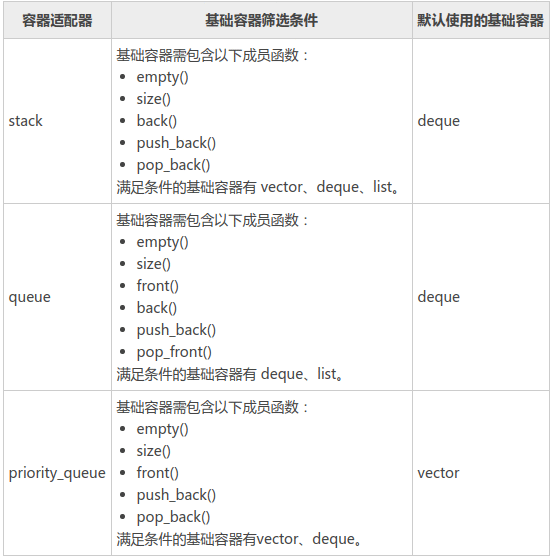
一、优先队列
简介
优先队列也被称为堆(heap),队列中允许的操作是 先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素。二叉树的衍生,有最小堆最大堆的两个概念,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。通常可以被看做是一棵完全二叉树的数组对象。
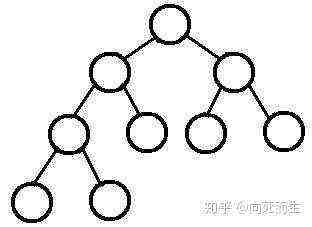
完全二叉树
若设二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这就是完全二叉树。
特性
1.它是完全二叉树,除了树的最后一层结点不需要是满的,其它的每一层从左到右都是满的,如果最后一层结点不是满的,那么要求左满右不满。
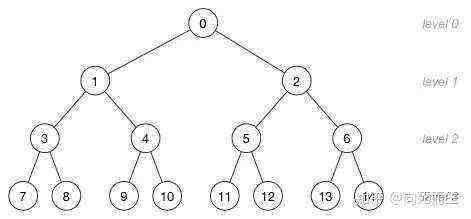
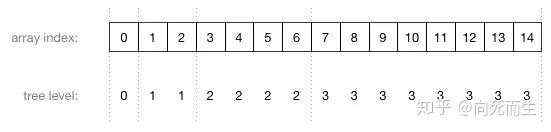
2.它通常用数组来实现。
- Parent(i) =i / 2,i 的父节点下标
- Left(i) = 2 * i ,i 的左子节点下标
- Right(i) = 2 * i +1,i 的右子节点下标
堆的二叉树表现形式堆的数组表现形式应用场景
- 合并有序小文件
- 高性能定时器
- 堆排序
- 查找第K大(小)元素
- 在朋友和面试官面前装逼
二、优先队列原理
准备好交换元素和比较大小的API,为了代码美观。
//存储堆中的元素private T[] items;//记录堆中元素的个数private int N; //判断堆中索引i处的元素是否小于索引j处的元素private boolean less(int i, int j) {return items[i].compareTo(items[j]) <0;}//交换堆中i索引和j索引处的值private void exch(int i, int j) {T tmp &#61; items[i];items[i] &#61; items[j];items[j] &#61; tmp;}
堆化算法
- 上浮算法&#xff1a;将一个数不断的与他的父节点进行对比交换&#xff0c;直到上浮到它该有的位置
//使用上浮算法&#xff0c;使索引k处的元素能在堆中处于一个正确的位置
- 下沉算法&#xff1a;将一个数不断的与他的子节点中较大&#xff08;较小&#xff09;者进行对比交换&#xff0c;直到下沉到它该有的位置
//使用下沉算法&#xff0c;使索引k处的元素能在堆中处于一个正确的位置private void sink(int k) {while (2 * k <&#61; N) {int min;//判断右节点是否超出限制&#xff0c;超出则与左节点比较if (2 * k &#43; 1 <&#61; N) {//比较左右子节点哪个更大&#xff08;小&#xff09;&#xff0c;与K交换if (less(2 * k, 2 * k &#43; 1)) {min &#61; 2 * k;} else {min &#61; 2 * k &#43; 1;}} else {min &#61; 2 * k;}//比较当前结点和较小值if (less(k,min)){break;}exch(k, min);k &#61; min;}}
排序算法
每次堆化后将头节点与最后一个数进行交换&#xff0c;下次与最后一个数减1交换&#xff0c;以此类推&#xff0c;直到有序。
//将最大&#xff08;最小&#xff09;元素与最后的元素交换&#xff0c;完成排序void heapSort(int[] arr) {for (int i &#61; arr.length; i > 0; i--) {buildHeap(arr, i);swap(arr, 0, i - 1);}}//将最后一个父节点依次往前面堆化&#xff0c;以此建立堆void buildHeap(int[] arr, int size) {int parent &#61; ((size - 1) - 1) / 2;for (int i &#61; parent; i >&#61; 0; i--) {heaping(arr, size, i);}}//将一个节点调整&#xff0c;使它在堆中处于正确位置void heaping(int[] arr, int size, int index) {if (index > size) return;int L &#61; 2 * index &#43; 1, R &#61; 2 * index &#43; 2;int max &#61; index;//判断左右节点和父节点哪个大&#xff0c;if (L
