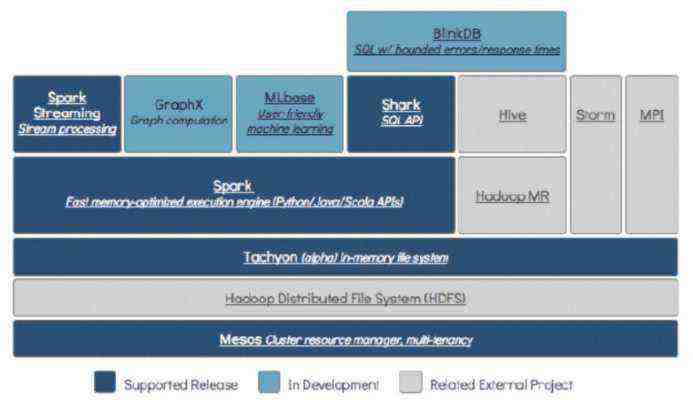
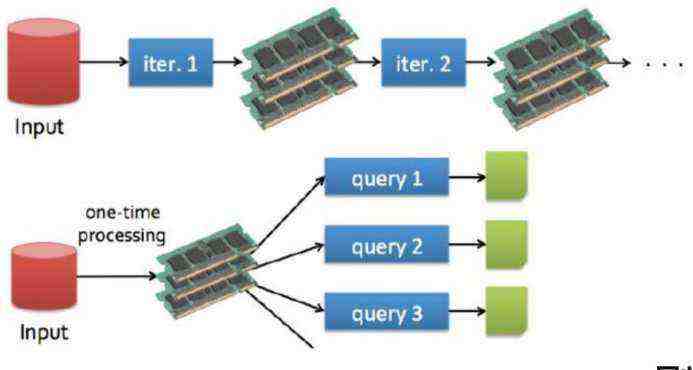
Ad-hoc Queries (即席查询)
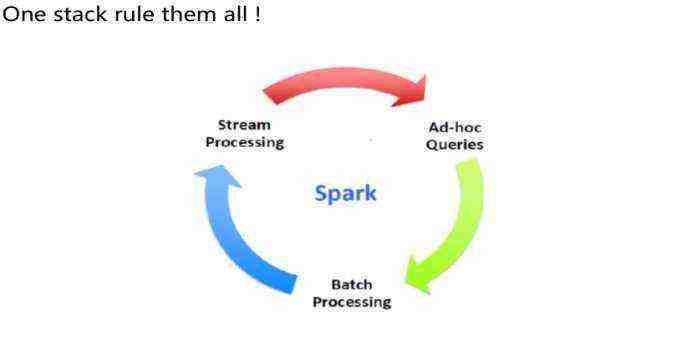
Spark 可以做到 流处理, 批处理 和即席查询一站式运作
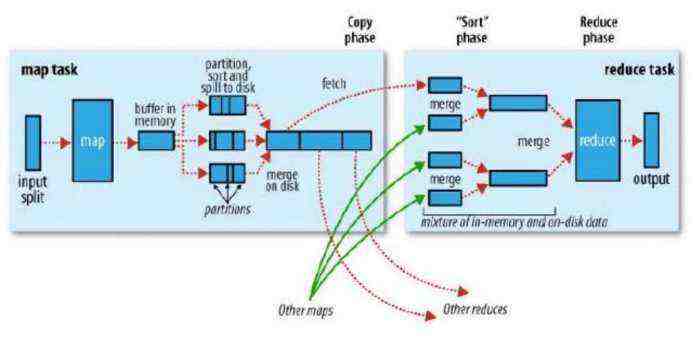
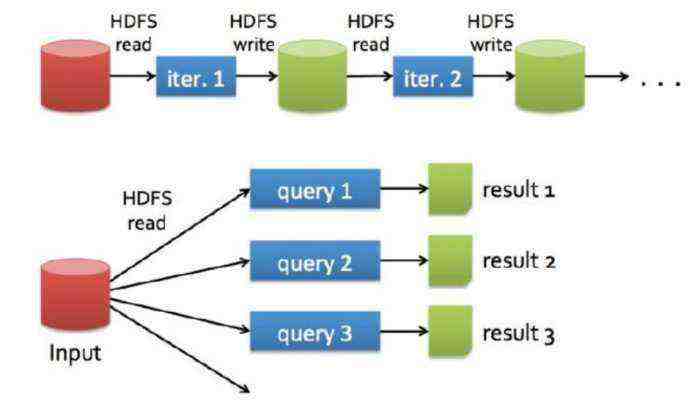
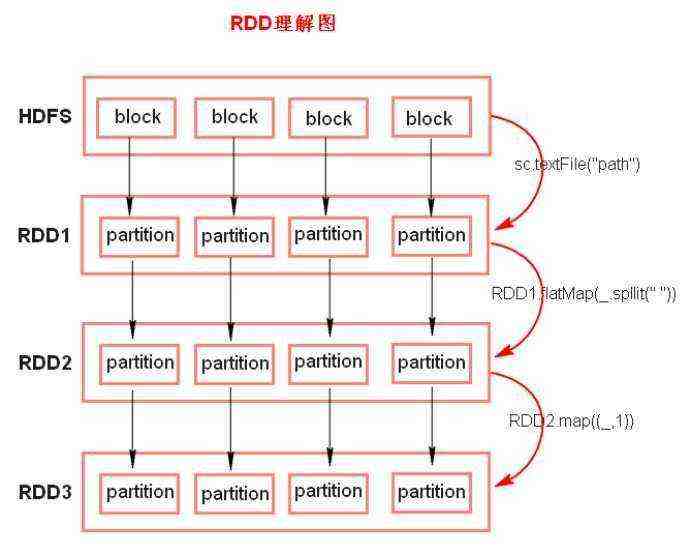
(1). RDD
Resilient Distributed DataSet 弹性分布式数据集。
RDD五大特性:
RDD理解图:
Lineage 血统

(2). Spark 任务执行原理

Driver 与 集群节点之间有频繁的通信
Driver 负责任务(tasks)的分发 和 结果的回收, 任务的调度。 如果 task 的计算结果非常大就不要回收了, 否则会造成OOM
Worder 是 Standalone 资源调度框架中资源管理的从节点, 也是JVM进程.
Master 是 Standalone 资源调度框架中资源管理的主节点, 也是JVM进程.
Driver 类比 ApplicationMaster 分发任务给Worker, 获取计算的结果
(3). Spark 代码流程
创建 SparkConf 对象
创建 SparkContext 对象
基于 Spark 的上下文创建一个RDD, 对 RDD进行处理
应用程序中要有Action类算子来触发 Transformation 类算子执行
关闭 Spark 上下文对象 SparkContext
(4). Transformations 转换算子

Transformation(转换) 类算子是一类算子, 如 map, flatMap, reduceByKey 等。
Transformation 算子是延迟执行的, 也可被称为懒加载执行的。
filter
map
将一个RDD中的每个数据项, 通过map中的函数映射变为一个新的元素。
特点: 输入一条, 输出一条数据。
flatMap
sample
reduceByKey
sortByKey/sortBy
(5). Action 行动算子
概念:
Action 行动算子, 如 foreach, collect, count 等。
Action 类算子是触发执行。
一个application应用程序中有几个 Action 类算子执行, 就有几个job运行。
Action 类算子
count
返回数据集中的元素数, 会在结果计算完成后回到 Driver 端
take(n)
first
等价于 take(1), 返回数据集中的第一个元素
foreach
collect
