篇首语:本文由编程笔记#小编为大家整理,主要介绍了TNN框架解析相关的知识,希望对你有一定的参考价值。
近一年多的时间,一直都在做推理框架相关的工作,期间也学习了很多东西,特别是以前比较欠缺的CUDA编程相关内容。这一年来收获很多,对推理框架认识也越来越深刻。以前纯做算法的时候,越到后面,越觉得无趣,比如你经常会发现你辛辛苦苦调参了一周,却发现毫无效果,或者发现虽然能work,但是却不知道为什么能work,还有算法工程师很多时候大部分时间都用来处理数据了,总是做这样的工作有的时候感觉就是在浪费生命,对自己的成长和职业发展没有太大意义。换了一个方向之后,感觉心里踏实很多,也很喜欢现在的方向,虽然还有很多东西需要学习,其实做推理框架期间,以前算法的经验是非常有用的, 因为有些客户的算法需要适配我们自己的推理框架,就需要懂算法的人,如果你对算法比较了解,那么解决问题就会方便很多,比如现在很多CV方向的客户,经常用的算法包括人脸检测领域的RetinaFace,人脸识别领域的arcFace,目标检测领域的YOLO系列和SSD系列,这些算法我都是比较熟悉的算法,所以做适配的时候,就容易很多,跟客户交流的时候也更方便。如果你不懂算法,适配的时候就困难很多。懂算法还能够帮你更好的理解一个推理框架,遇到框架中出现的问题,也能够更好的进行分析和定位。这一年重点调研了AMD开源的推理框架MIGraphX,还有就是最近一直在调研的腾讯开源的推理框架TNN,这篇文章主要是对TNN框架做个简单的解析。
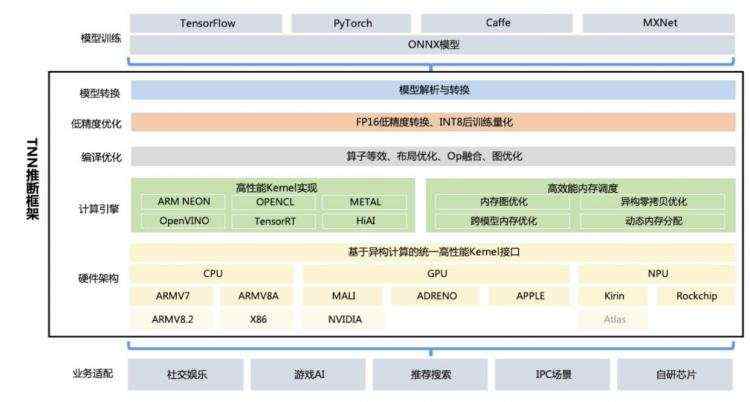
TNN架构设计层次还是非常清晰的,整体架构与MIGraphX类似,都包含了模型转换、低精度优化、编译优化和计算引擎。但是实现方式差异很大,TNN的很多设计借鉴了Caffe的设计思想,比如层的设计,而MIGraphX则借鉴了TVM的设计思想,更偏向于深度学习编译器的设计理念。关于两者的区别下面会进一步阐述。
tnn中有几个重要的数据类型,包括:
下面看一下他们之间的关系。
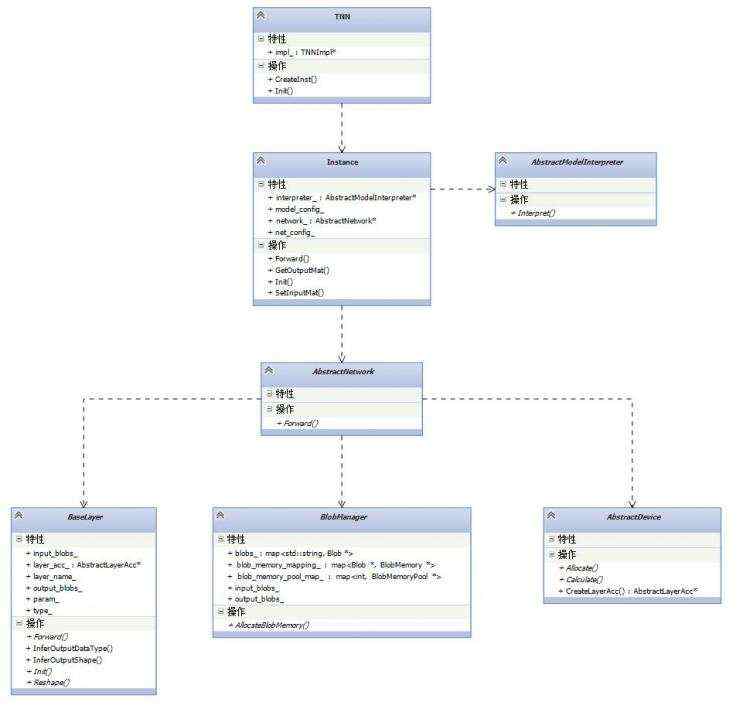
TNN的几个关键类型的类图如上图所示,虚线表示依赖关系,比如AbstractNetwork依赖BaseLayer,BlobManager和AbstractDevice。其中TNN类作为TNN整个类图框架中的最顶层的类,是对外提供的一组接口,用户在使用TNN的时候,就通过TNN类对外的接口来进行模型解析和创建网络,TNN的init方法创建一个模型解析器并进行模型解析,CreateInst方法负责创建网络。TNN类的CreateInst方法实际通过Instance类型来创建网络的。Instance类创建的网络保存在成员变量network中。TNN中的网络由层组成,这一点跟caffe是一致的,同时包含了内存管理模块,所以上述类图中AbstractNetwork依赖于BaseLayer,BlobManager和AbstractDevice,下面重点分析一下network的这几个部分。
