作者:so直接离我远点儿 | 来源:互联网 | 2023-08-19 18:16
雷锋网AI科技评论按:为了顺应“在本地设备上运行机器学习模型”的潮流,以及具体点来说,给自家Pixel2以及未来的手机上的AI加速芯片(thePixelVisualCore)提供运
雷锋网 AI 科技评论按:为了顺应“在本地设备上运行机器学习模型”的潮流,以及具体点来说,给自家Pixel 2以及未来的手机上的AI加速芯片(the Pixel Visual Core)提供运行库,谷歌正式发布了TensorFlow Lite,作为TensorFlow Mobile API的升级版进入公众视野,同时开源+长期更新。
TensorFlow桌面和TensorFlow Lite的定位固然有所不同,前者可以兼顾训练和推理,后者则是专门考虑如何在移动设备上高效运行;这导致它们的技术特点有所区别,TensorFlow桌面的模型也需要经过转换后才能在TensorFlow Lite上运行。
另一方面,在发布TensorFlow Lite软件的同时,谷歌研究院也另外发出一篇博文介绍了一种新的模型压缩方法,不仅有优秀的压缩效果,压缩后的模型也可以直接在TensorFlow Lite上运行,可谓是一个重大好消息。雷锋网 AI 科技评论把这篇博文翻译如下。

TensorFlow Lite
2017年早些时候,谷歌发布了Android Wear 2.0,首次支持在移动设备上运行机器学习模型,用来提供智能化的消息处理。之前在谷歌的Gmail、Inbox、Allo里提供的基于云服务的“智能回复”功能也就首次可以在任何程序中工作,包括第三方的即时消息软件。有了本地的机器学习计算能力后就再也不需要连接到云服务上,在路上就可以直接从智能手表回复聊天消息。
美国时间11月14日,谷歌正式发布了TensorFlow Lite,这是TensorFlow用于移动设备和嵌入式设备的轻量化版本。这个开发框架专门为机器学习模型的低延迟推理做了优化,专注于更少的内存占用以及更快的运行速度。作为软件资源库的一部分,谷歌也发布了一个可以运行在设备上的聊天模型以及一个demo app,它们是谷歌编写的运行在TensorFlow Lite上的自然语言应用的样例,供开发人员和研究者们研究学习、开发更多新的本地运行的机器智能功能。输入聊天对话消息以后,这个模型就可以生成一条建议的回复;它的推理过程非常高效,可以轻松嵌入到各种聊天软件中,利用设备自身的计算能力提供智能的聊天功能。
谷歌发布的这个本地运行的聊天模型运用了一种训练紧凑神经网络(以及其它机器学习模型)的新机器学习架构,它基于一个联合优化范式,最初发表在论文 ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections 中。这种架构可以高效地运行在计算能力和内存都较为有限的移动设备上,通过高效的“投影”操作,它可以把任意输入转换成一个紧凑的位向量表征,这个过程中类似的输入会被投影到相邻的向量中;根据投影类型的不同这些向量可以是密集的也可以是稀疏的。比如,“嘿如何了?”和“兄弟你如何了?”两条消息就有可能被投影到相同的向量表征上去。
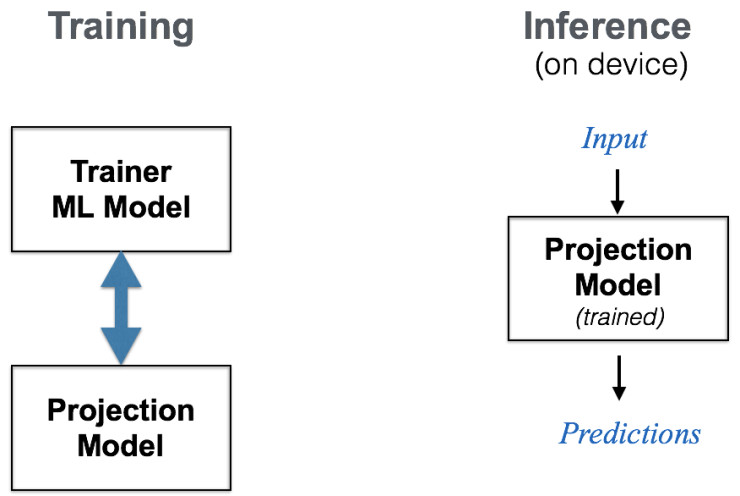
通过这样的想法,谷歌的聊天模型就以很低的计算开销和内存消耗加入了这些高效的操作。这个在设备本地运行的模型是谷歌用端到端的方法训练的,训练过程中使用了联合训练两个不同模型的机器学习框架;这两个训练的模型,一个是紧凑的“投影”模型(如上文所述),同时还结合了一个“训练器”模型。两个模型是联合训练的,投影模型从训练器模型中学习;训练器模型有着专家的特质,它是用更大、更复杂的机器学习架构创建的,而投影模型就像一个跟在后面学习的学生。在训练过程中,也可以叠加其它的量化、蒸馏之类的技术,达到更紧凑的压缩效果,或者也可以选择性地优化目标函数的某些部分。一旦训练结束,这个更小的投影模型就可以直接在设备上做推理任务。
