作者:iris | 来源:互联网 | 2023-09-15 17:41
前言
TensorRT 优化主要包括网络结构优化和低精度推理,本文将详细介绍这两种优化方式。其中网络结构优化通过“网络层及张量融合”实现,低精度推理通过使用FP16或INT8进行模型推理实现。
一、低精度推理
背景:神经网络在训练时采用高精度保存参数,一般采用 32 位浮点数(Floating-Point, FP32),因此模型最后的 weights 也是 FP32 格式。
但是一旦完成训练,所有的网络参数就已经是最优,在推理过程中是无需进行反向迭代的,因此可以在推理中使用半精度浮点数 fp16 和 8 位整形数(INT8)计算从而获得更小的模型,低的显存占用率和延迟以及更高的吞吐率。
1.1 简介
低精度推理是一种较为常用的模型量化算法,通过将原始深度神经网络的高精度数据类型 转换为 低精度类型以达到显著减少网络运算时间的效果。
低精度推理方式,通常有两种:
- 采用半精度浮点数(Half-Precision Floating-Point,FP16)
- 或 8 位整形数(INT8)
来代替单精度浮点数(Single-Precision Floating-Point,FP32)的推理以保证模型具有较高的推理速度和精度。
1.2 低精度推理 的原理
训练阶段:卷积神经网络在训练阶段的误差反向传播过程中,有时参数的梯度更新微小,因此其数值表示需要较高的精度,参数需使用单精度浮点数(FP32)进行运算和存储。
即:深度网络训练阶段的前向推理计算损失函数和反向梯度传播、权重参数更新等都是 采用 FP32 方式运算和存储。
推理阶段:可将模型用于前向推理任务(它不需要 计算损失函数和反向梯度传播), 此过程对参数的精度要求较低,因此可以通过稍微降低数据精度的方式来加快模型的前 向推理进程。使用采用半精度浮点数(FP16)或8 位整形数(INT8)。
单精度浮点数(FP32)存储方式如下图所示:

FP32 数据类型占用 32 位的计算机内存,包含符号位、指数位和 尾数位三个部分,采用浮点基数表示数值的动态范围。
- 第一部分是符号位,占用 1 个 bit, 符号位为 0 代表该数据为正数,符号位为 1 代表该数据为负数。
- 第二部分是指数位,占 用 8 个 bits,使用科学计数法表示。
- 第三部分是尾数位,占用 23 个 bits。
半精度浮点数(FP16)的存储方式如下图所示:
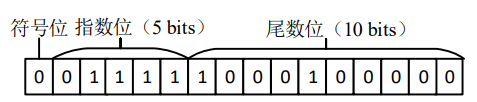
在计算机内存中占用 16 位,与 FP32 类似,同样包含符号位、指数位和尾数位三个部分。
- 第一部分 符号位占用 1 个 bit,符号位 为 0 代表该数据为正数,符号位为 1 代表该数据为负数。
- 第二部分 指数位占用 5 个 bits。
- 第三部分 尾数位 占用 10 个 bits。
从模型存储方式来看,FP16 模型相比 FP32 模型所占用的存储空间更少, 理论上 FP16 模型占用的存储空间为 FP32 的二分之一。
此外,FP16 模型执行前向推理 运算时占用显存少,网络计算效率高,延迟时间短并且模型吞吐量更大。
二、网络层及张量融合
2.1 简介
一般的网络结构中都含有较多的层,当模型执行前向推理运算时,每一层的计算都需要通过硬件中的 GPU 调用不同的 CUDA 核心函数来完成相应的计算。
通常 CUDA 核心函数执行张量计算的速度非常快,但是调用 CUDA 核心函数以及读写每一网络层的输入、输出张量会消耗大量的时间,导致出现 GPU 资源浪费和内存带宽占用等问题。
TensorRT 并不会改变最底层的运算内容,而是对计算流图进行优化。通过合并相同的运算来简化网络。如下图所示,(a) 具有多个卷积层和激活层的网络;(b) Tensor RT 优化后的网络结构。
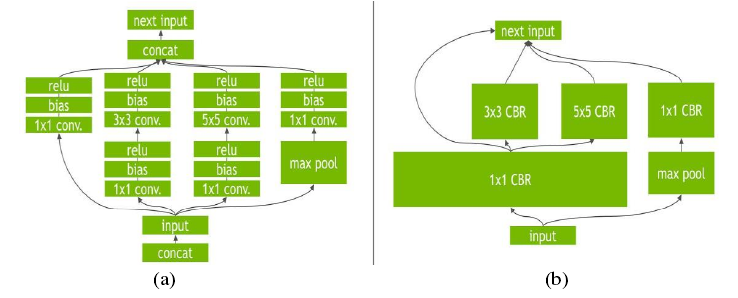
(a),这个网络结构中有很多层,在部署模型推理时,每一层的运算操作都是由 GPU 完成的,但实际上是 GPU 通过启动不同的 CUDA 核心来完成计算的。
分析:CUDA 核心计算张量的速度很快,但是大量的时间是浪费在 CUDA 核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。
解决方案:TensorRT 通过对层间的横向或纵向合并,合并后的结构称为 CBR(Convolution,Bias and Re LU),使得层的数量大大减少。
纵向合并可以把卷积、偏置和激活层合并成一个 CBR,只占用一个 CUDA 核心。
横向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个 CUDA 核心,如图 (b)中的超宽的 1×1 CBR。
同时,通过预分配输出缓存以及跳跃式写入方法来消除 concat 层。
通过这样的优化,TensorRT 可以获得更小、更快、更高效的计算流图,其拥有更少层的网络结构。下表列出了常见的 3 个网络在 TensorRT 优化后的网络层数量,明显的看到 Tensor RT 可以有效的优化网络结构、较少网络层数从而带来的性能的提升。