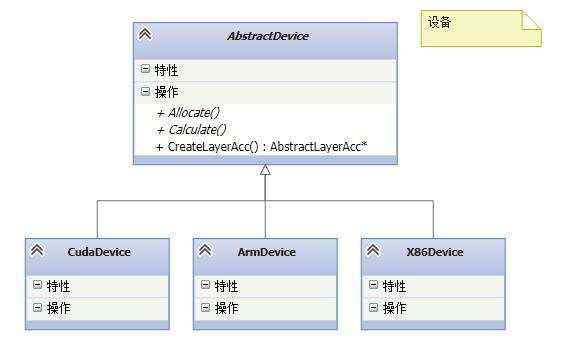
TNN中的设备表示支持的各种后端,包括arm,x86,cuda等。device的重要作用就是提供了不同后端的算子实现,算子的具体某个后端的实现通过AbstractDevice的CreateLayerAcc()方法来创建。
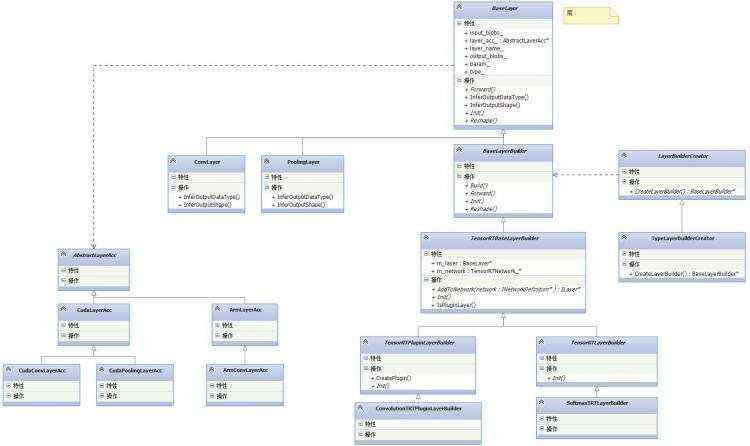
TNN中层的概念与Caffe中的层的概念基本一致,同样包含了caffe中层的reshape,forward等方法,如果你对caffe很了解,那么对TNN的层就很容易理解。层中的成员变量layer_acc为具体设备的实现,该成员变量通过device的CreateLayerAcc()方法赋值实现不同后端的算子计算。注意,TNN中cuda后端是通过tensorrt来实现的,层的实现也是通过tensorrt的插件来实现的。

推理框架中一个很重要的模块就是内存管理。TNN中通过BlobManager来实现内存管理。BlobManager又是通过内存池BlobMemoryPool来实现实际的内存管理。上述类图中,Blob与caffe中的blob概念类似,Blob中包含了blob的属性描述和内存数据,BlobMemory保存了Blob的实际的内存,并通过内存池来分配和释放。TNN中将Blob和BlobMemory进行解耦是为了更好的优化内存。
TNN中大部分类型通过注册器注册到系统中,而TNN中的注册用到了一个关键的设计模式:工厂方法模式。
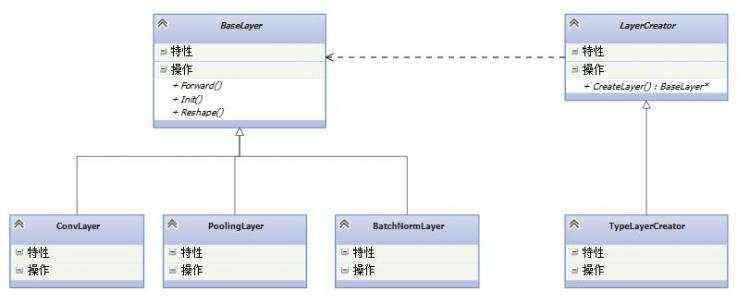
BaseLayer作为产品类的基类,下面派生出各种产品,包括卷积层,Pooling层等。LayerCreator作为工厂类的基类,包含了一个工厂方法CreateLayer(),注意,这个方法返回的是BaseLayer*。这样才能够实现创建各种不同的产品。最后会通过一个注册器来实现自动注册。注册器的实现如下:
template <typename T>
class TypeLayerRegister
public:
explicit TypeLayerRegister(LayerType type)