三、索引优先队列
为什么需要索引优先队列
解决优先队列没有办法通过索引访问已存在于优先队列中的对象的缺陷。
原理
以时间换空间&#xff0c;利用两个辅助数组来维护优先队列。
实现
- 0.定义一个items来保存元素&#xff0c;这样就可以通过update(int index,T t)方法来修改元素
//存储堆中的元素private T[] items;//记录堆中元素的个数private int N;//判断堆中索引i处的元素是否小于索引j处的元素private boolean less(int i, int j) {return items[pq[i]].compareTo(items[pq[j]]) <0;}//交换堆中i索引和j索引处的值private void exch(int i, int j) {int tmp &#61; pq[i];pq[i] &#61; pq[j];pq[j] &#61; tmp;qp[pq[i]] &#61; i;qp[pq[j]] &#61; j;}
- 1.定义一个pq保存每个元素在items中的索引&#xff0c;这个数组用来保持堆有序。
//保存每个元素在items中的索引&#xff0c;需要保持堆有序private int[] pq;
但如果仅仅只是定义一个数组的话&#xff0c;我们需要修改第N个元素时候&#xff0c;无法快速得知第N个元素在pq中的位置&#xff0c;就无法在常数级别的时间复杂度内进行修改。
- 2.定义一个qp数组为pq的逆序&#xff0c;pq的值作为索引&#xff0c;pq的索引作为值。这个数组用来保存items中第N个元素在pq中的位置。
//为pq的逆序&#xff0c;pq的值作为索引&#xff0c;pq的索引作为值private int[] qp;
- 3.在增删改的时候利用两个数组在O(1)的时间内更新元素。
//删除索引i关联的元素public void delete(int i) {int del &#61; pq[i];//更新qpqp[del] &#61; -1;//更新itemsitems[del] &#61; null;//将i与N在pq中进行位置交换exch(i, N);//把要删除的&#61;-1&#xff0c;表示删除pq[N] &#61; -1;N--;//调整新堆的位置,维持堆有序sink(i);swim(i);}//把与索引i关联的元素修改为为tpublic void changeItem(int i, T t) {//修改items中i的元素items[i] &#61; t;//通过qp找到i在堆中的位置int heapIndex &#61; qp[i];//堆pq中i进行上浮下移调整sink(heapIndex);swim(heapIndex);}//往堆中插入一个元素public void insert(int i, T t) {if (contains(i)) return;N&#43;&#43;;items[i] &#61; t;pq[N] &#61; i;qp[i] &#61; N;//保持pq堆有序swim(N);}//删除堆中最小的元素,并返回这个最小元素public T delMin() {int min &#61; pq[1];T minObj&#61;items[min];//更新qpqp[min] &#61; -1;//更新itemsitems[min] &#61; null;exch(1, N);pq[N] &#61; -1;N--;sink(1);return minObj;}









 京公网安备 11010802041100号
京公网安备 11010802041100号