增加了众多的数学、科学以及工程计算中常用的库函数。例如线性代数、常微分方程数值求解、信号处理、图像处理、稀疏矩阵等等。
import numpy as npimport stats array &#61; [ 1 , 2 , 3 , 4 , 4 , 5 ] #平均数print ( "平均数" &#43; np. mean ( array) ) #众数print ( "众数" &#43; stats. mode ( array) [ 0 ] [ 0 ] ) #中位数print ( "中位数" &#43; np. median ( array) ) #极差print ( "极差" &#43; ( np. max ( array) - np. min ( array) ) ) #方差print ( "方差" &#43; np. var ( array) ) #变异系数print ( "变异系数" &#43; np. std ( array) / np. mean ( array) ) #标准差print ( "标准差" &#43; np. std ( array) )
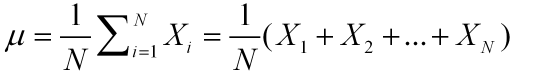

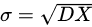
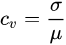











 京公网安备 11010802041100号
京公网安备 11010802041100号