点击左上方蓝字关注我们

本栏目由百度飞桨工程师联手精心打造,对深度学习的知识点进行由浅入深的剖析和讲解。大家可视它为深度学习百科(面试秘籍也是可以哒),当然也可收藏为深度学习查询手册~
大家好,我是助教唐僧。在上期中,主桨人见见为大家讲解了卷积的批量计算以及应用案例,后续还有详解卷积变体的课程,见见老师还在努力开发中,希望大家期待一下。
本期由主桨人步步高为大家带来内容:优化器及其三种形式BGD、SGD以及MBGD。

1.什么是优化器?
假如我们定义了一个机器学习模型,就希望这个模型能够尽可能拟合所有训练数据。如何评价模型对数据的拟合程度呢?使用的评估指标称为损失函数(Loss Function),当损失函数值下降,我们就认为模型在拟合的路上又前进了一步。模型对指定训练集拟合的最好的情况就是在损失函数的平均值最小的时候。为了让损失函数的数值下降,需要使用优化算法进行优化,称为梯度下降法。
优化器(例如梯度下降法)就是在深度学习反向传播过程中,指引损失函数的各个参数往正确的方向更新合适的值,使得更新后的各个参数让损失函数的值不断逼近全局最小。
2.优化器的原理
优化器的原理其实很简单,给大家讲一个故事。周末我去爬山,下山时,我想找一条相对容易的路。因此,我首先环顾四周,找到下山最快的方向走一步,然后再次环顾四周,找到最快的方向又走了一步,循环往复,直到我走到山脚。听起来是不是很简单,这就是优化器——标准的梯度下降法。其中,我们下山时每一步走出的方向,在优化器中反映为梯度或者动量,而我们下山迈多大的步伐在优化器中则反映为学习率。所有优化器都在关注这两个方面,但同时也有一些其他问题,比如应该在哪个位置出发、路线错误如何处理……这是一些最新的优化器关注的方向。

