本周的科技前沿又跟大家见面了!除了美国各高校在机器人、自动驾驶等方面取得了一些新的进展之外,硅谷大公司在智能硬件、深度学习等方面也有新的突破。大家赶紧来看!
北美高校
密歇根大学:新算法让机器人对复杂环境变得更加敏感
机器人感知是阻碍家用机器人实际应用的最大瓶颈之一。在环境结构比较有序的地方,机器人可以很快地完成建造汽车等任务。 然而,人类的生活环境是非结构化的,面对这种混乱环境,目前的机器人还不够智能。
密歇根大学的研究人员开发出一种算法,可以让机器人更快地感知周遭环境的变化,从而成为家庭辅助机器人。
他们将这种新算法称为“Pull Message Passing for Nonparametric Belief Propagation”。 通过这种算法,在仅仅10分钟内,机器人就可以得出对周围环境和方向的准确理解,而用以往的方法需要超过一个半小时。

(图片来自网络,版权属于原作者)
研究人员表示,通过他们的算法,机器人可以正确地感知和使用抽屉,即便是抽屉被毯子盖住了一半、或是一半被拉开,或者机器人上的感应器被抽屉遮挡住。
之所以能有这么大的进步,是因为研究人员们将以往的 push messaging 改为了 pull messaging 形式,从而达到了简化计算需求的目的。
简单来说,与 push messaging 形式中不停地对周围物品发送信号—收集反馈信息—计算—再发射—反馈—计算这样的方式不同,pull messaging 算法让机器人先对空间信息进行一个整体的扫描,对周围所有的物品定位,标注上包含多重信息的编号,并将每个编号物品上的数据进行横向比较,从而节省后续的计算的时间。
耶鲁大学:研究发现×××药物如何抑制癌细胞中的DNA修复
根据耶鲁大学×××中心的研究,一种被认为用途有限的抗癌药物西地尼布(cediranib)其实拥有更多超级功效:它能够阻止某些癌细胞修复它们的DNA。这项研究被发表在《科学转化医学》杂志上。
该研究主要作者 Peter Glazer 教授表示,“DNA 修复以几种不同的方式发生,这就是为什么一些特定技术的抑制剂可能如此有价值的原因。人们正在认识到,操纵 DNA 修复可能非常有利于提高传统×××治疗的效果。”
使用西地尼布来帮助阻止癌细胞修复 DNA 损伤可能对许多依赖靶向药物的×××有用。而关于西地尼布为何可以在 DNA 修复过程的早期阶段关闭 DNA 修复的原因,Glazer 教授表示,“与另外一种药物 Olaparib 不同的是,西地尼布不能直接阻断 DNA 修复分子,也就是不能直接阻止 DNA 将自身缝合在一起,它其实是影响了 DNA 修复基因表达的调控。”
MIT:研发的非接触式无线健康监测设备通过临床测试
麻省理工学院 CSAIL 与 Novartis 公司合作测试了一项新技术:这种可用于生理信号的被动、非接触式无线监控可以用于对在家卧床的患者进行全天候的健康监测,而全部监测由类似于Wi-Fi的装置完成,患者无需佩戴任何接收设备。
麻省理工学院的 Dina Katabi 教授及她的学生们开发了这项技术。这个类似于Wi-Fi的监测设备可以通过传输低功率无线电信号,使用机器学习算法分析无线电信号的反射,来生成相应的生理指标。在无需患者佩戴传感器及改变行为的情况下,该设备可以收集信息包括患者的身体移动数据,行走姿势,呼吸,心率,睡眠的时间,睡眠中的呼吸暂停次数等。

MIT的Dina Katabi教授
Novartis 公司与麻省理工学院的团队合作探索了这项技术在临床试验中的潜在用途,在实验室中使用该设备对个体进行了多天的研究,并将所得数据与使用专业测量仪器的数据结果进行比较。比较结果表明,这项无线监测技术具有捕获运动和生理指标的能力。
如果后续研发和测试顺利,那么这种监测方式则有望走入病患家中,为人们的生活提供便利。
感兴趣的小伙伴可以信息:
https://www.csail.mit.edu/news/wireless-health-monitoring-system-shows-promise-clinical-trials
MIT:为自动驾驶系统加入人性化的建议
通过肉眼的观察和简单的辅助工具,人类驾驶员就可以驾车在未行驶过的道路上“如履平地”。然而,这种简单的思考和推理能力对于无人驾驶系统来说仍是个难题。
为了让无人驾驶系统拥有这种“简单的人类推理能力”,麻省理工学院CSAIL的研究人员创建了仅使用简单的地图和视觉数据的系统,使无人驾驶汽车能够在从未走过的复杂环境中轻松导航。

