首先介绍数据读取问题,现在TensorFlow官方推荐的数据读取方法是使用tf.data.Dataset,具体的细节不在这里赘述,看官方文档更清楚,这里主要记录一下官方文档没有提到的坑,以示"后人"。因为是记录踩过的坑,所以行文混乱,见谅。
I 问题背景
不感兴趣的可跳过此节。
最近在研究ENAS的代码,这个网络的作用是基于增强学习,能够自动生成合适的网络结构。原作者使用TensorFlow在cifar10上成功自动生成了网络结构,并取得了不错的效果。
但问题来了,此时我需要将代码转移到自己的数据集上,都知道cifar10图像大小是32*32,并不是特别大,所以原作者"丧心病狂"地采用了一次性将数据读进显存的操作,丝毫不考虑我等渣渣的感受。我的数据集原图基本在500*800或以上,经过反复试验,如果采用源代码我必须将图像通过缩放和中心裁剪到160*160才能正常运行,而且运行结果并不是很理想,十分类跑了一天左右最好的结果才30%左右。
我在想如果把图片放大后是否会提高准确度,所以第一个坑是修改数据读取方式,适应大数据集读取。
再仔细阅读源代码后我还发现作者使用了tf.train.shuffle_batch这个函数用来批量读取,这个函数也让我头疼了很久,因为一直不知道它和tf.data.Dataset.batch.shuffle()有什么区别,所以第二个坑时tf.train.shuffle_batch和tf.data.Dataset.batch.shuffle()到底什么关系(区别)
II tf.train.batch和tf.data.Dataset.batch.shuffle()什么区别
其实这两个谈不上什么区别,因为后者是前者的升级版,233333。
官方文档对tf.train.batch的描述是这样的:
THIS FUNCTION IS DEPRECATED. It will be removed in a future version. Instructions for updating: Queue-based input pipelines have been replaced by tf.data. Use tf.data.Dataset.batch(batch_size) (or padded_batch(...) if dynamic_pad=True).
在这里我也推荐大家用tf.data,因为他相比于原来的tf.train.batch好用太多。
III TensorFlow如何读取大数据集?
这里的大数据集指的是稍微比较大的,像ImageNet这样的数据集还没尝试过。所以下面的方法不敢肯定是否使用于ImageNet。
要想读取大数据集,我找到的官方给出的方案有两种:
- 使用TFRecord格式进行数据读取。
- 使用tf.placeholder,本文将主要介绍这种方法。
我的数据集是以已经分好类的文件夹进行存储的,大致结构是这样的
├───test
│ ├───Acne_Vulgaris
│ ├───Actinic_solar_Damage__Actinic_Keratosis
│ ├───Basal_Cell_Carcinoma
│ ├───Rosacea
│ └───Seborrheic_Keratosis
├───train
│ ├───Acne_Vulgaris
│ ├───Actinic_solar_Damage__Actinic_Keratosis
│ ├───Basal_Cell_Carcinoma
│ ├───Rosacea
│ └───Seborrheic_Keratosis
└───valid
├───Acne_Vulgaris
├───Actinic_solar_Damage__Actinic_Keratosis
├───Basal_Cell_Carcinoma
├───Rosacea
└───Seborrheic_Keratosis
我的方法非常适合懒人,具体流程如下:
1.torchvision读取数据
pytorch提供了torchvision这个库,这个库堪称瑰宝,torchvision.datasets里有个函数是ImageFolder,你只需要指明路径即可把图片数据都读进来,不用再苦逼地手写for循环遍历了。其他的细节,比如data augmentation等等就不介绍了,具体代码可参看官方文档以及如下链接: https://github.com/marsggbo/enas/blob/master/src/skin5_placeholder/data_utils.py
2.创建tf.placeholder
假设上一步已经图像数据读取完毕,并保存成numpy文件,下面参看官方文档例子
# 读取numpy数据
with np.load("/var/data/training_data.npy") as data:
features = data["features"]
labels = data["labels"]
# 查看图像和标签维度是否保持一致
assert features.shape[0] == labels.shape[0]
# 创建placeholder
features_placeholder = tf.placeholder(features.dtype, features.shape)
labels_placeholder = tf.placeholder(labels.dtype, labels.shape)
# 创建dataset
dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder))
# 批量读取,打散数据,repeat()
dataset = dataset.shuffle(20).batch(5).repeat()
# [Other transformations on `dataset`...]
dataset_other = ...
iterator = dataset.make_initializable_iterator()
data_element = iterator.get_nex()
sess = tf.Session()
sess.run(iterator.initializer, feed_dict={features_placeholder: features,labels_placeholder: labels})
for e in range(EPOCHS):
for step in range(num_batches):
x_batch, y_batch = sess.run(data_element)
y_pred = model(x_batch)
...