3.梯度下降法的作用
梯度下降是机器学习中常见优化算法之一,梯度下降法有以下几个作用:
(1)梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以),其他的问题,只要损失函数可导也可以使用梯度下降,比如交叉熵损失等等。
(2)在求解机器学习算法的模型参数,即无约束优化问题时,主要有梯度下降法,牛顿法等。
(3)在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
(4)如果我们需要求解损失函数的最大值,可通过梯度上升法来迭代。梯度下降法和梯度上升法可相互转换。
4.梯度下降的三种形式
常用的梯度下降法有三种不同的形式,即批量梯度下降BGD,随机梯度下降SGD,Mini-batch梯度下降MBGD。
4.1批量梯度下降BGD
批量梯度下降(BGD)是梯度下降法最原始的形式,其原理是更新每一个参数时都使用所有的样本来进行更新,即在整个训练集上计算损失函数关于参数θ的梯度。其思想可以理解为在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山。
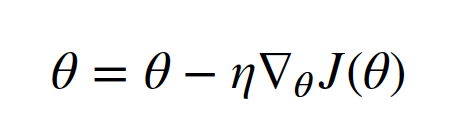
其中θ是模型的参数,η是学习率,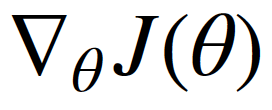 为损失函数对参数θ的导数。
为损失函数对参数θ的导数。
4.1.1 BGD有哪些优点?
BGD迭代次数相对较少,在凸函数上能保证收敛到全局最优点。
4.1.2 BGD面临的问题
由于为了一次参数更新,需要在整个训练集上计算梯度,导致计算量大,迭代速度慢,而且在训练集太大不能全部载入内存的时候会很棘手。
4.2随机梯度下降SGD
随机梯度下降(SGD)则是每次使用一个训练样本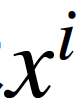 和标签
和标签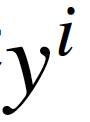 进行一次参数更新。基本策略可以理解为一个盲人下山,虽然过程显得扭扭曲曲,但是他总能下到山底。
进行一次参数更新。基本策略可以理解为一个盲人下山,虽然过程显得扭扭曲曲,但是他总能下到山底。
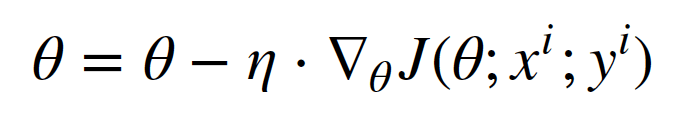
其中θ是模型的参数,η是学习率,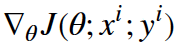 为损失函数对参数θ的导数。
为损失函数对参数θ的导数。
4.2.1 SGD有哪些优点?
BGD 对于大数据集来说执行了很多冗余的计算,而SGD 每次只使用一个训练样本进行参数更新,从而解决了这种冗余,因此通常 SGD 的速度会非常快。
4.2.2 SGD面临的问题
SGD以高方差的特点进行连续参数更新,其损失函数严重震荡,如图1所示。
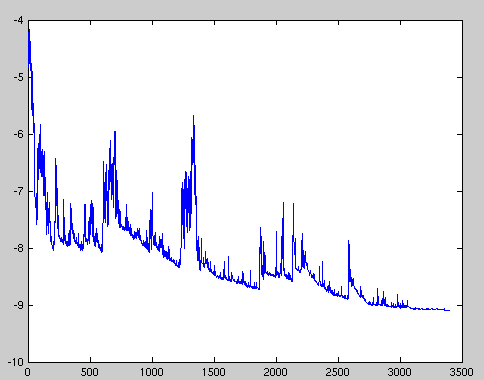
图1 SGD损失函数
此外,SGD的另一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
4.3Mini-batch梯度下降MBGD
Mini-batch 梯度下降(MBGD)是对上述两种策略进行折中,每次从训练集中取出batch size个样本作为一个mini-batch,以此来进行一次参数更新。
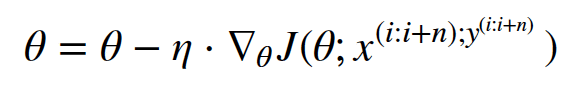
其中θ是模型的参数,η是学习率,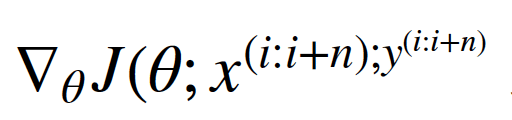 为损失函数对参数θ的导数,n为Mini-batch的大小(batch size)。
为损失函数对参数θ的导数,n为Mini-batch的大小(batch size)。
注:batch size越大,批次越少,训练时间会更快一点,但可能造成数据浪费;而batch size越小,对数据的利用越充分,浪费的数据量越少,但批次会很大,训练会更耗时。
4.3.1 MBGD有哪些优点?
样本数目较大时,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的n次方,代码会运行地快一些。例如64就是2的6次方,以此类推,128是2的7次方,256是2的8次方,512是2的9次方。我们通常把mini-batch大小设成2的次方,大小为64到512 。
4.3.2 MBGD面临的问题学习率设置
学习率设置
选择一个好的学习率非常困难。太小的学习率导致收敛非常ii缓慢,而太大的学习率则会阻碍收敛,导致损失函数在最优点附近震荡甚至发散。
当数据比较稀疏,特征频率不同时,此时我们并不想要以相同的学习率更新所有的参数。此时我们可以选择这样的方案,即在学习期间提前定义好一个规则自动调节学习率,或者两次迭代之间,损失函数的改变低于一个阈值时自动调节学习率。然而这些规则和阈值也是需要在训练前定义好的,所以也不能做到自适应数据的特点。
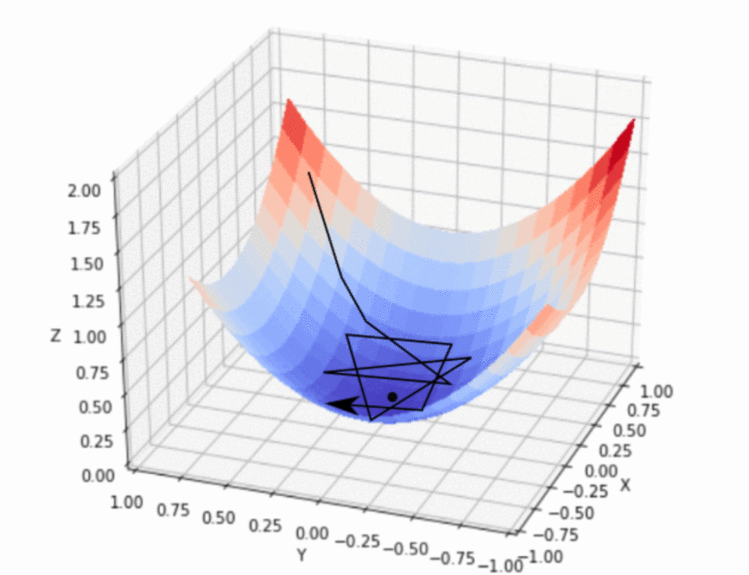
图2 学习率过大示意图
如图2所示,学习率设置过大,导致损失函数值沿着 “山谷” 周围大幅震荡,可能永远都到达不了最小值。
鞍点的出现
如图3,鞍点得名于它的形状类似于马鞍,鞍点通常被一个具有相同误差的平面所包围。对于神经网络来说,另一个关键挑战是避免陷入鞍点,即损失函数在该点的一个维度上是上坡,而在另一个维度上是下坡。尽管它在 x 方向上是一个最小值点,但是它在另一个方向上是局部最大值点,这使得对于 SGD 来说非常难于逃脱,因为在各个维度上梯度都趋近于 0。如果它沿着 x 方向变得更平坦的话,梯度下降会在 x 轴振荡并且不能继续根据 y 轴下降,这就会给我们一种已经收敛到最小值点的错觉。
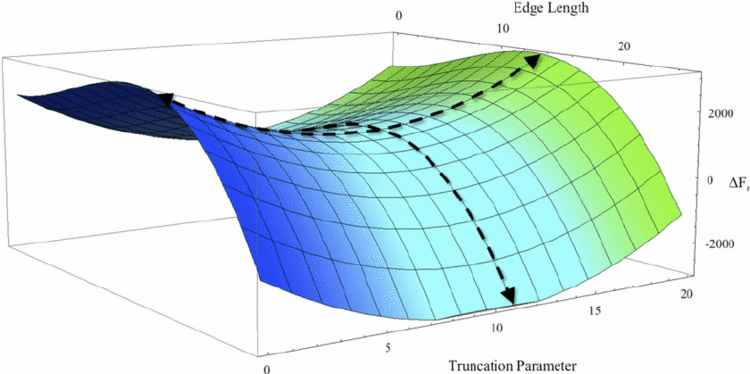
图3 鞍点示意图
5.三种梯度下降法对比