(图片来自网络,版权属于原作者)
这个自动驾驶系统可以通过使用来自摄像机的路况数据和简单的GPS地图,来“学习”人类驾驶员在小区域内行驶道路时的转向模式。然后,受过训练的系统就可以模仿人类驾驶员的方式,来为行驶在全新区域里的无人车导航。
与人类驾驶员的推理方式类似,该系统还可以通过实时地检测地图与实际道路特征之间的不一致,再次检测无人车的系统定位、传感器和映射是否正确,从而保证对无人车导航的正确性。

该系统使用了卷积神经网络(CNN)的机器学习模型进行图像识别。在训练期间,系统会观察并学习人类驾驶员的驾驶习惯和方式。 CNN将方向盘的旋转等驾驶操作与通过摄像机和输入的地图观察到的路况信息相关联。并最终根据各种道路情况生成最可能的转向命令,对无人车的导航进行辅助。
佐治亚理工:识别基因组变异技术,从几天缩短到几小时
从生物致病到×××引起的突变,诊断许多健康问题的第一步通常始于识别基因组的变异。但是,现有技术可能需要数天时间。近日,佐治亚理工开发的一种新算法能大幅缩短识别细胞或生物体中的基因组变异识的时间。

“将 DNA 序列与参考序列对齐是生物学中基因分型的关键一步。”该研究的负责人员 Chirag Jain 说道。因此佐治亚计算机工程学院和英特尔的研究人员共同设计了软件包装 PasGAL,这是第一个能够将 DNA 序列与复杂基因组图谱对齐的多核并行算法。
这个软件包能够利用现代计算机结构的多核特性,在多个数据点上同时执行一个任务。Jain 说,以前每次只能从人身上取出一个参考的 DNA 序列,一次只能评估一个单独的基因组,而现在则可以同时评估多个个体的多个基因组。
伯克利:造出会飞檐走壁的弹跳机器人
2016年,UC伯克利机器人学博士生Justin Yim制造了一个单腿机器人Salto。Salto 不仅可以像娃娃跳一样跳跃,也能像一条灵活的狗狗那样越过障碍。