(6). 控制算子
可以指定持久化的级别。
最常用的是 Memory_Only 和 Memory_AND_DISK
持久化级别:
/**
* :: DeveloperApi ::
* Flags for controlling the storage of an RDD. Each StorageLevel records whether
* to use memory, or ExternalBlockStore, whether to drop the RDD to disk if it
* falls out of memory or ExternalBlockStore, whether to keep the data in memory in * a serialized format, and whetherto replicate the RDD partitions on multiple
* nodes.
* 控制 RDD 存储的 标签, 每个存储级别记录了 是否 使用内存,或额外的 块来存储; 是否 在 RDD * 内存 或 额外块 溢出时 将它 存储到磁盘; 是否将存储在内存中的数据 按指定格式 序列化;
* 是否将 RDD 的 分区 备份到几个节点上
*
* The [[org.apache.spark.storage.StorageLevel]] singleton object contains some
* static constants for commonly useful storage levels. To create your own storage * level object, use the factory method of the singleton object
* (`StorageLevel(...)`).
* StorageLevel 是一个包含了一些标识着常用的存储级别的静态常量的单例。
* 你可以通过使用该单例对象的工厂方法来自定义存储级别
*/
@DeveloperApi
class StorageLevel private(
// 是否使用磁盘存储
private var _useDisk: Boolean,
// 是否启用内存存储
private var _useMemory: Boolean,
// 是否使用堆外内存
private var _useOffHeap: Boolean,
// 是否不实用序列化... 这个有点绕...
private var _deserialized: Boolean,
// 默认备份为1,可设置
private var _replication: Int = 1)
extends Externalizable {
// TODO: Also add fields for caching priority, dataset ID, and flushing.
