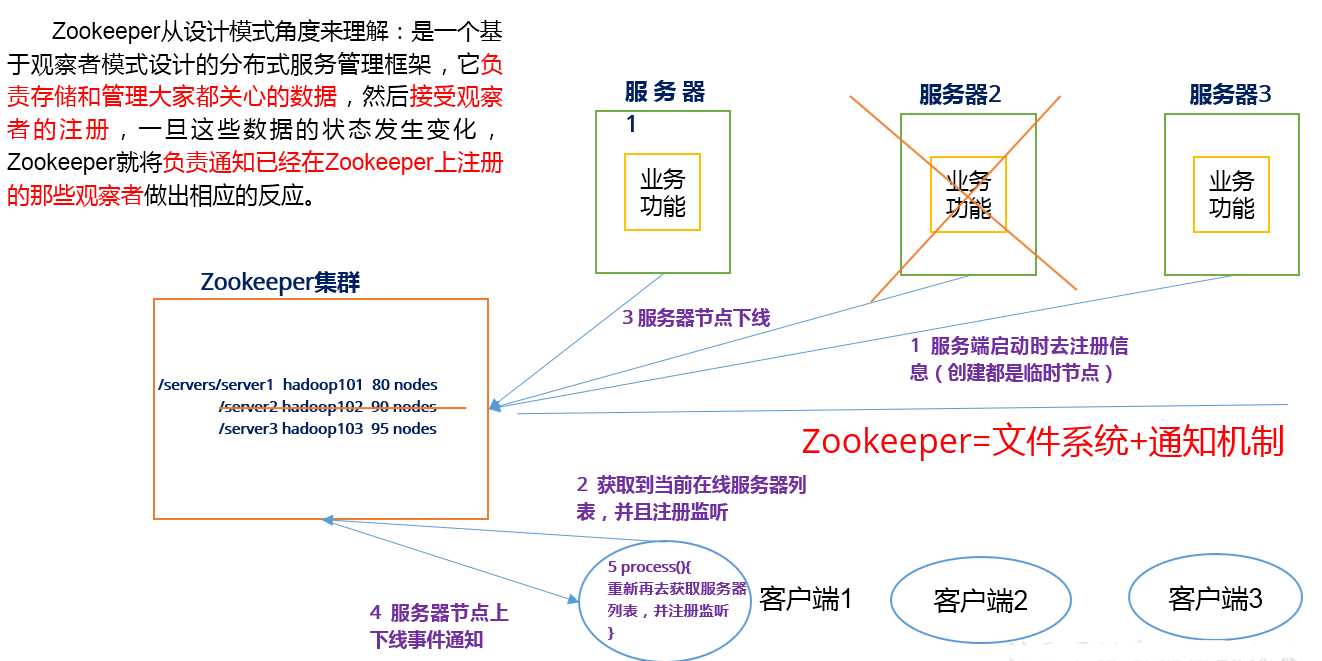
/** Spark
SQL源码分析系列文章*/
前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的。
那么基于以上存储结构,我们查询cache在jvm内的数据又是如何查询的,本文将揭示查询In-Memory Data的方式。
一、引子
本例使用hive console里查询cache后的src表。
select value from src
当我们将src表cache到了内存后,再次查询src,可以通过analyzed执行计划来观察内部调用。
即parse后,会形成InMemoryRelation结点,最后执行物理计划时,会调用InMemoryColumnarTableScan这个结点的方法。
如下:
scala> val exe = executePlan(sql("select value from src").queryExecution.analyzed)
14/09/26 10:30:26 INFO parse.ParseDriver: Parsing command: select value from src
14/09/26 10:30:26 INFO parse.ParseDriver: Parse Completed
exe: org.apache.spark.sql.hive.test.TestHive.QueryExecution =
== Parsed Logical Plan ==
Project [value#5]
InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)
== Analyzed Logical Plan ==
Project [value#5]
InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)
== Optimized Logical Plan ==
Project [value#5]
InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)
== Physical Plan ==
InMemoryColumnarTableScan [value#5], (InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)) //查询内存中表的入口
Code Generation: false
== RDD ==
二、InMemoryColumnarTableScan
InMemoryColumnarTableScan是Catalyst里的一个叶子结点,包含了要查询的attributes,和InMemoryRelation(封装了我们缓存的In-Columnar Storage数据结构)。
执行叶子节点,出发execute方法对内存数据进行查询。
1、查询时,调用InMemoryRelation,对其封装的内存数据结构的每个分区进行操作。
2、获取要请求的attributes,如上,查询请求的是src表的value属性。
3、根据目的查询表达式,来获取在对应存储结构中,请求列的index索引。
4、通过ColumnAccessor来对每个buffer进行访问,获取对应查询数据,并封装为Row对象返回。