Yim 和伯克利电气工程和计算机科学系教授 Ronald Fearing 合作进行该项目。Fearing 所在的仿生微系统实验室致力于探索如何利用动物运动机制创建更加灵活的机器人。Salto 有一条强大的腿,这条腿就是根据婴猴来建模的。
研究者希望 Salto 能够推动小型敏捷机器人的发展,这类机器人可以在碎石路上跳跃行走,支援搜救行动。
“小型机器人可以做很多事,”Yim 解释道:“比如去大型机器人或人类无法活动的地方。假设在灾难发生时,它们就可以用于寻找受灾的人,且不会对救援者造成危险,甚至会比没有辅助工具的救援者更快。”
传送门:https://news.berkeley.edu/2019/05/21/with-a-hop-a-skip-and-a-jump-high-flying-robot-masters-obstacles-with-ease/
斯坦福大学:科学家给分子打上荧光标签,更好理解细胞运作机理
如果我们将细胞视为机器,将分子视为运动部件,那么通过观察分子的去向和它们的作用,我们能更好理解生命是如何运作的。
斯坦福大学生物工程师 Jan Liphardt 领导的团队开发了一种方法,用来跟踪单个分子在长时间内穿过细胞的轨迹,并制作影像。他们通过改进荧光蛋白(FP)标记技术来实现这一目标,该技术允许科学家用荧光蛋白标记生物分子来追踪它们的运动 。
荧光蛋白(FP)标记技术面世已有一段时间,它的研发者获得了2008年诺贝尔化学奖。该技术使生物化学家能够将FP或荧光团附着到他们想要追踪的分子上。当被激光照射时,荧光团发光,从而研究人员能够跟踪标记的分子。但目前的技术有一个严重的缺点,那就是荧光团通常在几秒钟内即会燃尽。
而研究团队成员 Liphardt 和 Rajarshi Ghosh 开发了一种新型荧光标签,能够更好地用于实际的实验中,不会快速燃尽。该项研究发表在《自然化学生物学》杂志上。通过对荧光蛋白(FP)标记技术的改进,科学家将能够更好的了解生物变化的过程。
哥伦比亚大学:开发出由大脑控制的助听器
我们都知道,有些公共场所(例如餐厅)格外拢音,非常嘈杂,你连对面交谈的人说话都很难听清,但人类大脑能集中注意力、着重听某个声音,可以毫不费力的放大一个特定声音而不牵扯其他声音,但现阶段助听器却做不到。
本周,哥伦比亚大学的工程师们在 Science Advances 上发表了一项新技术:由大脑控制的助听器。这种由大脑控制的助听器由 AI 驱动,可监控佩戴者脑电波,自动过滤无关声音、放大增强佩戴者想要关注的声音。
哥伦比亚大学 Mortimer B. Zuckerman Mind Brain Behavior Institute 研究员、该论文作者 Nima Mesgarani 博士说,他们发现两个人在交谈的时候,说话的人的脑电波与听者的脑电波会逐渐趋同。于是团队将语音分离算法与神经网络、及模仿大脑自然计算能力的数学模型相结合,开发了一款脑控助听器,使用脑电波来判断哪些声音是需要被放大的 “重点声音”,哪些声音是噪音。
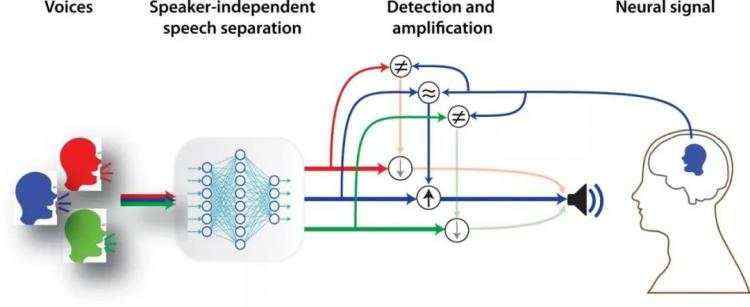
(图自论文作者)
那么,这个功能效果如何呢?虽然目前在室内环境中测试效果还不错,但是否能在室外环境也实现相同的效果,还需要进一步研究。虽然这项技术还处在极早期阶段,但该技术有望给助听器领域带来不小的革新。
大公司
彭博社:亚马逊要开发读心术了?
据彭博社报道,亚马逊正在开发一种可以读取情绪的、基于 Alexa 音控的便携式可穿戴设备,你没看错,Alexa 以后很可能了解你说话背后是快乐还是愤怒了!
据了解,这是亚马逊硬件开发团队 Lab126 和 Alexa 语音软件团队共同合作的一款产品,该设备将专为智能手机应用程序设计,配有麦克风和软件,能够根据用户的声音辨别佩戴者的情绪状态。
除此之外,彭博社还透露,亚马逊很可能将根据情绪状态,向人们提供相关广告或产品推荐。这意味着,用户是快乐、悲伤、恐惧、愤怒或任何其他情绪,都会得到更适合他们心情的不同建议的产品。
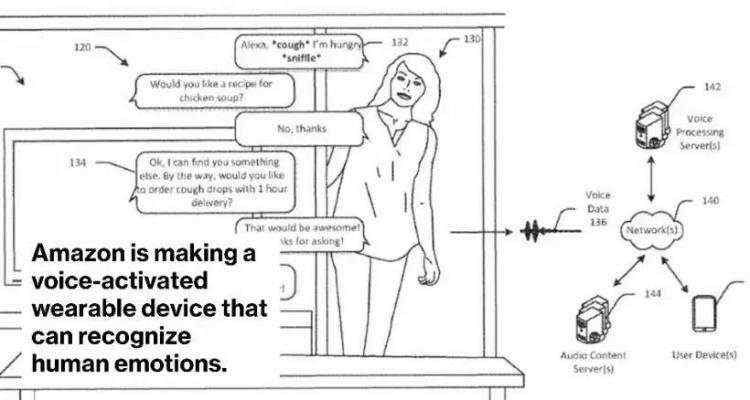
(图自彭博社)
早在 2017 年,亚马逊提交的美国专利中就描述了这样一种系统,语音软件使用声音模式分析确定用户感受。知名调研机构尼尔森研究显示,与不包含情感因素的广告相比,考虑人类情感并引发情绪反应的广告产生 23% 的销量增长。换句话说,公司越了解客户在任何时刻的感受,他们在向你做广告时就越有效。
所以,我们以后还能不能放心地对着 Alexa 说话了?
谷歌:移动相机+移动人:深度学习深度预测方法
在摄像机和人物同时都运动的情况下,从 2D 图像数据重建 3D 场景一直是个难度很大的挑战。以往的方法通常需要多摄像机阵列,或者当摄像机移动时,场景中的物体保持静止才能做到。
谷歌于5月23日发表的论文《Learning the Depths of Moving People by Watching Frozen People》中,研究人员通过应用基于深度学习的方法来解决这一挑战。该方法可以从普通视频生成深度图,即使摄像机和被拍摄主体都在自由移动也没关系。
该模型避免了直接3D测量,而是基于以前的数据,让算法学习人体姿态和形状。这项研究开创了首个针对摄像机和人体同时运动的情况而定制的学习方法。

