2019独角兽企业重金招聘Python工程师标准>>> 
为什么需要动态?
- Spark默认情况下粗粒度的,先分配好资源再计算。而Spark Streaming有高峰值和低峰值,但是他们需要的资源是不一样的,如果按照高峰值的角度的话,就会有大量的资源浪费。
- Spark Streaming不断的运行,对资源消耗和管理也是我们要考虑的因素。
- Spark Streaming资源动态调整的时候会面临挑战:Spark Streaming是按照Batch Duration运行的,Batch Duration需要很多资源,下一次Batch Duration就不需要那么多资源了,调整资源的时候还没调整完Batch Duration运行就已经过期了。这个时候调整时间间隔。
场景:
- 数据量变大,资源很少
- 数据量变小,资源很多
直接源码入手:
Spark Streaming资源动态申请
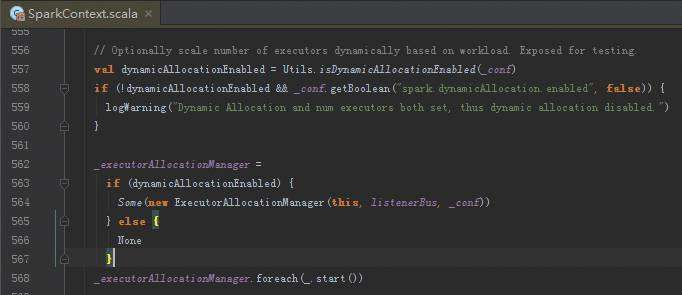
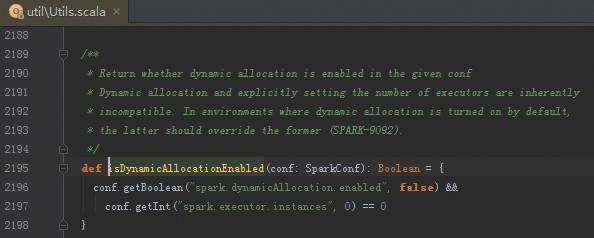
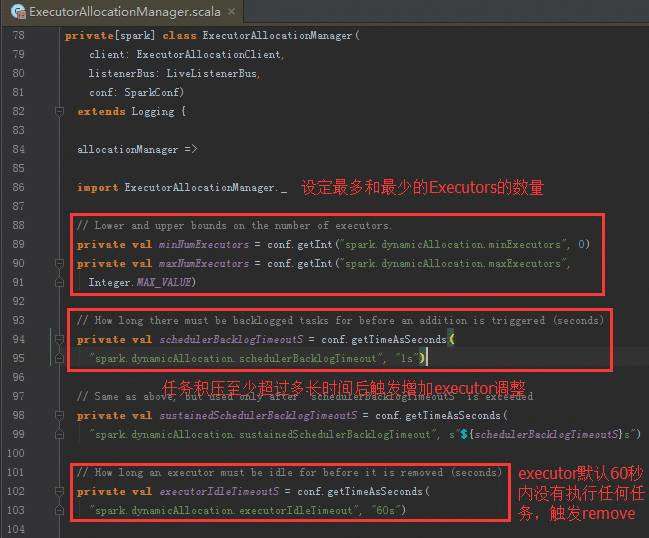

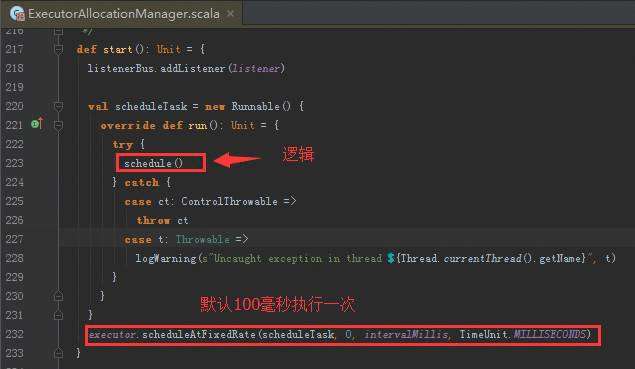
定时线程以固定频率来不断的扫描Executor,正在运行的Scheduler是要运行在不同的Executor中,需要动态的增加Executor或者减少Executor ,例如判断一个60秒为时间间隔的Executor一个任务都没有运行,就会把Executor删除掉。怎么会减少Executor,是因为当前应用程序中运行的Executor在Driver中会有数据结构对其保持引用,每次任务调度的时候都会循环遍历Executor的列表,然后查询列表的可用资源,根据这个类中的时钟会不断循环查看是否满足添加或者删除Executor的条件,如果满足添加或者删除的条件就触发Executor进行添加与删除。
从Spark Streaming的角度考虑,Spark Streaming要处理的动态资源调整就是Executor的资源动态调整,其最大的挑战是什么?
Spark Streaming是按照BachDuration的方式运行的,可能这个BachDuration需要很多资源,下一个又不用那么多资源,当前BachDuration的资源还没有等调整完成其运行已经过期了。
二、动态控制消费速率:
Spark Streaming弹性机制,可以查看流进来的数据是如何处理的,处理的速度之间的关系是否能够来得及进行处理,如果来不及进行处理的话,会动态的进行控制数据流进来的速度。
Spark Streaming本身有个rate的控制,这个控制一般可以使用手动的方式进行控制调整他的速度,手动控制是需要对Spark Streaming的处理速度有一种感知,根据BachDuration
流进来的数据进行控制其速度,可以调整BachDuration流入更多的数据或者更少的数据。
经典的论文,有时间了会把论文表达的信息加进来。








 京公网安备 11010802041100号
京公网安备 11010802041100号