作者:yan | 来源:互联网 | 2023-07-09 13:02
Abstract卷积神经网络(convolutionalneuralnetworks,CNNs)由于具有良好的局部上下文建模能力,已被证明是HS图像分类中一个强大的特
Abstract 卷积神经网络(convolutional neural networks, CNNs)由于具有良好的局部上下文建模能力,已被证明是HS图像分类中一个强大的特征提取器。然而,由于其固有的网络骨干网的限制,**cnn不能很好地挖掘和表示光谱特征的序列属性**。
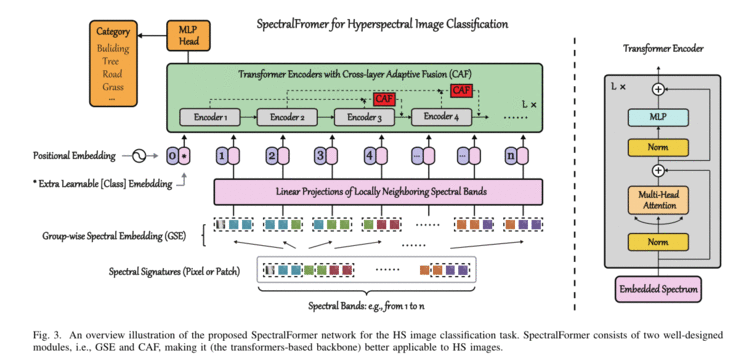
I. INTRODUCTION 为了解决这个问题,我们从变压器的顺序角度重新思考HS图像分类,并提出了一种新的骨干网称为SpectralFormer。除了在经典的变压器中采用band-wise表示外,SpectralFormer还能够从HS图像的相邻波段学习光谱局部序列信息 ,从而产生组内(group-wise)光谱嵌入。更重要的是,为了减少有价值信息在分层传播过程中丢失的可能性,我们设计了一种跨层跳过连接 ,通过自适应学习融合跨层的“软”残差,将类记忆组件从浅层传递到深层。值得注意的是,提出的SpectralFormer是一个高度灵活的骨干网,它可以适用于像素(pixel)和小块(patch)输入 。
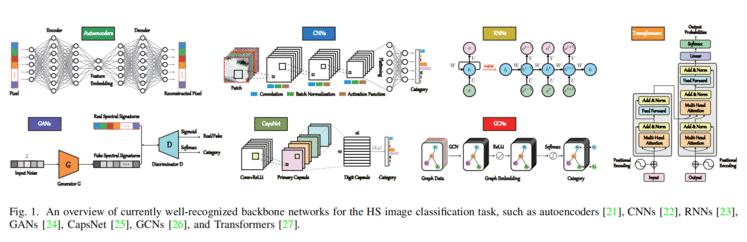
这些骨干网络及其变体能够获得很有希望的分类结果,但它们在光谱序列信息的表征(特别是在捕获沿光谱维数的细微光谱差异方面)的能力仍然不足 。图1给出了HS图像分类任务中这些最先进的骨干网的概述插图。具体的局限性 大致可以总结如下。
CNN作为一种主流的主干架构,在从HS图像中提取空间结构信息和局部上下文信息 方面显示出强大的能力。然而,一方面,cnn很难很好地捕获序列属性,特别是中期和长期依赖关系 。 另一方面,CNN 过于关注空间内容信息,从而在频谱上扭曲了学习特征中的顺序信息 。 RNN是为序列数据设计的,序列数据从HS图像中循序渐进地学习光谱特征 。这种模式对谱带的阶数依赖性很大,容易产生梯度消失 ,因此很难学习长期依赖关系 [30]。这可能进一步导致难以捕捉时间序列中显著的光谱变化。更重要的是,在真实的HS图像场景中,通常有大量的HS样本(或像素)可用,但RNNs不能并行训练模型 ,限制了实际应用中的分类性能。 对于其他主干网络,如GANs、CapsNet、GCNs,尽管它们在学习光谱表示(如鲁棒性、等价性、样本之间的远程相关性)方面都有各自的优势,但有一点是相同的,即它们几乎都无法有效地对顺序信息建模 。即光谱信息利用不足 (这是利用HS数据进行精细土地覆被分类或制图的关键瓶颈)。 众所周知,Transformer中的自注意块能够通过位置编码的方式捕获全局序列信息 。然而,变压器也存在一些缺陷,阻碍了其性能的进一步提高。例如,
Transformer在解决频谱特征的长期依赖性问题上表现出色,但它们失去了捕捉局部上下文或语义特征的能力 (参见cnn或rnn); Skip connection 在Transformer中起着至关重要的作用。这可以通过使用 “残差”来更好地传播梯度或增强“记忆”来减少遗忘或丢失关键信息来很好地解释 。但不幸的是,简单的附加跳过连接操作只发生在每个Transformer块内,削弱了不同层或块之间的连接性 。SpectralFormer能够在每个编码位置从多个相邻波段学习局部光谱表示 ,而不是单个波段(在原始变压器中)。此外,SpectralFormer 设计了一个跨层跳过连接 ,通过自适应学习融合它们的“软”残差,逐步将类似记忆的组件从浅层传递到深层。本文的主要贡献如下:
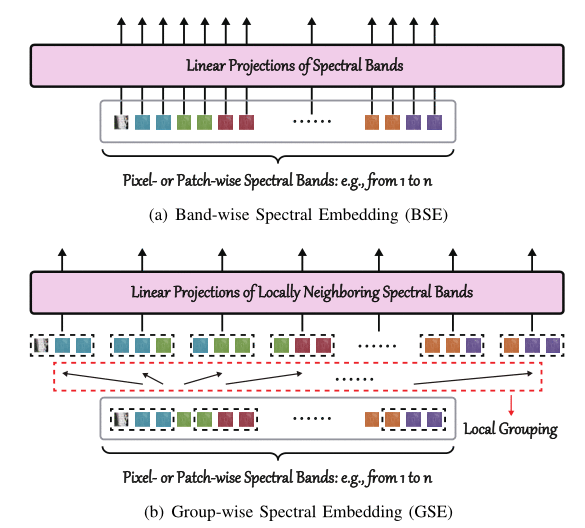
设计了两个简单但有效的模块,即组态光谱嵌入(GSE)和跨层自适应融合(CAF),分别学习局部细节的光谱表示和从浅层到深层传递类记忆成分 。 II. SPECTRALFORMER Group-wise Spectral Embedding (GSE)
we propose to learn group-wise spectral embeddings,i.e., GSE, instead of band-wise input and representations.
Cross-layer Adaptive Fusion (CAF)
Skip connection (SC)机制已被证明是一种有效的深度网络学习策略,可以增强层间的信息交换,减少网络学习过程中的信息丢失。然而,值得注意的是,短SC的信息“记忆”能力仍然有限 ,而长SC由于高、低层次特征之间的巨大差距,往往产生不充分的融合。这也是变压器存在的关键问题,对变压器的结构设计提出了新的挑战。为此,我们在SpectralFormer中设计了一个中等范围的SC来自适应地学习跨层特征融合(即CAF,见图5)。仅跳跃一个encoder层 。(因为4层或5层的浅网络规模较小,无法添加多个CAF模块)。Spatial-Spectral SpectralFormer
除了基于像素的HS图像分类,我们同样研究了基于patch的输入(受cnn启发),得出空间-光谱的SpectralFormer版本,即基于patch的SpectralFormer。与cnn直接输入一个3-D patch cube不同,我们将每个波段的2-D patch展开为相应的1-D矢量表示 。
给定一个3-D立方体X∈Rm×w×hX∈R^{m×w×h} X ∈ R m × w × h (w和h是patch的宽度和长度)(w和h是patch的宽度和长度) ( w 和 h 是 p a t c h 的 宽 度 和 长 度 ) X=[x1,...,xi,...,xm],X = [x_1, ..., x_i, ..., x_m], X = [ x 1 , . . . , x i , . . . , x m ] , xi∈Rwh×1x_i∈R^{wh×1} x i ∈ R w h × 1 频谱序列信息,同时考虑了空间上下文信息 。
CONCLUSION HS图像通常被收集(或表示)为一个具有空间光谱信息的数据立方体,通常可以认为是 沿着光谱维度的数据序列 。与主要关注上下文信息建模的cnn不同,transformer已被证明是一种强大的架构,可以在全球范围内描述顺序属性。然而,传统的基于变压器的视觉网络,如ViT,在处理类hs数据时,不可避免地会出现性能下降的问题。这可能可以很好地解释,因为 ViT无法模拟局部详细的光谱差异 ,并有效地传递“内存”类组件(从浅层到深层)。为此,本文提出了一种新的基于变压器的骨干网,称为SpectralFormer,它更专注于光谱信息的提取 。
在未来,我们将通过使用更先进的技术,如注意力、自我监督学习,进一步改进基于Transformer的架构,使其更适用于HS图像分类任务,并试图建立一个 轻量级的基于变压器的网络,以降低网络的复杂性 ,同时保持其性能。此外,我们还希望将光谱波段的更多物理特征和HS图像的先验知识嵌入 到提议的框架中,从而产生更多可解释的深层模型。此外,CAF模块中 跳过和连接编码器的数量可能是提高SpectralFormer分类性能的一个重要因素,在今后的工作中应予以重视。









 京公网安备 11010802041100号
京公网安备 11010802041100号