// 添加 用于 缓存优先级, 数据集 ID 和 内存清洗 的 域
private def this(flags: Int, replication: Int) {
this((flags & 8) != 0, (flags & 4) != 0, (flags & 2) != 0, (flags & 1) != 0, replication)
}
def this() = this(false, true, false, false) // For deserialization
def useDisk: Boolean = _useDisk
def useMemory: Boolean = _useMemory
def useOffHeap: Boolean = _useOffHeap
def deserialized: Boolean = _deserialized
def replication: Int = _replication
// 断言副本数是否小于 40, 不满足会报错
assert(replication <40, "Replication restricted to be less than 40 for calculating hash codes")
if (useOffHeap) {
// 使用序列化才能使用堆外内存
require(!deserialized, "Off-heap storage level does not support deserialized storage")
}
/**
*
* 内存模式
*/
private[spark] def memoryMode: MemoryMode = {
if (useOffHeap) MemoryMode.OFF_HEAP
else MemoryMode.ON_HEAP
}
/**
* 克隆, 创建了新对象, 是深拷贝
*/
override def clone(): StorageLevel = {
new StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication)
}
/**
*
* 重载equals方法
*/
override def equals(other: Any): Boolean = other match {
case s: StorageLevel =>
s.useDisk == useDisk &&
s.useMemory == useMemory &&
s.useOffHeap == useOffHeap &&
s.deserialized == deserialized &&
s.replication == replication
case _ =>
false
}
/**
* 判断是否有效
*/
def isValid: Boolean = (useMemory || useDisk) && (replication > 0)
def toInt: Int = {
var ret = 0
if (_useDisk) {
ret |= 8
}
if (_useMemory) {
ret |= 4
}
if (_useOffHeap) {
ret |= 2
}
if (_deserialized) {
ret |= 1
}
ret
}
// 额外的写出
override def writeExternal(out: ObjectOutput): Unit = Utils.tryOrIOException {
// writeByte: 写出为字节码
out.writeByte(toInt)
out.writeByte(_replication)
}
override def readExternal(in: ObjectInput): Unit = Utils.tryOrIOException {
val flags = in.readByte()
_useDisk = (flags & 8) != 0
_useMemory = (flags & 4) != 0
_useOffHeap = (flags & 2) != 0
_deserialized = (flags & 1) != 0
_replication = in.readByte()
}
// 读决定, 获取当前已缓存的等级
@throws(classOf[IOException])
private def readResolve(): Object = StorageLevel.getCachedStorageLevel(this)
override def toString: String = {
val disk = if (useDisk) "disk" else ""
val memory = if (useMemory) "memory" else ""
val heap = if (useOffHeap) "offheap" else ""
val deserialize = if (deserialized) "deserialized" else ""
val output =
Seq(disk, memory, heap, deserialize, s"$replication replicas").filter(_.nonEmpty)
s"StorageLevel(${output.mkString(", ")})"
}
override def hashCode(): Int = toInt * 41 + replication
def description: String = {
var result = ""
result += (if (useDisk) "Disk " else "")
if (useMemory) {
result += (if (useOffHeap) "Memory (off heap) " else "Memory ")
}
result += (if (deserialized) "Deserialized " else "Serialized ")
result += s"${replication}x Replicated"
result
}
}
/**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions * for creating new storage levels.
* 定义的可变存储级别以及 创建新存储级别的公用方法
*/
object StorageLevel {
// 5 个参数依次代表: _useDisk,_useMemory,_useOffHeap,_deserialized,_replication
// SER -> serialized 是否序列化; _2 -> 使用副本数
val NOnE= new StorageLevel(false, false, false, false)
val DISK_OnLY= new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_OnLY= new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
/**
* :: DeveloperApi ::
* Return the StorageLevel object with the specified name.
* 返回特定名称的存储级别对象
*/
@DeveloperApi
def fromString(s: String): StorageLevel = s match {
case "NONE" => NONE
case "DISK_ONLY" => DISK_ONLY
case "DISK_ONLY_2" => DISK_ONLY_2
case "MEMORY_ONLY" => MEMORY_ONLY
case "MEMORY_ONLY_2" => MEMORY_ONLY_2
case "MEMORY_ONLY_SER" => MEMORY_ONLY_SER
case "MEMORY_ONLY_SER_2" => MEMORY_ONLY_SER_2
case "MEMORY_AND_DISK" => MEMORY_AND_DISK
case "MEMORY_AND_DISK_2" => MEMORY_AND_DISK_2
case "MEMORY_AND_DISK_SER" => MEMORY_AND_DISK_SER
case "MEMORY_AND_DISK_SER_2" => MEMORY_AND_DISK_SER_2
case "OFF_HEAP" => OFF_HEAP
case _ => throw new IllegalArgumentException(s"Invalid StorageLevel: $s")
}
/**
* :: DeveloperApi ::
* Create a new StorageLevel object.