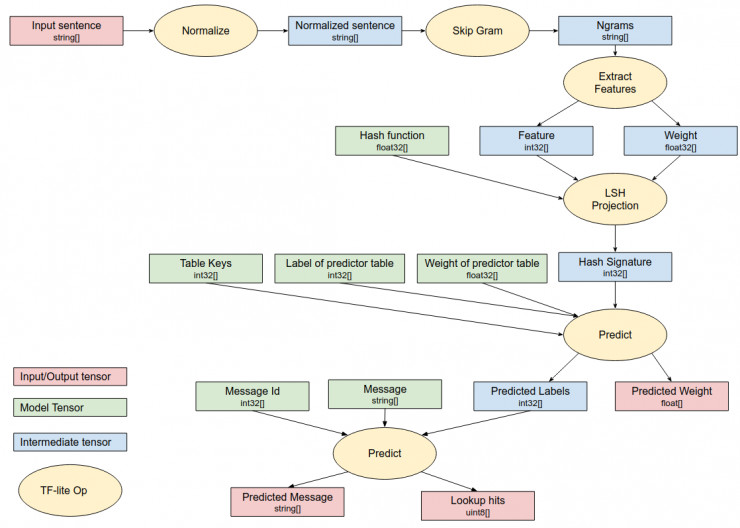
在推理过程中,训练后的投影模型会被编译成一系列 TensorFlow Lite 的操作,而这些操作都是为移动平台的快速执行优化过的,可以直接在设备上执行。这个本地运行的聊天模型的TensorFlow Lite推理图如下所示。
这个用上述的联合训练方法端到端训练的聊天模型是开源的,今天(美国时间11月14日)就会和代码一起发布出来。同时还会发布一个demo app,这样研究人员和开发人员就可以轻松地下载它们、在自己的移动设备上试试看它提供的一键智能回复功能。这个架构能根据应用需求提供不同模型大小、不同预测质量的配置功能,操作也很方便。除了一些已知的模型可以给出很好回复的消息之外,系统还可以把一组固定的聊天对话中观察到、然后学习编译到模型中的流行的回复语句作为预测失败后的备选语句。它背后的模型和谷歌在自家应用中提供“智能回复”功能的模型有一些区别。
在聊天模型之后
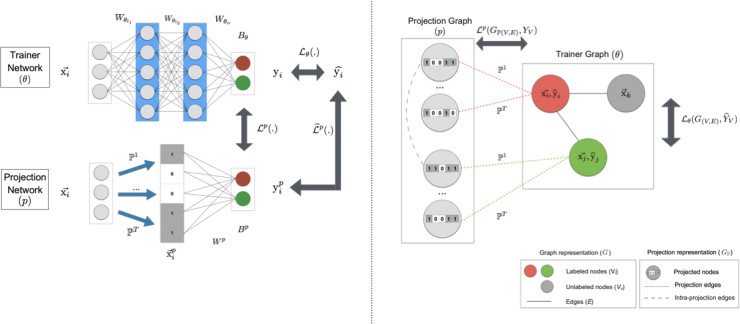
有趣的是,上面描述的机器学习架构保证了背后隐含的模型具有各种灵活的选择。谷歌的研究人员们把这个架构设计得可以与不同的机器学习方法兼容,比如,与TensorFlow深度学习共同使用时,就可以为隐含模型学到一个轻量化的神经网络(“投影网络”),并用一个图框架(“投影图”)来表征这个模型,不再是神经网络的形式。
联合训练框架也可以用来给使用其它机器学习建模架构的任务训练轻量级的本地运行模型。比如,谷歌把一个复杂的前向传输或者循环网络架构(比如LSTM)作为训练器模型,训练得到的投影架构就可以简单地由动态投影操作和寥寥几层全连接层组成。整个架构是以端到端的方式在TensorFlow中通过反向传播训练的。训练结束后,紧凑的投影网络就可以直接用来做推理。通过这样的方法,谷歌的研究人员们成功训练了不少小巧的投影模型,它们不仅在模型大小方面有大幅度下降(最高可以缩小几个数量级),而且在多种视觉和语言分类任务中可以保证同样的准确率但性能高得多。类似地,他们也用图学习范式训练了其它的轻量级模型,即便是在半监督学习的设定中。
谷歌表示,他们在开源TensorFlow Lite后会持续改进以及发布新版本。通过这些机器学习架构学到的模型,不管是已经发布的还是将在未来发布的,都不仅可以应用在多种自然语言和计算机视觉应用中,也可以嵌入已有的应用中提供机器智能的功能。同时谷歌当然也希望及机器学习和自然语言处理大家庭中的其它研究者和开发者也可以在这些基础上共同应对谷歌尚未发现或者尚未解决的新问题。
via Google Research Blog,雷锋网(公众号:雷锋网) AI 科技评论编译。
相关文章:
Google正式发布TensorFlow Lite预览版,针对移动/嵌入设备的轻量级解决方案
TensorFlow全新的数据读取方式:Dataset API入门教程
谷歌发布TensorFlow 1.4版本:支持分布式训练,迎来三大新变化
紧跟未来深度学习框架需求,TensorFlow推出Eager Execution
雷锋网版权文章,未经授权禁止转载。详情见。














 京公网安备 11010802041100号
京公网安备 11010802041100号