Third Time’s the Charm? Image and Video Editing with StyleGAN3
author
Yuval Alaluf
Link
论文地址
Code
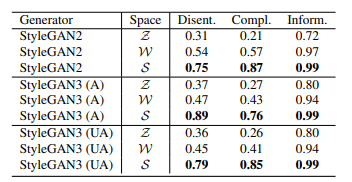
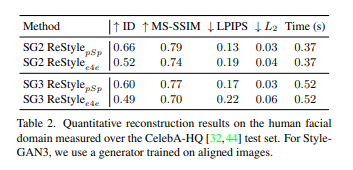
StyleGAN is arguably one of the most intriguing and well-studied generative models, demonstrating impressive performance in image generation, inversion, and manipulation. In this work, we explore the recent StyleGAN3 architecture, compare it to its predecessor, and investigate its unique advantages, as well as drawbacks. In particular, we demonstrate that while StyleGAN3 can be trained on unaligned data, one can still use aligned data for training, without hindering the ability to generate unaligned imagery. Next, our analysis of the disentanglement of the different latent spaces of StyleGAN3 indicates that the commonly used W/W+ spaces are more entangled than their StyleGAN2 counterparts, underscoring the benefits of using the StyleSpace for fine-grained editing. Considering image inversion, we observe that existing encoder-based techniques struggle when trained on unaligned data. We therefore propose an encoding scheme trained solely on aligned data, yet can still invert unaligned images. Finally, we introduce a novel video inversion and editing workflow that leverages the capabilities of a fine-tuned StyleGAN3 generator to reduce texture sticking and expand the field of view of the edited video.
在mapping network部分,并无变化,通过全连接网络将初始latent code z ~N(0,1) [512] 转换成w,并加入可学习的latent space W。
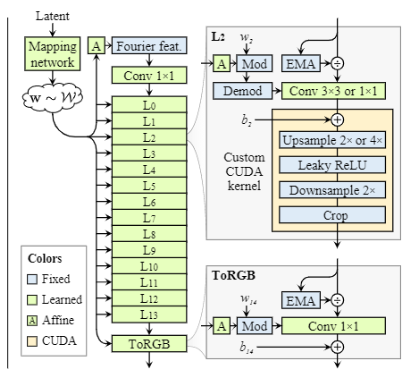
与Stylegan2相比,Stylegan3的synthesis network由固定数量的卷积层构成,与输出图像分辨率无关。Stylegan2中的constant 4*4被傅里叶特征(Fourier feat)取代,其中四个参数(sin a , cos a , x , y)通过学习仿射层从w0获取。在剩下的层中,每个wi被送入一个独立的学习仿射层,产生的modulation factors用来调整卷积核权重。
在视频传输领域,MP4虽然常见,但在直播场景中直接使用MP4格式存在诸多问题。例如,MP4文件的头部信息(如ftyp、moov)较大,导致初始加载时间较长,影响用户体验。相比之下,HLS(HTTP Live Streaming)协议及其M3U8格式更具优势。HLS通过将视频切分成多个小片段,并生成一个M3U8播放列表文件,实现低延迟和高稳定性。本文详细介绍了如何将TS文件转换为M3U8直播流,包括技术原理和具体操作步骤,帮助读者更好地理解和应用这一技术。 ...
[详细]














 京公网安备 11010802041100号
京公网安备 11010802041100号