GetGlobalLayerCreatorMap()[type] &#61; shared_ptr<T>(new T(type));
;
注册器在构造函数中实现产品和工厂的注册&#xff0c;在构造函数中&#xff0c;首先获取一个std::map
TypeLayerRegister<TypeLayerCreator<ConvLayer>> g_conv_register(LAYER_CONVOLUTION);
因为全局变量在程序启动的时候就会自动创建&#xff0c;而创建的时候会调用构造函数&#xff0c;从而实现自动注册的功能。
下面看一下常用的深度学习框架在op粒度,内存和动态shape方面的对比。
| Caffe | TNN | TensorRT | MIGraphX | TVM | |
|---|---|---|---|---|---|
| OP粒度 | 粗 | 粗 | 粗 | 细 | 细 |
| 灵活度 | 低 | 低 | 低 | 高 | 高 |
| 内存消耗 | 高 | 低 | 低 | 低 | 低 |
| 动态shape | 支持 | 支持 | 支持 | 不支持 | 支持 |
下面以TNN和MIGraphX为例&#xff0c;详细讨论一下各方面的对比。
TNN在整体的设计方面参考了caffe的设计。下表列出了两者在一些数据类型上的对比&#xff1a;
| Caffe | TNN | 备注 |
|---|---|---|
| Net | DefaultNetwork | 网络表示整个模型&#xff0c;通常一个网络包含若干层 |
| Layer | BaseLayer | 层 |
| Blob | Blob | 保存数据 |
可以看出&#xff0c;TNN中主要的数据类型都参考了caffe的设计&#xff0c;在整体架构设计上也有很多地方参考了caffe。caffe属于第一代深度学习框架&#xff0c;op的粒度比较粗&#xff0c;所以TNN的op粒度也比较粗&#xff0c;而MIGraphX的op粒度相比TNN来说要更细。下表列举了一些算子在两种框架中的实现差异&#xff1a;
| TNN | MIGraphX | |
|---|---|---|
| 卷积&#43;偏置 | 采用一个卷积层实现 | 由三个算子组成&#xff1a;convolution&#43;broadcast&#43;add |
| 全连接层 | 采用一个全连接层实现 | 由两个算子组成&#xff1a;Reshape&#43;gemm |
