一句话理解Spark是什么
spark是一个基于内存计算的框架,是一种通用的大数据快速处理引擎。
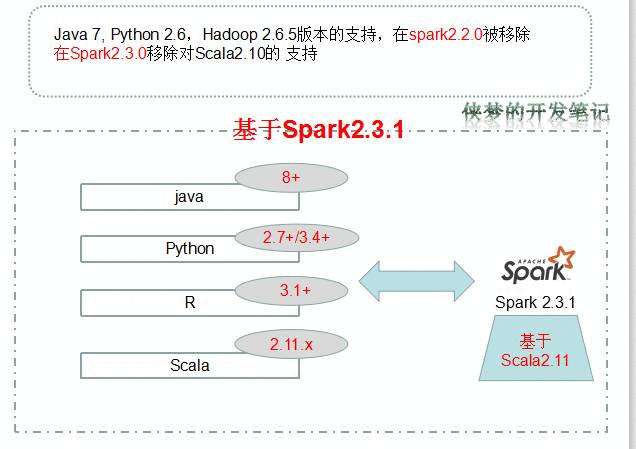
spark的版本支持情况
本文基于Spark2.3.1做阐述说明。
spark的特点
当然说它快,总要有个对比项,这里是基于和Hadoop的MapReduce来对比,由Spark是基于内存,所以它的计算速度可以达到MapReduce\Hive的数倍甚至数十倍高。
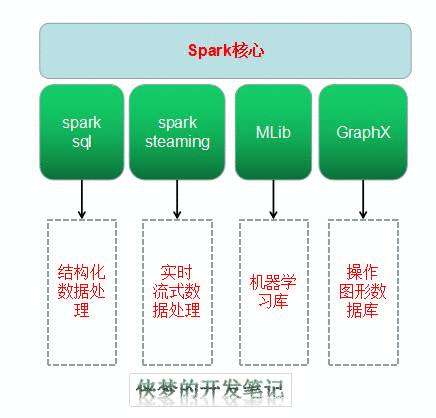
易用性强:提供了高阶的基于Java、Scala、Python和R语言的api,并且对图形化的执行引擎有所支持,其处理能力支持涵盖包括:Spark Sql,MLib和GrafphX、Spark Streaming等。
实时处理- Spark能够处理实时流数据。与只处理存储数据的MapReduce不同,Spark能够处理实时数据,所以能够产生即时结果。
与MapReduce中的包括Map和Reduce函数相比,Spark包含的远不止这些。Apache Spark由一组丰富的SQL查询、机器学习算法、复杂分析等组成。有了所有这些功能,在Spark的帮助下,可以更好地执行分析。
Spark SQL是Apache Spark处理结构化数据的模块。Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。
结构化数据的处理。
Apache Spark配备了一个丰富的机器学习库库。这个库包含了大量的机器学习算法: 分类、回归、聚类和协同过滤。它还包括用于构造、评估和调优ML管道的其他工具。所有这些功能都有助于在集群中扩展。
Spark还附带一个名为GraphX的库,用于操作图形数据库和执行计算。GraphX将ETL(提取、转换和加载)过程、探索性分析和迭代图计算统一到一个系统中。
MapReduce及其不足
在出现Spark之前,MapReduce很流行,它是一个弹性的分布式处理框架。
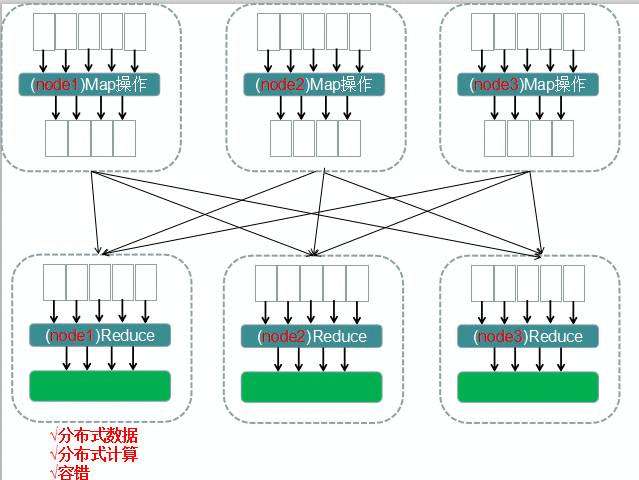
包含:
当数据上传到集群中后,它会被分割成数据块,分布在各个节点中,并在集群中复制。
通过指定一个map函数,来生成键值的映射,同样指定一个reduce函数,来合并在中间过程操作中生成的一系列中间值。这些操作在集群中会自动的并行化。
