Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~
目录
1.TF-IDF
2.word2vec
3.特征缩放
4.归一化
5.ChiSq选择器
6.元素智能乘积
本文采用的组件版本为:Ubuntu 19.10、Jdk 1.8.0_241、Scala 2.11.12、Hadoop 3.2.1、Spark 2.4.5,老规矩先开启一系列Hadoop、Spark服务与Spark-shell窗口:
1.TF-IDF
术语频率逆文档频率(TF-IDF)是一种特征向量化方法,广泛用于文本挖掘中,以反映术语对语料库中文档的重要性。用t表示项,用d表示文档,用D表示语料库。术语频率TF(t,d)是术语t在文档d中出现的次数,而文档频率DF(t,D)是包含术语t的文档数。
如果术语经常出现在整个语料库中,则表示该术语不包含有关特定文档的特殊信息。反向文档频率是一个术语提供多少信息的数字度量:
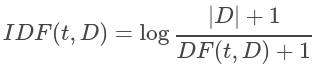
| D | 是语料库中文档的总数。由于使用对数,因此如果一个术语出现在所有文档中,则其IDF值将变为0。请注意,应用了平滑术语以避免对主体外的术语除以零。TF-IDF度量只是TF和IDF的乘积:
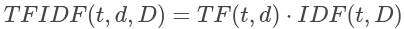
术语频率和文档频率的定义有多种变体。在spark.mllib中,我们将TF和IDF分开以使其具有灵活性。TF和IDF在HashingTF和IDF中实现。HashingTF将RDD [Iterable [_]]作为输入。每个记录可以是字符串或其他类型的迭代。
import org.apache.spark.mllib.feature.{HashingTF, IDF}
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.rdd.RDD
// 加载文档
val documents: RDD[Seq[String]] = sc.textFile("data/mllib/kmeans_data.txt").map(_.split(" ").toSeq)
val hashingTF = new HashingTF()
val tf: RDD[Vector] = hashingTF.transform(documents)
// 应用HashingTF只需要一次传递,应用IDF需要两次传递
// 首先计算IDF向量,其次通过IDF缩放项频率。
tf.cache()
val idf = new IDF().fit(tf)
val tfidf: RDD[Vector] = idf.transform(tf)
// spark.mllib IDF实现提供了一个选项,用于忽略少于最少数量的文档中出现的术语。在这种情况下,这些术语的IDF设置为0。
//可以通过将minDocFreq值传递给IDF构造函数来使用此功能。
val idfIgnore = new IDF(minDocFreq = 2).fit(tf)
val tfidfIgnore: RDD[Vector] = idfIgnore.transform(tf)
2.word2vec
Word2Vec计算单词的分布式矢量表示。分布式表示的主要优点是向量空间中相似的词很接近,这使得对新颖模式的泛化更加容易,模型估计也更加可靠。分布式矢量表示被证明在许多自然语言处理应用程序中很有用,例如命名实体识别,歧义消除,解析,标记和机器翻译。
在Word2Vec的实现中,我们使用了跳过语法模型。跳过语法的训练目标是学习擅长在同一句子中预测其上下文的词向量表示。从数学上讲,给定一系列训练词w1,w2,…,wT,跳跃语法模型的目标是使平均对数似然性最大化
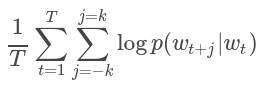
其中k是训练窗口的大小。在跳过语法模型中,每个单词w与两个向量uw和vw相关联,这两个向量分别是w作为单词和上下文的向量表示。给定单词wj正确预测单词wi的概率由softmax模型确定,该模型为
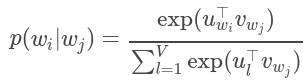
其中V是词汇量。具有softmax的跳过语法模型很昂贵,因为计算logp(wi | wj)的成本与V成正比,这很容易达到数百万个的数量级。为了加快Word2Vec的训练速度,我们使用了层次化softmax,将logp(wi | wj)的计算复杂度降低为O(log(V))
下面的示例演示如何加载文本文件,将其解析为Seq [String]的RDD,构造Word2Vec实例,然后使用输入数据拟合Word2VecModel。最后,我们显示指定单词的前40个同义词。要运行该示例,请首先下载text8数据并将其提取到您的首选目录中。在这里,我们假设提取的文件是text8,并且与运行spark shell的目录位于同一目录中。
import org.apache.spark.mllib.feature.{Word2Vec, Word2VecModel}
val input = sc.textFile("data/mllib/sample_lda_data.txt").map(line => line.split(" ").toSeq)
val word2vec = new Word2Vec()
val model = word2vec.fit(input)
