作者:mengziwudao | 来源:互联网 | 2024-11-16 15:34
作者
digoal
日期
2017-08-25
标签
PostgreSQL, GIS, PostGIS, Greenplum, 空间检索, GiST, B-Tree, geohash
背景
GiST(Generalized Search Tree)索引是一种支持多种数据类型和操作符类的通用索引方法。本文探讨了GiST索引在空间数据检索中的具体实现和优化策略。
本文是对以下两篇文档的补充:
- 《Greenplum 空间(GIS)数据检索 B-Tree & GiST 索引实践 - 阿里云HybridDB for PostgreSQL最佳实践》
- 《PostGIS空间索引(GiST、BRIN、R-Tree)选择、优化 - 阿里云RDS PostgreSQL最佳实践》
GiST索引的构造
GiST索引可以通过空间思维来理解。例如,在数据规整方面,通过减少每个堆块(heap block)的边界框(bounding box)大小,并使不同堆块之间的边界更加清晰,可以提高空间数据检索的效率。
GiST索引采用R-Tree结构来实现这一点,使得在插入数据时,空间对象能够明确地分配到相应的索引分支。随着数据的不断写入,GiST索引可能会出现分裂(split)的情况。
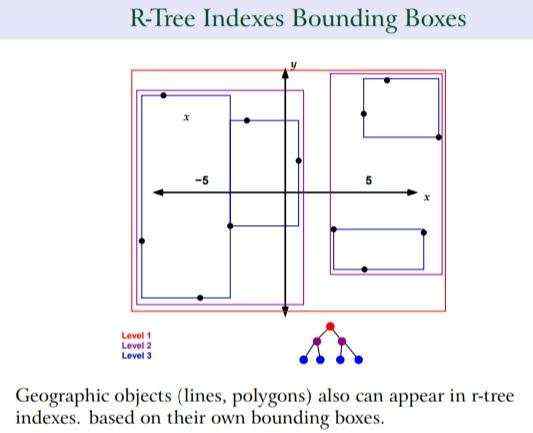
GiST索引对写入性能的影响
以下是创建和插入大量空间数据时,GiST索引对写入性能的影响测试:
postgres=# create unlogged table test_gist (pos geometry);
CREATE TABLE
postgres=# create index idx_test_gist_1 on test_gist using gist (pos);
CREATE INDEX
postgres=# insert into test_gist select st_setsrid(st_makepoint(random()*360-180, random()*180-90), 4326) from generate_series(1,5000000);
INSERT 0 5000000
Time: 67127.758 ms
postgres=# drop index idx_test_gist_1 ;
DROP INDEX
Time: 1056.465 ms
postgres=# create index idx_test_gist_1 on test_gist using gist (pos);
CREATE INDEX
Time: 58945.677 ms
B-Tree索引对写入性能的影响
以下是创建和插入大量空间数据时,B-Tree索引对写入性能的影响测试:
postgres=# create unlogged table test_btree (pos geometry);
CREATE TABLE
postgres=# create index idx_test_btree_1 on test_btree using btree(st_geohash(pos,11));
CREATE INDEX
postgres=# insert into test_btree select st_setsrid(st_makepoint(random()*360-180, random()*180-90), 4326) from generate_series(1,5000000);
INSERT 0 5000000
Time: 30199.098 ms
postgres=# drop index idx_test_btree_1 ;
DROP INDEX
Time: 50.565 ms
postgres=# create index idx_test_btree_1 on test_btree using btree(st_geohash(pos,11));
CREATE INDEX
Time: 7746.942 ms
BRIN索引对写入性能的影响
以下是创建和插入大量空间数据时,BRIN索引对写入性能的影响测试:
postgres=# create unlogged table test_brin (pos geometry);
CREATE TABLE
postgres=# create index idx_test_brin_1 on test_brin using brin(pos);
CREATE INDEX
postgres=# insert into test_brin select st_setsrid(st_makepoint(random()*360-180, random()*180-90), 4326) from generate_series(1,5000000);
INSERT 0 5000000
Time: 7476.996 ms
postgres=# drop index idx_test_brin_1 ;
DROP INDEX
Time: 1.604 ms
postgres=# create index idx_test_brin_1 on test_brin using brin(pos);
CREATE INDEX
Time: 1697.741 ms
GiST索引的通用性
GiST不仅支持空间数据类型,还支持其他复杂的数据类型,如SP-GiST索引。这种通用性使其成为处理多种数据类型的强大工具。
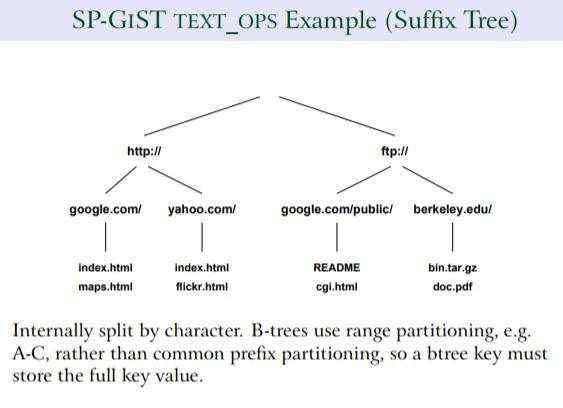
小结
GiST索引直接构建在空间列上,对性能影响较大。B-Tree索引通过表达式(st_geohash)构建,对性能影响较小。BRIN索引直接构建在空间列上,对性能影响最小。
参考
- 《Greenplum 空间(GIS)数据检索 B-Tree & GiST 索引实践 - 阿里云HybridDB for PostgreSQL最佳实践》
- 《PostGIS空间索引(GiST、BRIN、R-Tree)选择、优化 - 阿里云RDS PostgreSQL最佳实践》
- Flexible Indexing with Postgres
PostgreSQL 许愿链接
您的愿望将传达给PG内核开发者、数据库厂商等,帮助提高数据库产品的质量和功能。针对非常好的提议,将提供限量版PG文化衫、纪念品、贴纸、PG热门书籍等奖励。快来许愿吧!
9.9元购买3个月阿里云RDS PostgreSQL实例
PostgreSQL 解决方案集合
德哥 / digoal's github - 公益是一辈子的事.








 京公网安备 11010802041100号
京公网安备 11010802041100号