数据的映射过程,在每个数据节点上执行。数据源就是节点上切分到的分布式的数据文件。
简单了解MapReduce的特点后,我们来看看他有什么不足之处。
首先,MapReduce只提供两步操作,既是Map和reduce操作。
在mapreduce中数据是键值对的形式存在,在spark中是RDD数据结构存在。
RDD是什么
RDD(Resilient Distributed Datasets )被称为弹性分布式数据集。
具有如下特点:
数据是分布在各个节点上的,所有的计算动作都是并行进行的。
这也是刚才提到的,MapReduce只有两步操作,而sprak可以进行很多步计算。
spark在处理完一个阶段后,可以继续处理多个阶段直至结束。
RDD一旦被创建就不能够修改,并且是容错的。为什么说是弹性的呢?
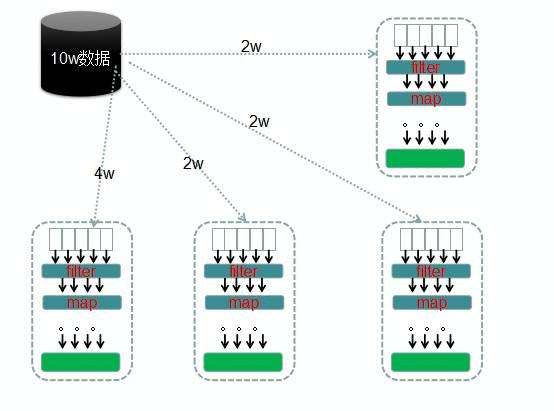
RDD的数据是被分区的,比如有10万条数据,那可能节点1有2万条,节点2有2万条,等等。每个分区数据默认都是放在内存中的,但是当节点的内存不足以支撑这么多数据量时,spark会将数据放一部分到磁盘中,这些操作都是对用户透明的。
parttion分区可以提高并行度,默认情况下Spark会自动决定一个RDD必须划分的分区数量,但是也可以在创建RDD时指定分区的数量。
那节点宕机怎么办呢?
节点上的rdd分区数据丢失,则他会从数据来源获取到数据后重新计算。
Spark开发之前
其实前面介绍的理论,都是为了最后引出RDD。所有的操作核心都和RDD有着密切的关系。
开发伊始,就需要定义第一个rdd的来源,可能是从hdfs、kafka或是文件甚至集合。
第二步,需要定义定义对rdd的操作(称为算子),
map/flatmap等,比mapreduce提供的map和reduce强悍太多太多了。
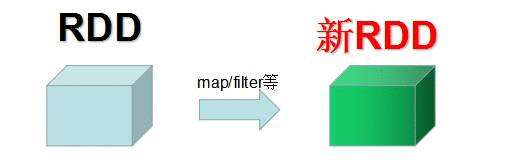
第一次计算完后,数据可能会到另外的节点上,变成一个新的rdd.
再次反复操作。
通过使用RDD 中的有向无环图(DAG)实现容错。
总结
本篇文章介绍了spark的基本概念和相关核心知识点的预梳理,主要包括:
- spark的特点。
- spark和mapreduce的区别。
- RDD的基本概念和及其转换。







![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号