从上表可以看出&#xff0c;TNN中通常可以使用一个层实现的计算&#xff0c;在MIGraphX中可能需要好几个算子来实现。细粒度算子虽然比较灵活&#xff0c;但是由于会增加重复访问内存的次数&#xff0c;所以速度慢&#xff0c;而粗粒度虽然灵活度不够&#xff0c;但是速度快。这一点是TNN和MIGraphX的一个非常重要的区别。对于细粒度速度较慢的问题&#xff0c;可以通过计算图优化提高速度&#xff0c;典型的计算图优化包括算子融合&#xff0c;算子等价&#xff0c;删除公共子表达式。下表列出了MIGraphX的一些计算图优化。
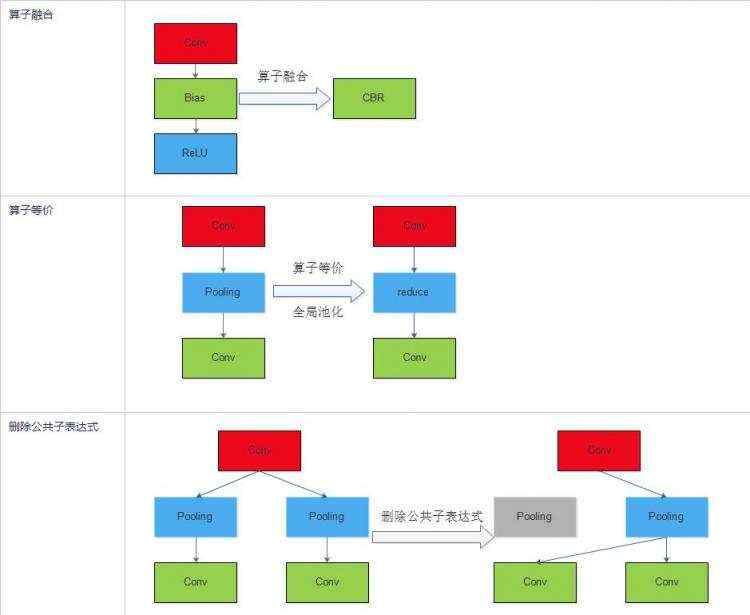
上面提到了MIGraphX的设计参考了TVM&#xff0c;MIGraphX中很多概念都借鉴了TVM。
内存的优化是推理框架的一个重要组成部分&#xff0c;特别是对于内存较小的一些场景&#xff0c;比如移动端设备。TNN和MIGraphX都对内存做了优化。下面我们看一下几个经典模型在TNN中和MIGraphX中的内存占用(注&#xff1a;不包括算子参数占用的内存,只包含每层输出的内存)。
| 优化前 | 优化后 | |
|---|---|---|
| alexnet | TNN:3M,MIGraphX:6M | TNN:1.5M,MIGraphX:5M |
| mobilenet_v2 | TNN:27M,MIGraphX:77M | TNN:9M,MIGraphX:12M |
| inception_v3 | TNN:33M,MIGraphX:66M | TNN:7M,MIGraphX:5M |
| vgg16 | TNN:58M,MIGraphX:161M | TNN:25M,MIGraphX:25M |
| resnet50 | TNN:86M,MIGraphX:114M | TNN:10M,MIGraphX:9M |
注&#xff1a;测试模型的batchsize为1&#xff0c;且使用FP32模式
从上表可以看出&#xff0c;TNN优化后的内存占用平均为优化前的32%&#xff0c;而MIGraphX优化后的内存占用平均为优化前的26%。由于两个框架对计算图优化存在较大差异&#xff0c;所以不能仅从上述表格中的数据说明哪个内存优化效率更高。下面分析一下两个框架内存优化原理。
TNN官方文档中对内存优化的介绍说&#xff1a; 通过 DAG 网络计算图分析&#xff0c; 实现无计算依赖的节点间复用内存&#xff0c; 降低 90% 内存资源消耗。阅读完TNN内存优化部分的源码之后&#xff0c;发现TNN对内存优化的方法其实很简单&#xff0c;下面用一个非常简单的网络阐述一下TNN的优化过程&#xff1a;
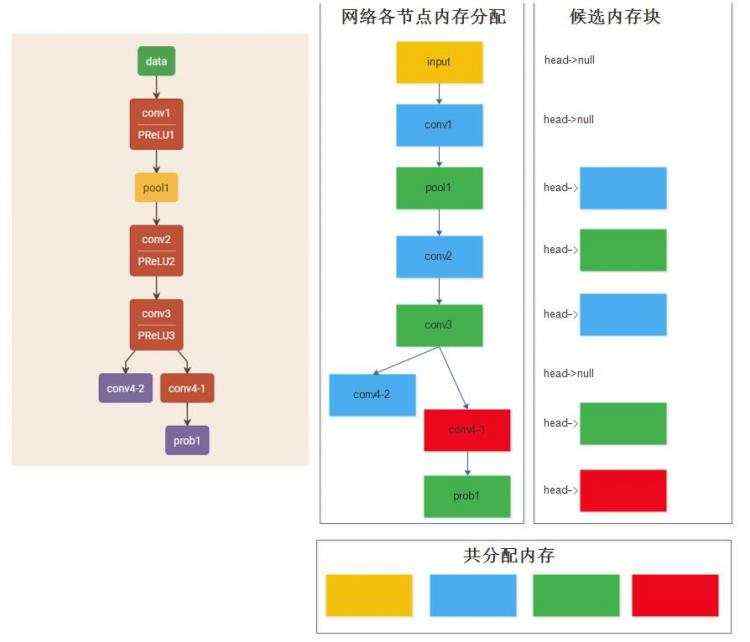