...
sess.close()
插播一条广告:上面代码中batch(), shuffle(), repeat()的具体用法参见Tensorflow datasets.shuffle repeat batch方法。
上面逻辑很清楚:
- 创建placeholder
- 创建dataset
- 然后数据打乱,批量读取
- 创建迭代器,使用get_next()迭代获取下一个batch数据,这里返回的是以个tuple,即(feature_batch, label_batch)
- 初始化迭代器,并将数据喂给placeholder,注意迭代器要在循环语句之前初始化,否则无法完整把数据集遍历读取一遍。
- 进入循环语句,批量读取数据,开始进行运算了。
注意,每次一运行sess.run(data_element)这个语句,TensorFlow会自动的调取下一个批次的数据。不仅如此,只要sess.run一个把data_element作为输入的节点,也都会自动调取下一个批次的数据。说的有点绕,看例子就明白了
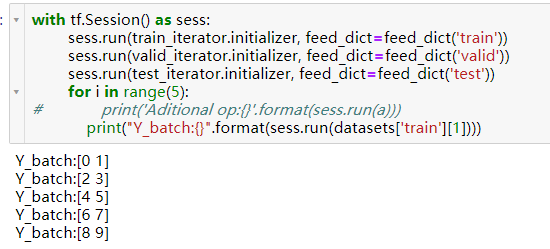

可以看到如果在读取数据的时候还sess.run与数据有关的操作,那么有的数据就根本没遍历到,所以这个问题要特别注意。
那我为什么会连这种坑都能踩到呢,因为原作者的代码写的太“好”了,对于我这种刚入门的人来说太难理解和修改了。
原作者的代码结构并没有写for循环遍历读取数据,然后传入到模型。相反他把数据操作写到了另一个类(文件)中,比如说在model.py中他定义了
class Model():
def __init__():
...
def _model(self, img, label):
y_pred = other_function(img)
acc = calculate_acc(y_pred, label)
...
然后在main.py中他只是sess.run(model.acc),即
with tf.Session() as sess:
...
while epoch 抱怨一下: 它这代码结构写得和官方文档不一样,所以一直不知道怎么修改。你如果从最开始看到这,你应该觉得很好改啊,但是你看着官方文档真不知道怎么修改,因为最开始我并不知道每次sess.run之后都会自动调用下一个batch的数据,而且也还没有习惯TensorFlow数据流的思维。在这里特别感谢这个问题帮助我解答了困惑:Tensorflow: create minibatch from numpy array > 2 GB。
所以这种情况怎么读取数据呢?很简单,只需要在循环语句之前初始化迭代器即可。
ops = {
"global_step": model.global_step,
"acc": model.acc
}
with tf.Session() as sess:
...
sess.run(iterator.initializer, feed_dict={features_placeholder: features,labels_placeholder: labels})
while epoch 如果你想要查看数据是否正确读取,千万不要在上面的while循环中加入这么一行代码x_batch, y_batch=sess.run([model.x_batch, model.y_batch]),这样就会导致上面所说的数据无法完整遍历的问题。那怎么办呢?
我们可以考虑修改ops来获取数据,代码如下:
ops = {
"global_step": model.global_step,
"acc": model.acc,
"x_batch": model.x_batch,
"y_batch": model.y_batch
}
with tf.Session() as sess:
...
sess.run(iterator.initializer, feed_dict={features_placeholder: features,labels_placeholder: labels})
while epoch 这样之所以能完整遍历,是因为我们将x_batch和acc放在一起啦~,所以这可以看成只是一个运算。







 京公网安备 11010802041100号
京公网安备 11010802041100号