2.2 案例:Inception模块 进行网络层及张量融合
TensorRT 解析网络计算图时,通过将网络层及张量进行融合,从而减少CUDA 核心函数的调用次数以及网络层输入、输出张量的读写操作时间,达到模型前向推理加速的目的。
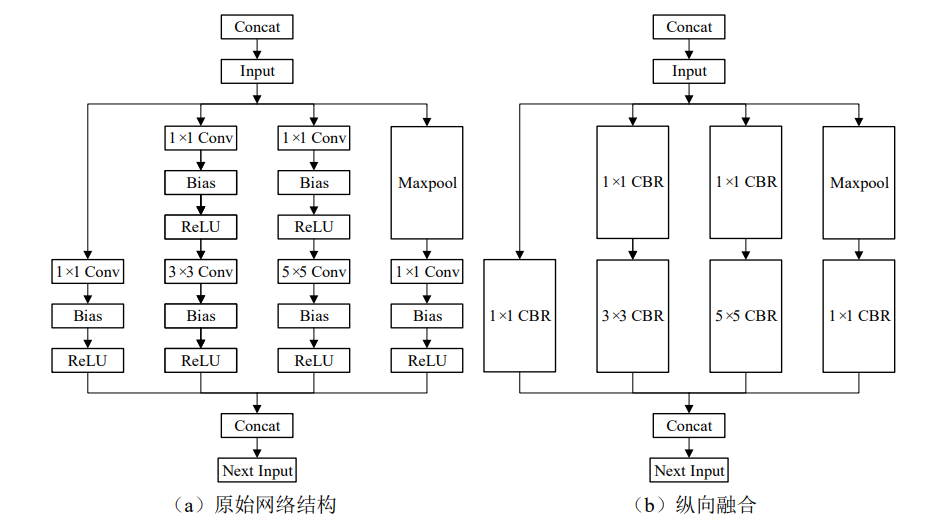
如下图所示,GoogLeNet中的 Inception 模块,以该模块为例阐述网络层及张量融合的过程。
- 第一步如图(a)为原始网络结构,首先特征图经过 Concat 操作后输入(Input)进模 块,接下来是多组卷积层(Conv)、偏置层(Bias)和激活层(ReLU),然后将多个结 果 Concat 到一起,最终得到下一个输出(Next Input)。
- 第二步如图(b)所示,将网 络结构进行纵向融合,把神经网络中依次连接的 Conv、Bias 和 ReLU 融合为一层,即 “CBR”层。
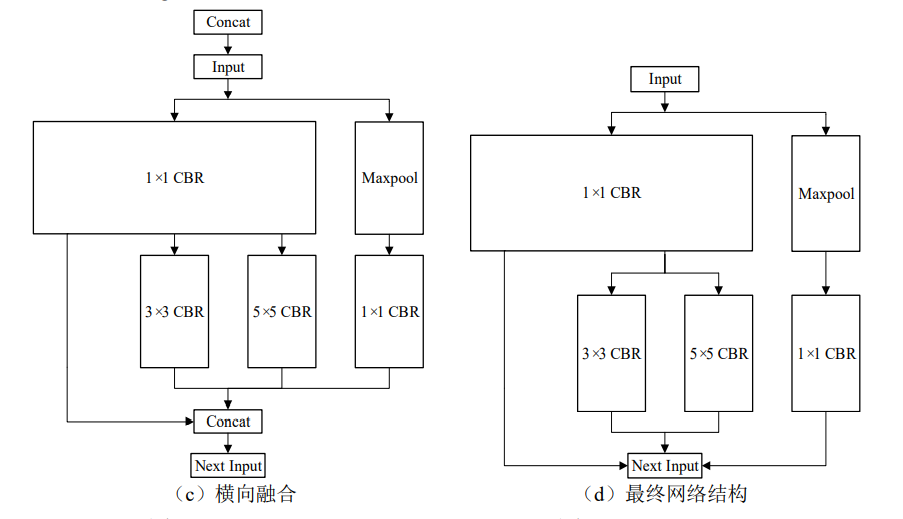
- 第三步如图(c)所示,将网络结构进行横向融合,横向融合是把神经 网路中输入为相同张量以及执行相同操作的层融合为一层,此过程将图 4.3(b)中 3 个 相连的 1×1 CBR 层融合为图 4.3(c)中一个更大的 1×1 CBR 层。
- 第四步如图(d) 所示,Concat 操作用于实现多个输出矩阵的拼接,TensorRT 能够实现多个输出矩阵与缓 冲区的直接连接,并不需要专门的 Concat 操作,因此可以将其删除,网络当前层的输 出直接输入到下一层网络。
参考文献:
[1] 尹昱航. 基于特征融合的交通场景目标检测方法研究[D]. 大连:大连理工大学, 2021.
[2] 葛壮壮. 基于嵌入式 GPU 的交通灯及数字检测[D]. 四川:电子科技大学, 2020.
本文直供大家参考学习,谢谢!








 京公网安备 11010802041100号
京公网安备 11010802041100号