(谷歌的算法从左侧常规视频中,生成的右侧深度图 / 图自谷歌博客)
NVIDIA:不必部署 AI 工具,轻松把 AI 引入医院放射科
在深度学习最具发展潜力的领域之一 —— 医学影像领域,AI 已经开始发力了,但并非每一家医院都有足够的设备去打造人工智能+医学影像的能力。
本周,英伟达和美国放射学院(ACR)联合发布了医院 AI 参考架构框架( ACR AI-LAB ),该框架包括英伟达的 GPU、Clara AI 工具包等基础设施,以及 GE 的Edison平台,以及构建和部署 AI 系统所需步骤的描述,并提供有关每个步骤所需的基础结构的指导,帮助医院轻松在放射科部署人工智能计划。
该框架三大亮点在于:医院数据、临床AI工作流程、AI计算能力,且这个 AI 框架的工作流程已经与医院系统例现有的医学影像存储系统相关联了。通过上述努力,将意味着有医学影像科的医疗保健机构,将不必再自行构建系统、部署 AI 工具了。
科研机构
俄罗斯斯科尔科沃科学技术研究所:比 Deepfakes 还牛、直接把静态图变成动图
5月20号,俄罗斯斯科尔科沃科学技术研究所(Skolkovo Institute of Science and Technology)发文 《Few-Shot Adversarial Learning of Realistic Neural Talking Head Models》,宣布研发出了一款 “直接把静态图变成动态图” 的换脸神器。
比如能把蒙娜丽莎变成这样:

或者这样:

这样的蒙娜丽莎,似乎看着不那么神秘了?
近半年来已有几项研究表明,通过训练卷积神经网络,可以生成看起来很真实的人面部图像。但如果想让机器生成一个看起来足够逼真的人脸部动图(比如说话、皱眉等),现有技术下就需要让机器通过单个人的大量图像进行训练。但有时我们需要从少数几张图片、甚至一张图片,就能做出从单张头像到动图的生成。
这篇论文里谈到的技术就只需要几张、甚至一张图就能生成真实可信的动图。机器先集中看很多视频、在海量视频数据集上执行冗长的元学习,之后通过功能强大的生成器(generator) 及 鉴别器(discriminator),它就能把少数几张图片、或单张图片变成动图。
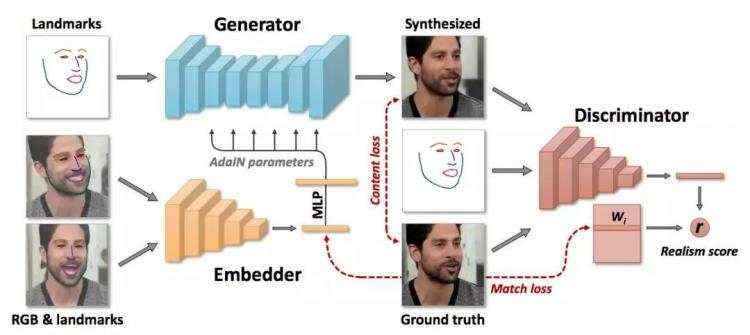
(图自论文作者)
值得注意的是,该系统能够根据人的图片,根据每张不同的头像,“量身定做” 生成器及鉴别器的参数,因此尽管需要调整数千万个参数,但训练可以仅基于少量图像快速完成。
更多精彩,敬请关注硅谷洞察官方网站(http://www.svinsight.com)







 京公网安备 11010802041100号
京公网安备 11010802041100号