作者:每天洗脸的小媳妇_853 | 来源:互联网 | 2023-09-06 20:43
目录
1、二叉堆
2、堆排序
3、代码
4、应用场景
1、二叉堆
二叉堆是一种特殊的堆,二叉堆是完全二元树(二叉树)或者是近似完全二元树(二叉树)。二叉堆有两种:最大堆和最小堆。最大堆:父结点的键值总是大于或等于任何一个子节点的键值;最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
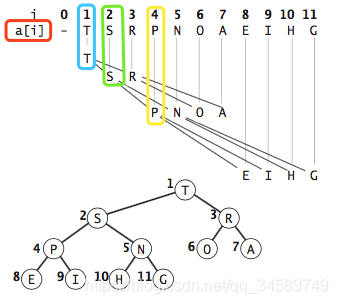
二叉堆一般用数组来表示。如果根节点在数组中的位置是1,第n个位置的子节点分别在2n和 2n+1。因此,第1个位置的子节点在2和3,第2个位置的子节点在4和5。以此类推。这种基于1的数组存储方式便于寻找父节点和子节点。
下图中a[1]的子结点就是a[2]和a[3].
2、堆排序
堆排序就是利用了二叉堆中的最大堆。即每个父结点(数组中下标k),都要大于等于它的子结点(数组中下标2k和2k+1)。
堆排序的步骤:1、对于一个无序数组a,先将它构建成最大堆。这时候二叉堆的根节点就是数组中最大的那个元素。
2、然后我们把最大的根节点拿出来放在该数组中末尾。
3、将剩下的元素再构建成最大堆,得到第二大元素,放在第一大元素的前面。
4、不断循环。。。。。。。。。。。。。。。。类似冒泡排序的思想,每次先把最大的元素拿出来放在末尾。
3、代码
public class Heap {public static void sort(double[] a){/*** 构建二叉堆的最大堆* 为什么从N/2的位置开始构建?* 因为 N/2的子结点就是N,在构建二叉堆的时候,我们会将父结点和子结点比较,* 如果子结点比父结点大,那么我们会将子结点换到父结点的位置,如果从比N/2大* 的地方进行构建,后面就没有子结点可以和它比较了。*/int N=a.length;for (int k=N/2;k>=1;--k){sink(a,k,N);}//不断拿出二叉堆的最大元素,放在数组的末尾,然后将剩下的元素构建成最大堆while(N>1){exch(a,1,N--);sink(a,1,N);}}/*** 将下标为k的元素,不断和它子结点(2k)比较* 如果比自己子结点小,就把子结点换上来,否则就变成了最大堆(父结点大于等于子结点)*/private static void sink(double[] a, int k, int N ) {while (2*k}
4、应用场景
堆排序在排序复杂性的研究中有着重要的地位, 因为它是我们所知的唯一能够同时最优地利用空间和时间的方法——在最坏的情况下它也能保证使 用~2NlgN次比较和恒定的额外空间。
当空间十分紧张的时候(例如在嵌入式系统或低成本的移动设 备中)它很流行,因为它只用几行就能实现(甚至机器码也是)较好的性能。但现代系统的许多应用 很少使用它,因为它无法利用缓存。数组元素很少和相邻的其他元素进行比较,因此缓存未命中的次 数要远远高于大多数比较都在相邻元素间进行的算法,如快速排序、归并排序,甚至是希尔排序。

![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)








 京公网安备 11010802041100号
京公网安备 11010802041100号