作者:aaaaaa师太_667 | 来源:互联网 | 2023-09-23 08:12
本文由编程笔记#小编为大家整理,主要介绍了SparkRDD相关的知识,希望对你有一定的参考价值。RDD概述RDD:弹性分布式数据集,初学时,可以把RDD看做是一种集合
本文由编程笔记#小编为大家整理,主要介绍了Spark RDD相关的知识,希望对你有一定的参考价值。
RDD概述
RDD:弹性分布式数据集,初学时,可以把RDD看做是一种集合类型(和Array,List类比)
RDD的特点:
①有容错性,即数据丢失是可以恢复的
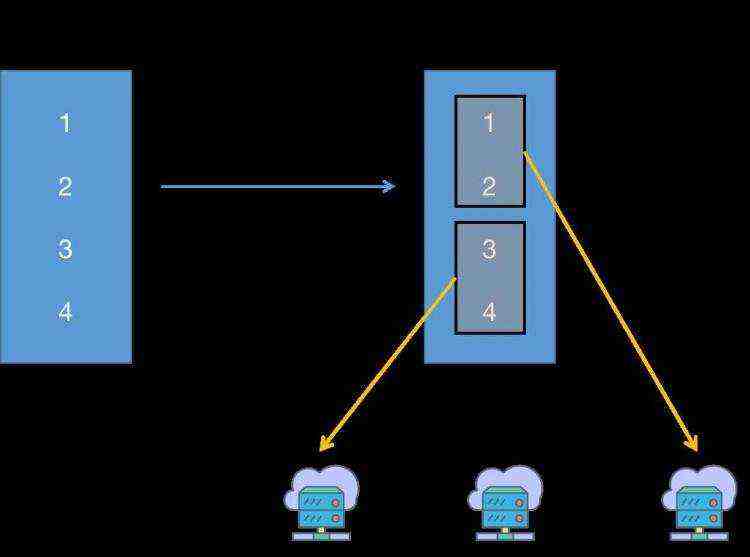
②有分区机制,可以并行的处理RDD数据
创建RDD的2种方式:
①将一个普通的集合类型(Array或List)
②通过Spark读取外部存储文件,将文件数据转变为RDD。可以从本地磁盘读取,也可以从HDFS读取
RDD的分区机制目的:可以分布式的计算RDD的数据集,底层可以确保分区数据的负载均衡状态

Spark单机模式启动
在bin目录下执行:sh spark-shell --master=local
1.sc是SparkContext的别名对象,用于操作spark的入口对象,通过sc可以创建RDD,广播变量,此外sc用于负载job任务的分配和监控
2.创建RDD的方法:
①sc.parallelize(普通集合,分区数量)
②sc.makeRDD(普通集合,分区数量)
3.关于RDD分区的相关方法
①rdd.partitions.size 查看分区数量
②rdd.glom.collect 查看分区数据
4.创建RDD的两种途径:
①将一个普通集合转变为RDD
②读取外部文件,转变为RDD :
方法: sc.textFile(路径,分区数)
补充:file:// 本地文件协议 => sc.textFile("file:///home/words.txt",2)
hdfs://HDFS文件系统协议 => sc.textFile("hdfs://hadoop101:9000/words.txt",2)
RDD的操作函数
两类操作:
1.Transformation 变换操作:都是懒方法,即调用之后并没有马上执行
1.Action 执行操作:触发执行
案例:通过rdd实现统计文件中的单词数量,并输出到文件系统
本地:sc.textFile("/root/work/words.txt").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/root/work/wcresult")
hdfs:
val rdd = sc.textFile("hdfs://hadoop101:9000/words.txt",2)
val result = rdd.flatMap(_.split("")).map((_,1)).reduceByKey(_+_)
result.saveAsTextFile("hdfs://hadoop101:9000/wordresult")









 京公网安备 11010802041100号
京公网安备 11010802041100号