private[sql] case class InMemoryColumnarTableScan(
attributes: Seq[Attribute],
relation: InMemoryRelation)
extends LeafNode {
override def output: Seq[Attribute] = attributes
override def execute() = {
relation.cachedColumnBuffers.mapPartitions { iterator =>
// Find the ordinals of the requested columns. If none are requested, use the first.
val requestedColumns = if (attributes.isEmpty) {
Seq(0)
} else {
attributes.map(a => relation.output.indexWhere(_.exprId == a.exprId)) //根据表达式exprId找出对应列的ByteBuffer的索引
}
iterator
.map(batch => requestedColumns.map(batch(_)).map(ColumnAccessor(_)))//根据索引取得对应请求列的ByteBuffer,并封装为ColumnAccessor。
.flatMap { columnAccessors =>
val nextRow = new GenericMutableRow(columnAccessors.length) //Row的长度
new Iterator[Row] {
override def next() = {
var i = 0
while (i
查询请求的列,如下:
scala> exe.optimizedPlan
res93: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [value#5]
InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)
scala> val relation = exe.optimizedPlan(1)
relation: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None)
scala> val request_relation = exe.executedPlan
request_relation: org.apache.spark.sql.execution.SparkPlan =
InMemoryColumnarTableScan [value#5], (InMemoryRelation [key#4,value#5], false, 1000, (HiveTableScan [key#4,value#5], (MetastoreRelation default, src, None), None))
scala> request_relation.output //请求的列,我们请求的只有value列
res95: Seq[org.apache.spark.sql.catalyst.expressions.Attribute] = ArrayBuffer(value#5)
scala> relation.output //默认保存在relation中的所有列
res96: Seq[org.apache.spark.sql.catalyst.expressions.Attribute] = ArrayBuffer(key#4, value#5)
scala> val attributes = request_relation.output
attributes: Seq[org.apache.spark.sql.catalyst.expressions.Attribute] = ArrayBuffer(value#5)
整个流程很简洁,关键步骤是第三步。根据ExprId来查找到,请求列的索引
attributes.map(a => relation.output.indexWhere(_.exprId == a.exprId))
//根据exprId找出对应ID
scala> val attr_index = attributes.map(a => relation.output.indexWhere(_.exprId == a.exprId))
attr_index: Seq[Int] = ArrayBuffer(1) //找到请求的列value的索引是1, 我们查询就从Index为1的bytebuffer中,请求数据
scala> relation.output.foreach(e=>println(e.exprId))
ExprId(4) //对应[key#4,value#5]
ExprId(5)
scala> request_relation.output.foreach(e=>println(e.exprId))
ExprId(5)
三、ColumnAccessor
ColumnAccessor对应每一种类型,类图如下:

最后返回一个新的迭代器:
new Iterator[Row] {
override def next() = {
var i = 0
while (i
四、总结
Spark SQL In-Memory Columnar Storage的查询相对来说还是比较简单的,其查询思想主要和存储的数据结构有关。
即存储时,按每列放到一个bytebuffer,形成一个bytebuffer数组。
查询时,根据请求列的exprId查找到上述数组的索引,然后使用ColumnAccessor对buffer中字段进行解析,最后封装为Row对象,返回。
——EOF——
原创文章,转载请注明出自:http://blog.csdn.net/oopsoom/article/details/39577419
Spark SQL 源码分析之 In-Memory Columnar Storage 之 in-memory query


![[c++基础]STL](https://img.php1.cn/3c972/1edc8/c5a/a04ecc977fd8ed28.jpeg)




![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号