* 创建一个新的存储级别对象
*/
@DeveloperApi
def apply(
useDisk: Boolean,
useMemory: Boolean,
useOffHeap: Boolean,
deserialized: Boolean,
replication: Int): StorageLevel = {
getCachedStorageLevel(
new StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication))
}
/**
* :: DeveloperApi ::
* Create a new StorageLevel object without setting useOffHeap.
* 创建一个没有设置使用堆外内存的新存储级别对象
*/
@DeveloperApi
def apply(
useDisk: Boolean,
useMemory: Boolean,
deserialized: Boolean,
replication: Int = 1): StorageLevel = {
getCachedStorageLevel(new StorageLevel(useDisk, useMemory, false, deserialized, replication))
}
/**
* :: DeveloperApi ::
* Create a new StorageLevel object from its integer representation.
* 根据 标签 的 整形 代表参数 和 副本数 创建一个新的存储级别对象
*/
@DeveloperApi
def apply(flags: Int, replication: Int): StorageLevel = {
getCachedStorageLevel(new StorageLevel(flags, replication))
}
/**
* :: DeveloperApi ::
* Read StorageLevel object from ObjectInput stream.
* 从对象输入流中读取存储级别对象
*/
@DeveloperApi
def apply(in: ObjectInput): StorageLevel = {
val obj = new StorageLevel()
obj.readExternal(in)
getCachedStorageLevel(obj)
}
// 调用了 java 并发包的 ConcurrentHashMap, 将两个存储级别作为键值对传入 ConcurrentHashMap 初始化 该类的 storageLevelCache对象
private[spark] val storageLevelCache = new ConcurrentHashMap[StorageLevel, StorageLevel]()
// 从 storageLevelCache 中获取 存储级别对象
private[spark] def getCachedStorageLevel(level: StorageLevel): StorageLevel = {
storageLevelCache.putIfAbsent(level, level)
storageLevelCache.get(level)
}
}
checkpoint 将 RDD 持久化到磁盘, 还可以切断 RDD之间的依赖关系
checkpoint 的执行原理:
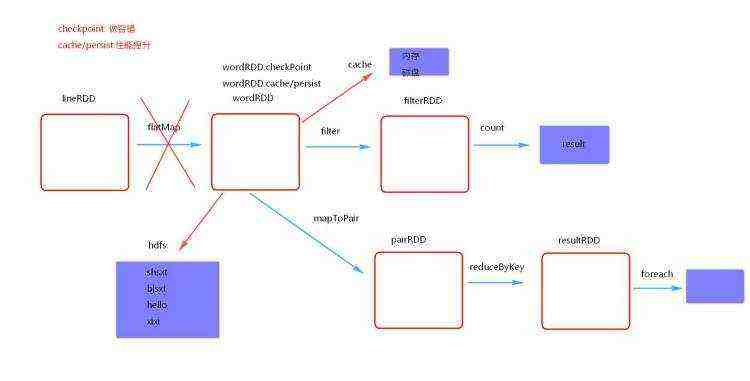
优化: 对 RDD 执行checkpoint之前, 最好对这个RDD先执行cache, 这样新启动的job只需要将内存中的数据拷贝到 HDFS 上就可以, 省去了重新计算的步骤。
随便写的一个xx练习, 可读性 == shit, 是在不想写wordCount了
package com.ronnie.scala
import java.io.StringReader
import au.com.bytecode.opencsv.CSVReader
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DataExtraction {
def main(args: Array[String]): Unit = {
val cOnf= new SparkConf()
conf.setMaster("local").setAppName("WC")
val sc = new SparkContext(conf)
val input: RDD[String] = sc.textFile("./resources/gpu.csv")
val result: RDD[Array[String]] = input.map { line =>
val reader = new CSVReader(new StringReader(line))
reader.readNext()
}
result.foreach(x => {
x.flatMap(_.split(" ")).foreach(_.split(" ").filter(y =>y.contains("580") ).foreach(_.split(" ").filter(x => x.equals("RX580")).foreach(println)))
})
}
}



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有