最左边是原始的网络结构&#xff0c;右边为TNN的内存优化过程&#xff0c;其中不同颜色代表了不同的内存块&#xff0c;同一种颜色表示相同的一个内存块。在分析的过程中不考虑ReLU层。
TNN在优化内存的时候&#xff0c;主要的思想就是&#xff1a;创建一个候选内存块链表&#xff0c;保存之前已经使用过的内存块&#xff0c;然后在每次创建新层的时候&#xff1a;为该层的输出分配内存的时候&#xff0c;首先从候选内存块中找是否有合适的内存块&#xff0c;如果找到了就直接用该内存块&#xff0c;否则申请一块新的内存块&#xff0c;然后查看该层的输入&#xff0c;如果该层的输入不再被使用&#xff0c;则放入候选内存块链表中&#xff0c;供下面的新层使用。
下面分析一下上诉网络的内存优化过程&#xff1a;
通过上述内存优化&#xff0c;就完成了整个网络的内存分配工作&#xff0c;可以看到一共使用了4个内存块&#xff0c;显著提高了内存使用效率。
migraphx的内存优化通过图论中的图着色算法实现的。图着色的基本思想就是&#xff1a;给定无向连通图G和m种不同的颜色。用这些颜色为图G的各顶点着色&#xff0c;每个顶点着一种颜色。是否有一种着色法使G中每条边的2个顶点着不同颜色。若一个图最少需要m种颜色才能使图中每条边连接的2个顶点着不同颜色&#xff0c;则称这个数m为该图的色数。
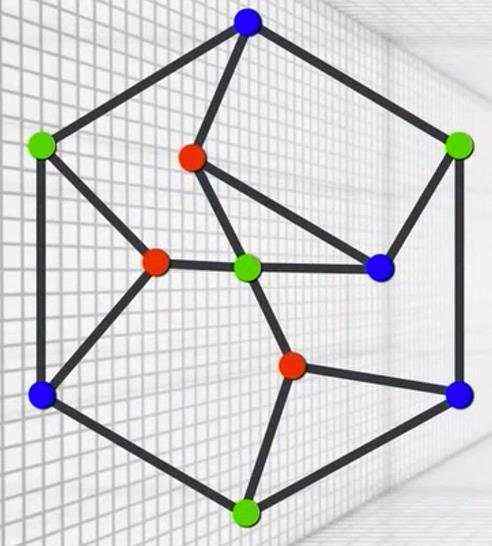
比如上图的色数为3,也就是说至少需要3中颜色就可以使得每条边的2个顶点颜色不同。联系上面的TNN内存优化策略&#xff0c;我们可以发现&#xff0c;TNN的内存优化策略其实就是让图中每条边的2个顶点颜色不同。上述TNN的示例中&#xff0c;不算数据层&#xff0c;则那张图的色度为3。虽然migraphx使用的内存优化算法实现和TNN不同&#xff0c;但是核心思想是一样的&#xff0c;就是让每条边的两个顶点颜色不同。从而达到内存复用的效果。
实际上完全的动态输入对内存是非常不友好的&#xff0c;对于训练框架来说&#xff0c;这个影响可能不大&#xff0c;但是对于推理框架来说这个影响是非常大的&#xff0c;比如caffe,可以在每次Forward的时候&#xff0c;进行Reshape,重新进行内存分配和释放&#xff0c;但是如果推理框架每次Forward的时候&#xff0c;都需要进行内存分配和释放&#xff0c;那么对推理效率的影响是非常大的。上面提到的TNN和MIGraphX的内存优化都是在有确定的输入大小的情况下才能够实现的。但是TNN是可以实现动态输入的&#xff0c;但是MIGraphX目前是不支持的。下面我们看一下TNN是如何实现的。