val synonyms = model.findSynonyms("1", 5)
for((synonym, cosineSimilarity) <- synonyms) {println(s"$synonym $cosineSimilarity")
}
// Save and load model
model.save(sc, "myModelPath")
val sameModel &#61; Word2VecModel.load(sc, "myModelPath")
3.特征缩放
通过缩放到单位方差和/或使用训练集中样本上的列摘要统计信息来去除均值来对特征进行标准化。这是非常常见的预处理步骤。例如&#xff0c;当所有特征均具有单位方差和/或均值为零时&#xff0c;支持向量机的RBF内核或L1和L2正则化线性模型通常会更好地工作。
标准化可以提高优化过程中的收敛速度&#xff0c;并且还可以防止差异很大的特征在模型训练期间产生过大的影响。下面的示例演示了如何以libsvm格式加载数据集并标准化功能&#xff0c;以便新功能具有单位标准差和/或零均值。
import org.apache.spark.mllib.feature.{StandardScaler, StandardScalerModel}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
val data &#61; MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val scaler1 &#61; new StandardScaler().fit(data.map(x &#61;> x.features))
val scaler2 &#61; new StandardScaler(withMean &#61; true, withStd &#61; true).fit(data.map(x &#61;> x.features))
// scaler3是与scaler2相同的模型&#xff0c;并将产生相同的转换
val scaler3 &#61; new StandardScalerModel(scaler2.std, scaler2.mean)
// 是单位方差
val data1 &#61; data.map(x &#61;> (x.label, scaler1.transform(x.features)))
// data2将是单位方差和零均值。
val data2 &#61; data.map(x &#61;> (x.label, scaler2.transform(Vectors.dense(x.features.toArray))))
4.归一化
归一化将单个样本缩放为具有单位Lp范数。这是文本分类或聚类的常用操作。例如&#xff0c;两个L2归一化TF-IDF向量的点积是向量的余弦相似度。规范化器在构造函数中具有以下参数&#xff1a;p空间中的归一化&#xff0c;默认情况下p &#61; 2。
归一化实现了VectorTransformer&#xff0c;可以将规范化应用于Vector以产生转换后的Vector或在RDD [Vector]上产生转换的RDD [Vector]。请注意&#xff0c;如果输入范数为零&#xff0c;则它将返回输入向量。
下面的示例演示如何以libsvm格式加载数据集&#xff0c;并使用L2范数和L∞范数对特征进行归一化。
import org.apache.spark.mllib.feature.Normalizer
import org.apache.spark.mllib.util.MLUtils
val data &#61; MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val normalizer1 &#61; new Normalizer()
val normalizer2 &#61; new Normalizer(p &#61; Double.PositiveInfinity)
// data1中的每个样本都将使用$ L ^ 2 $范数进行归一化。
val data1 &#61; data.map(x &#61;> (x.label, normalizer1.transform(x.features)))
// data2中的每个样本都将使用$ L ^ \ infty $范数进行标准化。
val data2 &#61; data.map(x &#61;> (x.label, normalizer2.transform(x.features)))
5.ChiSq选择器
ChiSqSelector实现Chi-Squared特征选择。它对具有分类特征的标记数据进行操作。ChiSqSelector使用卡方独立性检验来决定选择哪些功能。它支持五种选择方法&#xff1a;numTopFeatures&#xff0c;percentile&#xff0c;fpr&#xff0c;fdr&#xff0c;fwe。
以下示例显示了ChiSqSelector的基本用法。所使用的数据集具有一个由灰度值组成的特征矩阵&#xff0c;每个值的灰度值从0到255不等。
import org.apache.spark.mllib.feature.ChiSqSelector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