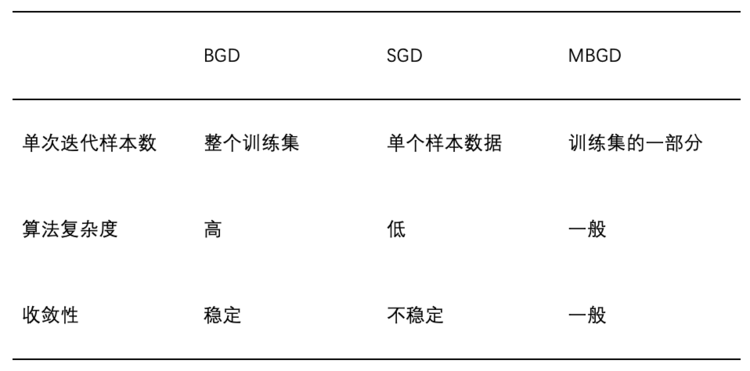
表1不同梯度下降法比较
本节课详细讲解了优化器的定义及原理,然后详细介绍了梯度下降法的三种形式以及对应的优缺点。下节课将继续由步步高老师为大家带来优化器不同种类的介绍以及实践过程中如何选择合适的优化器,满满的实践干货,记得点赞收藏~

回顾往期:
听六小桨讲AI | 第1期:卷积概念及计算
听六小桨讲AI | 第2期:卷积的批量计算及应用案例
如在使用过程中有问题,可加入官方QQ群进行交流:778260830。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END















 京公网安备 11010802041100号
京公网安备 11010802041100号