TNN中创建网络的时候可以使用下面的一个接口&#xff1a;
std::shared_ptr<Instance> CreateInst(NetworkConfig& config, Status& status,InputShapesMap min_inputs_shape, InputShapesMap max_inputs_shape);
注意&#xff0c;这里有个max_inputs_shape参数&#xff0c;这个参数的意思就是最大输入大小&#xff0c;如果你需要支持动态输入&#xff0c;则需要指定动态输入大小的最大尺寸是多少&#xff0c;否则无法使用动态输入。一般情况下&#xff0c;当网络输入大小改变了的时候&#xff0c;对网络进行Forward的时候&#xff0c;如果Blob的元素大小大于原来的大小&#xff0c;则需要进行重新内存分配。但是TNN可以做到在网络输入大小改变之后&#xff0c;不需要重新内存分配。这其中有个关键的地方&#xff1a;创建网络的时候&#xff0c;使用max_inputs_shape进行内存分配和优化。当使用max_inputs_shape进行内存分配和优化的时候&#xff0c;网络中每个层分配的内存都是最大的&#xff0c;这就保证了当输入为动态的时候&#xff0c;每个层需要的内存是够用的&#xff0c;不需要再重新分配了&#xff0c;这样就可以大大减少内存分配的耗时&#xff0c;上面TNN的内存优化示例中网络一共需要使用4个内存块&#xff0c;这4个内存块都是使用max_inputs_shape计算出来的。TNN中当输入大小改变之后&#xff0c;只需要通过每层的Reshape方法重新计算该层输出Blob的大小即可&#xff0c;不需要重新内存分配了。TNN能够实现该机制还有一个重要原因就是将Blob的属性(BlobDesc)和数据(BlobMemory)进行了解耦&#xff0c;使用内存池管理实际的数据。
虽然接触推理框架有一年的时间了&#xff0c;但是觉得还是有很多地方需要学习。这篇文章只是对TNN的整体结构做了一个简单的介绍&#xff0c;文中有什么描述不对的地方&#xff0c;欢迎大家批评指正&#xff0c;也欢迎做推理框架的朋友留言讨论。
2021-9-13 15:51:23
非常感谢您的阅读&#xff0c;如果您觉得这篇文章对您有帮助&#xff0c;欢迎扫码进行赞赏。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有