val data &#61; MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
//由于ChiSqSelector需要分类特征&#xff0c;因此将数据离散化为16个相等的bin
//即使功能是双精度的&#xff0c;ChiSqSelector也会将每个唯一值都视为一个类别val discretizedData &#61; data.map { lp &#61;>LabeledPoint(lp.label, Vectors.dense(lp.features.toArray.map { x &#61;> (x / 16).floor }))
}
// 创建将选择692个特征中前50个特征的ChiSqSelector
val selector &#61; new ChiSqSelector(50)
// 创建ChiSqSelector模型&#xff08;选择功能&#xff09;
val transformer &#61; selector.fit(discretizedData)
// 从每个特征向量过滤前50个特征
val filteredData &#61; discretizedData.map { lp &#61;>LabeledPoint(lp.label, transformer.transform(lp.features))
}
6.元素智能乘积
ElementwiseProduct使用逐元素乘法将每个输入向量乘以提供的“权重”向量。换句话说&#xff0c;它通过标量乘子缩放数据集的每一列。这表示输入向量v和转换向量scaleVec之间的Hadamard乘积&#xff0c;以产生结果向量。将scalingVec表示为“ w”&#xff0c;此转换可以写为&#xff1a;
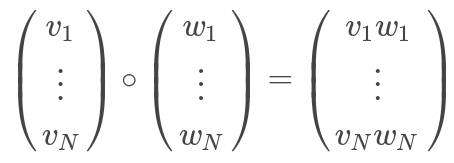
ElementwiseProduct在构造函数中具有参数scaleVec&#xff1a;转换向量。ElementwiseProduct实现VectorTransformer&#xff0c;可以将权重应用于Vector来生成转换后的Vector或在RDD [Vector]上生成转换后的RDD [Vector]。
下面的示例演示了如何使用转换向量值转换向量。
import org.apache.spark.mllib.feature.ElementwiseProduct
import org.apache.spark.mllib.linalg.Vectors
//创建一些矢量数据&#xff1b; 也适用于稀疏向量
val data &#61; sc.parallelize(Array(Vectors.dense(1.0, 2.0, 3.0), Vectors.dense(4.0, 5.0, 6.0)))
val transformingVector &#61; Vectors.dense(0.0, 1.0, 2.0)
val transformer &#61; new ElementwiseProduct(transformingVector)
//批处理变换和逐行变换给出相同的结果&#xff1a;
val transformedData &#61; transformer.transform(data)
val transformedData2 &#61; data.map(x &#61;> transformer.transform(x))
Spark 特征提取与转换的内容至此结束&#xff0c;有关Spark的基础文章可参考前文&#xff1a;
Spark MLlib分布式机器学习源码分析&#xff1a;矩阵向量
Spark MLlib分布式机器学习源码分析&#xff1a;基本统计
Spark MLlib分布式机器学习源码分析&#xff1a;线性模型
Spark MLlib分布式机器学习源码分析&#xff1a;朴素贝叶斯
Spark MLlib分布式机器学习源码分析&#xff1a;决策树算法
Spark MLlib分布式机器学习源码分析&#xff1a;集成树模型
Spark MLlib分布式机器学习源码分析&#xff1a;协同过滤
Spark MLlib分布式机器学习源码分析&#xff1a;K-means聚类
Spark MLlib分布式机器学习源码分析&#xff1a;隐式狄利克雷分布
Spark MLlib分布式机器学习源码分析&#xff1a;奇异值分解与主成分分析
参考链接&#xff1a;
http://spark.apache.org/docs/latest/mllib-feature-extraction.html
https://github.com/endymecy/spark-ml-source-analysis
历史推荐
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
爬虫实战&#xff1a;Selenium爬取京东商品
爬虫实战&#xff1a;豆瓣电影top250爬取
爬虫实战&#xff1a;Scrapy框架爬取QQ音乐

数据分析与挖掘
数据结构与算法
机器学习与大数据组件
欢迎关注&#xff0c;感谢“在看”&#xff0c;随缘稀罕~


一个赞&#xff0c;晚餐加鸡腿









 京公网安备 11010802041100号
京公网安备 11010802041100号